CodeSearchNet, PY150, OJ-104, code2seq, BigCloneBench, Google Code Jam, CodeChef, OOPSLA19Li, Devign, Draper, VulDeePecker, SySeVR, Seahymn|代码分析数据集|漏洞检测数据集
收藏github2024-05-05 更新2024-05-31 收录
下载链接:
https://github.com/DevPAI/ml4code-dataset
下载链接
链接失效反馈资源简介:
用于代码检索的代码搜索网络数据集和基准、包含15万个Python程序及其对应抽象语法树的数据集、在线评判系统中的C程序代码集、用于代码自动完成的code2seq数据集、克隆检测基准BigCloneBench、从Google Code Jam竞赛收集的项目、程序分类数据集、用于错误检测的数据集、用于漏洞识别的数据集、包含127万个函数的数据集、基于语义的漏洞候选数据集、基于深度学习的漏洞检测框架数据集、来自9个开源软件项目的易受攻击函数数据集
A dataset and benchmark for code retrieval, including 150,000 Python programs and their corresponding abstract syntax trees, a collection of C program codes from online judging systems, the code2seq dataset for code autocompletion, the BigCloneBench benchmark for clone detection, projects collected from the Google Code Jam competition, a program classification dataset, a dataset for error detection, a dataset for vulnerability identification, a dataset containing 1.27 million functions, a semantic-based vulnerability candidate dataset, a deep learning-based vulnerability detection framework dataset, and a dataset of vulnerable functions from 9 open-source software projects.
创建时间:
2020-05-11
原始信息汇总
数据集概述
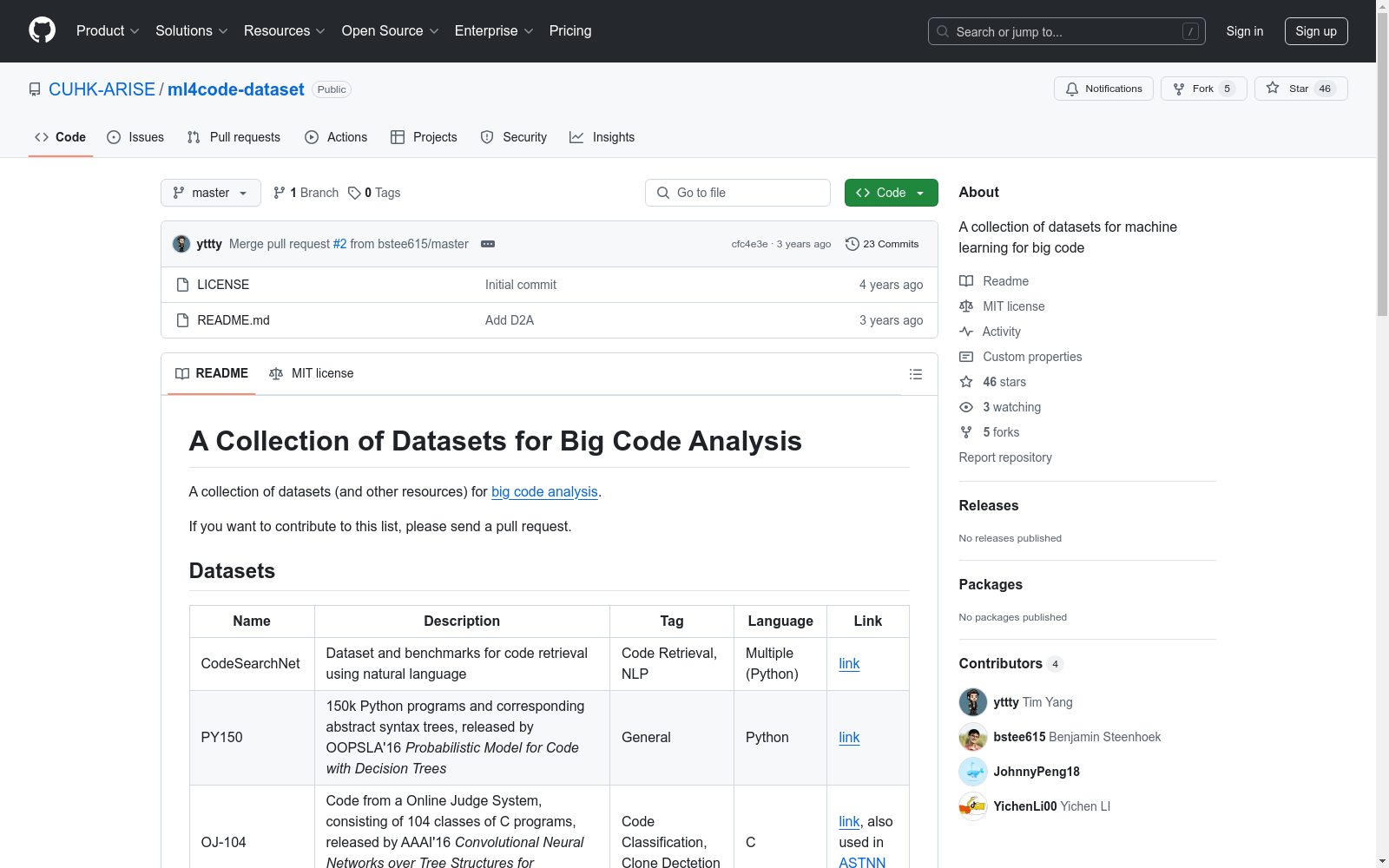
1. CodeSearchNet
- 描述: 用于代码检索的自然语言处理数据集和基准。
- 标签: 代码检索, NLP
- 语言: 多语言 (Python)
- 链接: CodeSearchNet
2. PY150
- 描述: 包含15万个Python程序及其对应的抽象语法树。
- 标签: 通用
- 语言: Python
- 链接: PY150
3. OJ-104
- 描述: 来自在线评判系统的104类C程序代码。
- 标签: 代码分类, 克隆检测
- 语言: C
- 链接: OJ-104
4. code2seq
- 描述: 由ICLR论文发布的代码完成数据集。
- 标签: 代码完成
- 语言: Java, C#
- 链接: code2seq
5. BigCloneBench
- 描述: 克隆检测基准,包含已知克隆的数据集源仓库。
- 标签: 克隆检测
- 语言: Java
- 链接: BigCloneBench
6. Google Code Jam
- 描述: 从Google Code Jam竞赛收集的项目。
- 标签: 克隆检测
- 语言: Java
- 链接: Google Code Jam
7. CodeChef
- 描述: Kaggle发布的程序分类数据集。
- 标签: 代码分类
- 语言: Java
- 链接: CodeChef
8. OOPSLA19Li
- 描述: 由OOPSLA19发布的用于错误检测的数据集。
- 标签: 错误检测
- 语言: Java
- 链接: OOPSLA19Li
9. Devign
- 描述: 由NeurIPS19发布的用于识别漏洞的数据集。
- 标签: 漏洞识别
- 语言: C
- 链接: Devign
10. Draper
- 描述: 包含127万个函数的数据集,通过静态分析标记潜在漏洞。
- 标签: 漏洞识别
- 语言: C
- 链接: Draper
11. VulDeePecker
- 描述: 基于语义的漏洞候选(SeVC)数据集。
- 标签: 漏洞检测
- 语言: C/C++
- 链接: VulDeePecker
12. SySeVR
- 描述: 由arXiv18发布的基于语义的漏洞候选(SeVC)数据集。
- 标签: 漏洞检测
- 语言: C
- 链接: SySeVR
13. Seahymn
- 描述: 来自9个开源软件项目的脆弱函数。
- 标签: 漏洞检测
- 语言: C
- 链接: Seahymn
14. Big-Vul
- 描述: 包含代码更改和CVE摘要的C/C++代码漏洞数据集。
- 标签: 漏洞检测
- 语言: C/C++
- 链接: Big-Vul
15. RAISE19Ferenc
- 描述: 由RAISE19发布的用于预测脆弱JavaScript函数的数据集。
- 标签: 漏洞检测
- 语言: JavaScript
- 链接: RAISE19Ferenc
16. D2A
- 描述: 由ICSE-SEIP21发布的用于AI基于漏洞检测方法的差分分析数据集。
- 标签: 漏洞检测
- 语言: C/C++
- 链接: D2A
17. TypeWriter
- 描述: 由FSE20发布的用于类型推断的数据集。
- 标签: 类型推断
- 语言: Python
- 链接: TypeWriter
18. DeepTyper
- 描述: 由FSE18发布的用于类型推断的数据集。
- 标签: 类型推断
- 语言: JavaScript
- 链接: DeepTyper
19. Typlus
- 描述: 由PLDI20发布的用于类型推断的数据集。
- 标签: 类型推断
- 语言: Python
- 链接: Typlus
AI搜集汇总
数据集介绍
构建方式
该数据集集合涵盖了多个领域的代码分析数据,其构建方式多样且精细。例如,CodeSearchNet通过自然语言与代码的匹配来构建代码检索数据集,而PY150则通过收集150,000个Python程序及其对应的抽象语法树来支持代码分析。OJ-104数据集则从在线评判系统中提取了104类C程序,用于代码分类和克隆检测。这些数据集的构建不仅依赖于大规模的代码收集,还结合了语法树、语义分析等技术,确保数据的多样性和复杂性。
使用方法
这些数据集的使用方法多样,适用于不同的研究场景。例如,CodeSearchNet可以用于训练和评估代码检索模型,通过自然语言查询来检索相关代码片段。PY150和OJ-104则适合用于代码分类、克隆检测等任务,研究人员可以通过这些数据集训练和验证基于语法树的模型。对于漏洞检测相关的数据集,如Devign和VulDeePecker,研究人员可以利用这些数据集进行漏洞识别模型的开发和测试。总体而言,这些数据集为代码分析领域的研究提供了丰富的资源和实验平台。
背景与挑战
背景概述
在软件工程与机器学习的交叉领域,代码分析已成为一个重要的研究方向。CodeSearchNet、PY150、OJ-104等数据集的创建,旨在推动大规模代码分析技术的发展。这些数据集由多个知名研究机构和学者发布,如OOPSLA'16、AAAI'16等,涵盖了代码检索、分类、漏洞检测等多个核心研究问题。例如,CodeSearchNet数据集通过自然语言与代码的关联,推动了代码检索技术的进步;PY150则通过提供大规模Python程序及其抽象语法树,支持了代码表示学习研究。这些数据集不仅为学术界提供了丰富的研究资源,也为工业界提供了实用的工具和方法,极大地促进了代码分析领域的技术进步。
当前挑战
尽管这些数据集在推动代码分析领域取得了显著进展,但仍面临诸多挑战。首先,代码数据的复杂性和多样性使得数据预处理和特征提取变得异常困难。例如,CodeSearchNet需要处理多种编程语言的代码与自然语言的映射问题,而PY150则需应对大规模抽象语法树的生成与解析。其次,代码漏洞检测等任务的标注数据获取成本高昂,且标注质量直接影响模型性能。例如,VulDeePecker和SySeVR数据集在构建过程中,需依赖专家知识进行漏洞标注,这不仅耗时且易出错。此外,代码数据的动态性和不断演化特性,也对模型的持续学习和适应能力提出了更高要求。
常用场景
经典使用场景
在软件工程领域,CodeSearchNet数据集的经典使用场景主要集中在代码检索与自然语言处理(NLP)的交叉应用中。该数据集通过提供大规模的代码片段及其对应的自然语言描述,使得研究者能够训练模型以实现从自然语言查询到代码片段的精准匹配。这种应用不仅提升了代码检索的效率,还为开发者提供了更为智能的代码搜索工具,极大地促进了代码复用和知识共享。
解决学术问题
CodeSearchNet数据集在学术研究中解决了代码与自然语言之间的语义鸿沟问题。通过构建和训练模型,研究者能够探索如何将自然语言查询有效地映射到代码库中的相关代码片段,从而推动了代码检索技术的进步。这一研究不仅在理论上有助于理解代码与自然语言的语义关联,还在实际应用中为软件开发和维护提供了强有力的支持,具有重要的学术价值和实际意义。
实际应用
在实际应用中,CodeSearchNet数据集被广泛用于开发智能代码搜索工具和代码推荐系统。这些系统能够根据开发者的自然语言描述,快速定位到相关的代码片段,从而提高开发效率和代码质量。此外,该数据集还被用于构建代码知识库,支持代码复用和维护,特别是在大型软件项目中,这种应用显著减少了开发时间和成本,提升了软件开发的智能化水平。
数据集最近研究
最新研究方向
在软件工程领域,代码分析与漏洞检测的研究正日益受到关注。近年来,基于深度学习的代码表示学习与图神经网络在漏洞识别和代码分类任务中展现出显著优势。例如,Devign数据集通过图神经网络学习程序语义,有效提升了漏洞检测的准确性。此外,VulDeePecker和SySeVR等数据集通过语义分析技术,为深度学习模型提供了丰富的漏洞候选样本,推动了漏洞检测技术的发展。这些研究不仅为软件安全提供了新的解决方案,也为代码分析领域的自动化和智能化奠定了基础。
以上内容由AI搜集并总结生成


