cardiffnlp/databench
收藏Hugging Face2025-08-06 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/cardiffnlp/databench
下载链接
链接失效反馈官方服务:
资源简介:
DataBench数据集包含65个真实世界的数据集,用于评估大语言模型(LLMs)在表格数据上的问答能力。这些数据集涵盖了多个领域,如商业、健康、旅行等,总共包含3,269,975行和1615列数据,并提供了1300个问题用于模型评估。每个数据集都包含处理后的数据、人工生成的问题集、样本数据以及附加信息。
The DataBench dataset contains 65 real-world datasets used to evaluate the question-answering capabilities of large language models (LLMs) on tabular data. These datasets cover various domains such as business, health, travel, etc., totaling 3,269,975 rows and 1615 columns, and provide 1300 questions for model evaluation. Each dataset includes processed data, a human-made set of questions, sample data, and additional information.
提供机构:
cardiffnlp
原始信息汇总
💾🏋️💾 DataBench 💾🏋️💾
数据集概述
DataBench 包含65个用于表格问答任务的真实世界数据集,总计3,269,975行和1615列,以及1300个问题。这些数据集用于评估大型语言模型在表格数据问答任务中的表现。
数据集列表
以下是数据集的详细列表,包括名称、行数、列数、领域和来源:
| 序号 | 名称 | 行数 | 列数 | 领域 | 来源 |
|---|---|---|---|---|---|
| 1 | Forbes | 2668 | 17 | 商业 | Forbes |
| 2 | Titanic | 887 | 8 | 旅行和地点 | Kaggle |
| 3 | Love | 373 | 35 | 社交网络和调查 | Graphext |
| 4 | Taxi | 100000 | 20 | 旅行和地点 | Kaggle |
| 5 | NYC Calls | 100000 | 46 | 商业 | City of New York |
| 6 | London Airbnbs | 75241 | 74 | 旅行和地点 | Kaggle |
| 7 | Fifa | 14620 | 59 | 体育和娱乐 | Kaggle |
| 8 | Tornados | 67558 | 14 | 健康 | Kaggle |
| 9 | Central Park | 56245 | 6 | 旅行和地点 | Kaggle |
| 10 | ECommerce Reviews | 23486 | 10 | 商业 | Kaggle |
| 11 | SF Police | 713107 | 35 | 社交网络和调查 | US Gov |
| 12 | Heart Failure | 918 | 12 | 健康 | Kaggle |
| 13 | Roller Coasters | 1087 | 56 | 体育和娱乐 | Kaggle |
| 14 | Madrid Airbnbs | 20776 | 75 | 旅行和地点 | Inside Airbnb |
| 15 | Food Names | 906 | 4 | 商业 | Data World |
| 16 | Holiday Package Sales | 4888 | 20 | 旅行和地点 | Kaggle |
| 17 | Hacker News | 9429 | 20 | 社交网络和调查 | Kaggle |
| 18 | Staff Satisfaction | 14999 | 11 | 商业 | Kaggle |
| 19 | Aircraft Accidents | 23519 | 23 | 健康 | Kaggle |
| 20 | Real Estate Madrid | 26026 | 59 | 商业 | Idealista |
| 21 | Telco Customer Churn | 7043 | 21 | 商业 | Kaggle |
| 22 | Airbnbs Listings NY | 37012 | 33 | 旅行和地点 | Kaggle |
| 23 | Climate in Madrid | 36858 | 26 | 旅行和地点 | AEMET |
| 24 | Salary Survey Spain 2018 | 216726 | 29 | 商业 | INE |
| 25 | Data Driven SEO | 62 | 5 | 商业 | Graphext |
| 26 | Predicting Wine Quality | 1599 | 12 | 商业 | Kaggle |
| 27 | Supermarket Sales | 1000 | 17 | 商业 | Kaggle |
| 28 | Predict Diabetes | 768 | 9 | 健康 | Kaggle |
| 29 | NYTimes World In 2021 | 52588 | 5 | 旅行和地点 | New York Times |
| 30 | Professionals Kaggle Survey | 19169 | 64 | 商业 | Kaggle |
| 31 | Trustpilot Reviews | 8020 | 6 | 商业 | TrustPilot |
| 32 | Delicatessen Customers | 2240 | 29 | 商业 | Kaggle |
| 33 | Employee Attrition | 14999 | 11 | 商业 | Kaggle(modified) |
| 34 | World Happiness Report 2020 | 153 | 20 | 社交网络和调查 | World Happiness |
| 35 | Billboard Lyrics | 5100 | 6 | 体育和娱乐 | Brown University |
| 36 | US Migrations 2012-2016 | 288300 | 9 | 社交网络和调查 | US Census |
| 37 | Ted Talks | 4005 | 19 | 社交网络和调查 | Kaggle |
| 38 | Stroke Likelihood | 5110 | 12 | 健康 | Kaggle |
| 39 | Happy Moments | 100535 | 11 | 社交网络和调查 | Kaggle |
| 40 | Speed Dating | 8378 | 123 | 社交网络和调查 | Kaggle |
| 41 | Airline Mentions X (former Twitter) | 14640 | 15 | 社交网络和调查 | X (former Twitter) |
| 42 | Predict Student Performance | 395 | 33 | 商业 | Kaggle |
| 43 | Loan Defaults | 83656 | 20 | 商业 | SBA |
| 44 | IMDb Movies | 85855 | 22 | 体育和娱乐 | Kaggle |
| 45 | Spotify Song Popularity | 21000 | 19 | 体育和娱乐 | Spotify |
| 46 | 120 Years Olympics | 271116 | 15 | 体育和娱乐 | Kaggle |
| 47 | Bank Customer Churn | 7088 | 15 | 商业 | Kaggle |
| 48 | Data Science Salary Data | 742 | 28 | 商业 | Kaggle |
| 49 | Boris Johnson UK PM Tweets | 3220 | 34 | 社交网络和调查 | X (former Twitter) |
| 50 | ING 2019 X Mentions | 7244 | 22 | 社交网络和调查 | X (former Twitter) |
| 51 | Pokemon Features | 1072 | 13 | 商业 | Kaggle |
| 52 | Professional Map | 1227 | 12 | 商业 | Kern et al, PNAS20 |
| 53 | Google Patents | 9999 | 20 | 商业 | BigQuery |
| 54 | Joe Biden Tweets | 491 | 34 | 社交网络和调查 | X (former Twitter) |
| 55 | German Loans | 1000 | 18 | 商业 | Kaggle |
| 56 | Emoji Diet | 58 | 35 | 健康 | Kaggle |
| 57 | Spain Survey 2015 | 20000 | 45 | 社交网络和调查 | CIS |
| 58 | US Polls 2020 | 3523 | 52 | 社交网络和调查 | Brandwatch |
| 59 | Second Hand Cars | 50000 | 21 | 商业 | DataMarket |
| 60 | Bakery Purchases | 20507 | 5 | 商业 | Kaggle |
| 61 | Disneyland Customer Reviews | 42656 | 6 | 旅行和地点 | Kaggle |
| 62 | Trump Tweets | 15039 | 20 | 社交网络和调查 | X (former Twitter) |
| 63 | Influencers | 1039 | 14 | 社交网络和调查 | X (former Twitter) |
| 64 | Clustering Zoo Animals | 101 | 18 | 健康 | Kaggle |
| 65 | RFM Analysis | 541909 | 8 | 商业 | UCI ML |
文件结构
每个数据集文件夹包含以下文件:
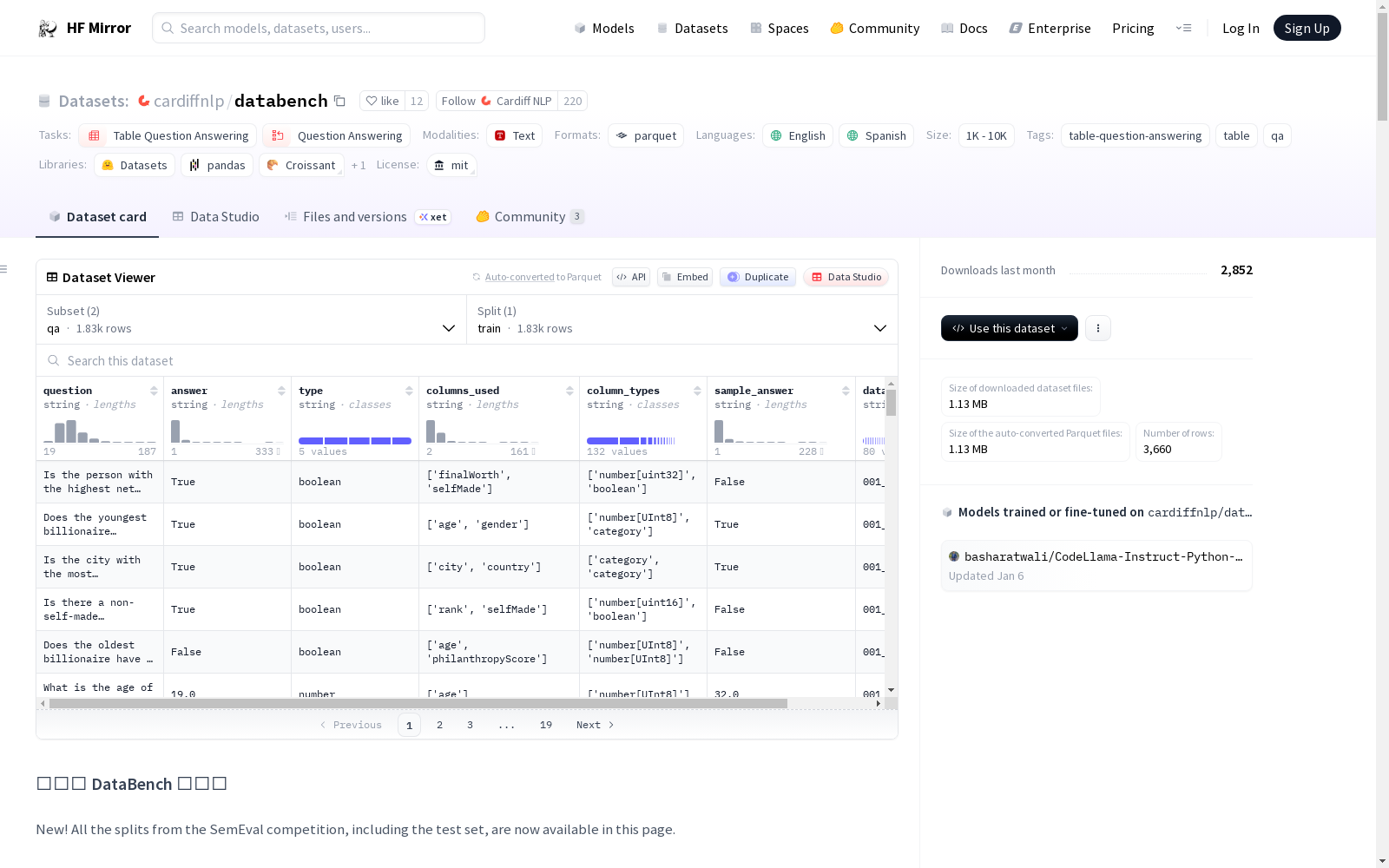
all.parquet: 处理后的数据,每列带有类型标签,格式为parquet。qa.csv:
搜集汇总
数据集介绍
构建方式
在表格问答领域,数据集的构建需兼顾多样性与真实性。DataBench数据集通过整合Kaggle平台上的80个公开数据集,精心构建了涵盖金融、医疗、交通、娱乐等多领域的表格数据。每个子数据集均包含完整的表格结构及对应的问答对,采用Parquet格式存储,确保了数据的高效读取与处理。构建过程中注重数据来源的权威性与时效性,为模型训练提供了丰富且可靠的现实世界场景。
使用方法
针对表格问答任务的研究,DataBench数据集提供了灵活的使用路径。用户可通过HuggingFace数据集库直接加载,选择‘qa’配置以获取所有问答对,或按具体子数据集名称(如‘001_Forbes’)调用完整表格数据。数据集支持训练与评估分割,便于模型在多样化场景中进行端到端训练与性能验证。其轻量级‘lite’版本适用于快速原型开发,而完整版本则满足深度模型训练的需求。
背景与挑战
背景概述
在自然语言处理领域,表格问答任务旨在使模型能够理解结构化表格数据并回答相关问题,这一任务对金融、医疗等多个行业具有重要应用价值。DataBench数据集由CardiffNLP团队构建,其核心研究问题聚焦于提升模型对多样化表格数据的泛化能力与推理精度。该数据集汇集了涵盖经济、社会、娱乐等广泛领域的80个独立表格,每个表格均配有精心设计的问题-答案对,为表格问答模型的训练与评估提供了丰富且真实的基准测试平台,显著推动了表格理解技术的发展。
当前挑战
表格问答领域面临的核心挑战在于模型需同时处理复杂的表格结构、多样的数据类型以及深层次的数值推理,而DataBench旨在应对这些难题。在构建过程中,数据集需确保表格来源的多样性与质量,涵盖从金融报表到社交媒体数据的广泛主题,同时保持问题-答案对的逻辑一致性与标注准确性。此外,整合大量异构表格并维护其语义完整性,避免信息损失或偏差,亦是数据集构建中的关键难点。
常用场景
经典使用场景
在表格问答领域,DataBench数据集以其丰富的多领域表格数据,为自然语言处理模型提供了经典的应用场景。该数据集涵盖了从金融、医疗到娱乐等八十余个主题的表格,每个表格均配有对应的自然语言问题与答案,使得研究者能够系统地评估模型在复杂表格结构下的信息抽取与推理能力。这种设计不仅模拟了真实世界的数据查询环境,还促进了模型在跨领域泛化性能上的优化,成为表格问答任务中不可或缺的基准测试工具。
解决学术问题
DataBench数据集有效解决了表格问答研究中长期存在的领域泛化与复杂推理挑战。传统数据集往往局限于单一领域或简单表格结构,难以全面评估模型的适应性。DataBench通过整合多元化的表格主题与复杂问题类型,为学术研究提供了衡量模型在语义理解、数值计算及逻辑推理等方面性能的标准化平台。其意义在于推动了表格问答技术向更通用、更鲁棒的方向发展,为后续研究奠定了坚实的实证基础。
实际应用
在实际应用中,DataBench数据集为商业智能与数据分析工具的开发提供了关键支持。企业常需从海量表格数据中快速提取洞察,例如通过销售报表预测趋势或从医疗记录中识别风险。该数据集训练出的模型能够自动化处理此类查询,提升数据访问效率与决策精度。此外,它在教育领域辅助学生掌握数据解读技能,在公共服务中优化信息检索系统,展现了广泛的社会价值与实用性。
数据集最近研究
最新研究方向
在表格问答领域,DataBench数据集凭借其涵盖金融、医疗、交通等多元领域的80个表格子集,为模型泛化能力评估提供了丰富基准。当前研究聚焦于跨领域迁移学习,探索预训练模型在异构表格结构中的知识迁移机制,以应对真实场景中表格模式的多样性。随着大语言模型在结构化数据理解上的突破,该数据集正推动表格推理与自然语言交互的融合,促进可解释性表格问答系统的前沿探索。其多语言支持特性亦助力跨语言表格理解研究,为全球化数据应用奠定基础。
以上内容由遇见数据集搜集并总结生成


