nasimpson/appomattox-county
收藏Hugging Face2026-05-01 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/nasimpson/appomattox-county
下载链接
链接失效反馈官方服务:
资源简介:
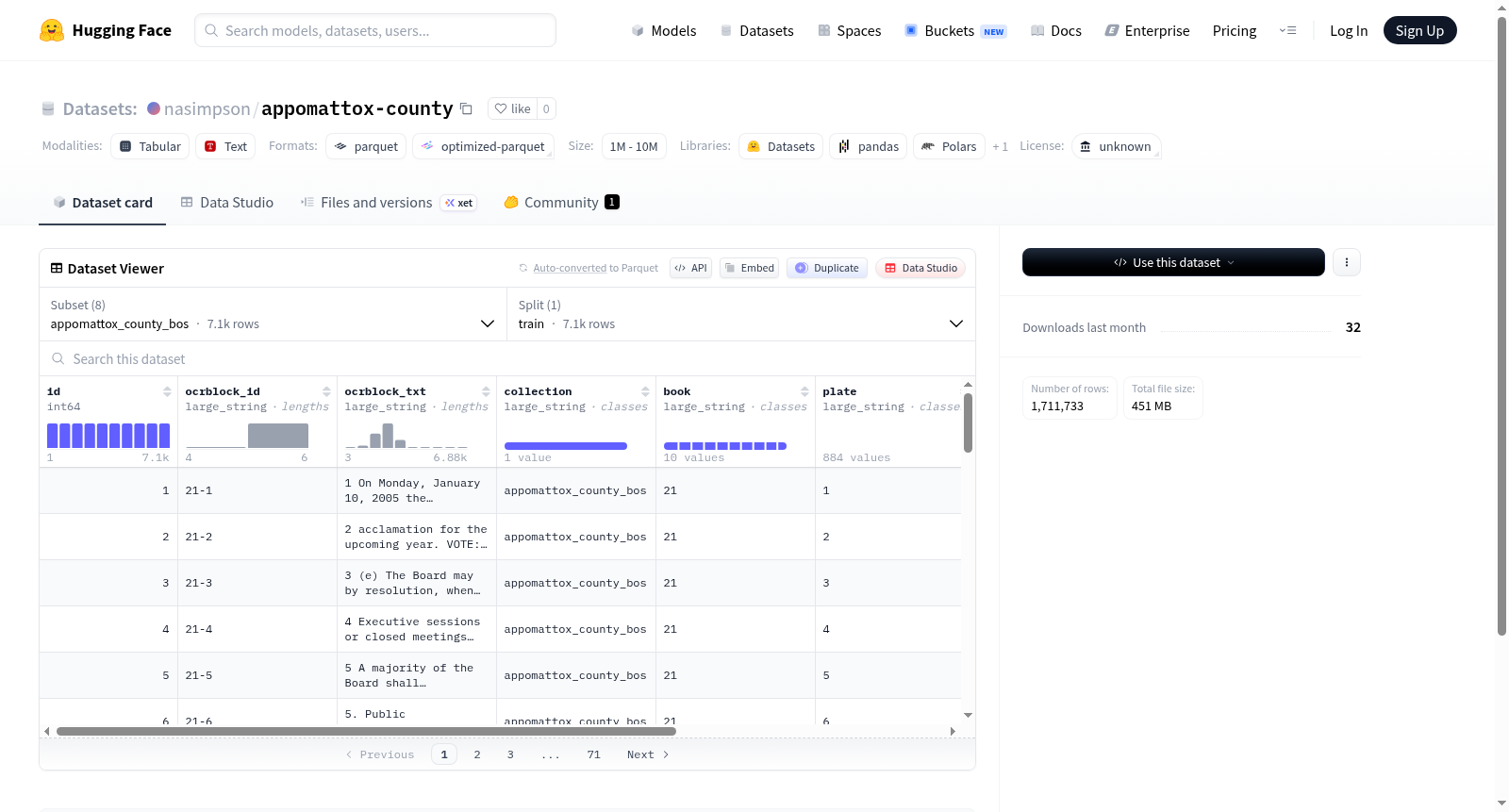
该数据集包含美国弗吉尼亚州阿波马托克斯县(Appomattox County)的多种政府文档和相关数据,涵盖多个配置:县监事会记录(appomattox_county_bos)、学校董事会资料(school_board)、市议会会议记录(town_of_appomattox_council_minutes)、主语料库(corpus_master)、税收索引(corpus_tax_idx)、分类数据(taxonomy_data)、分类值(taxonomy_values)以及网络存档文件元数据(web_archive_file_meta)。数据主要来自OCR处理的文本块(ocrblock_txt),包含文档集合、书籍、页面等信息,并带有分类标签。数据集可能用于文档分类、信息提取、历史分析等NLP任务。
This dataset includes various government documents and related data from Appomattox County, Virginia, USA, covering multiple configurations: Board of Supervisors records (appomattox_county_bos), school board materials (school_board), town council minutes (town_of_appomattox_council_minutes), master corpus (corpus_master), tax index (corpus_tax_idx), taxonomy data (taxonomy_data), taxonomy values (taxonomy_values), and web archive file metadata (web_archive_file_meta). The data primarily consists of OCR-processed text blocks (ocrblock_txt) with information on collections, books, plates, and classification labels. It may be used for document classification, information extraction, historical analysis, and other NLP tasks.
提供机构:
nasimpson
搜集汇总
数据集介绍
构建方式
Appomattox County数据集深度整合了美国弗吉尼亚州阿波马托克斯县的历史档案与公共记录,通过多源异构数据的系统化处理构建而成。该数据集以八个子配置(config)组织,涵盖县监事会文件、学校董事会记录、城镇议会纪要及网络存档元数据等类型。每个子集均采用结构化字段设计,如OCR文本块(ocrblock_txt)与分类标签(classify_json_blob),并基于唯一标识符(id或nanoid)实现跨子集的关联索引,例如corpus_tax_idx通过corpus_nanoid与tax_nanoid链接主语料库与税收分类数据,而taxonomy_data则通过key_path定义层级化语义路径,最终形成可追溯、可交叉查询的复合数据体系。
特点
该数据集的核心优势在于其多维度的信息融合与精细化的结构设计。所有文本数据均源自历史文档的OCR处理,保留了原始版面信息(如plate与book字段),同时通过classify_json_blob注入机器分类结果,服务于领域自适应模型训练。尤为突出的是其分类学设计:taxonomy_values提供标准化值映射,taxonomy_data记录原始值与归一化值的对应关系,而corpus_tax_idx则构建了语料片段与分类目录的索引桥梁,使得研究者能够高效挖掘公共档案中的实体关系与语义模式。子集规模从数百条(如school_board的385条)至数十万条(如taxonomy_data的834,556条)不等,兼顾了专项分析的精准性与大规模学习的覆盖度。
使用方法
该数据集专为Hugging Face Datasets库优化,支持通过Python脚本按需加载。用户可使用load_dataset('appomattox-county', config_name='specified_config')指定子配置,其中config_name参数可选用appomattox_county_bos、corpus_master等八个预定义名称之一。加载后,数据以字典形式呈现,包含config_name对应的特征列(如ocrblock_txt、classify_json_blob),直接适用于序列标注、文本分类或实体链接等自然语言处理任务。开发者亦可利用train-*通配符路径独立访问分片文件,或通过corpus_tax_idx等索引子集构建复杂查询逻辑。建议结合OCR文本与分类元数据进行多任务学习,或利用taxonomy_values完成语义归一化后的数据分析。
背景与挑战
背景概述
Appomattox县数据集汇聚了该地区地方政府在治理过程中产生的多元化数字档案,涵盖县监事会会议记录、学校董事会文献、市政厅会议纪要以及网络存档文件元数据等。该数据集由美国弗吉尼亚州阿波马托克斯县政府及相关档案管理机构创建,旨在系统化保存和结构化呈现地方治理的原始记录。其核心研究问题聚焦于如何通过OCR技术将非结构化的历史手写或印刷文档转化为可供计算分析的文本数据,进而为地方治理模式、公共政策演变及社区历史研究提供数据支撑。该数据集的开发标志着数字人文与公共管理交叉领域的一项基础性贡献,为地方级政府开放数据运动提供了可复用的范例,尤其在小规模行政区域的数据资产化进程中具有示范意义。
当前挑战
该数据集面临多重挑战。在领域问题层面,所处理的核心任务是对大量历史文档进行高精度OCR(光学字符识别),这要求克服手写体与早期印刷体在字体多样性、纸张褪色及墨迹渗透等方面的识别困难。由于文档跨越不同年代,语言表达与排版样式差异显著,进一步增加了文本提取与语义对齐的复杂性。在构建过程中,数据清洗是一大难点,文档碎片(如OCR块)需从不同内容载体中精准剥离,并将其与分类标签、元数据保持一致。针对多达七个不同配置的异构数据源,建立统一的分类体系(如taxonomy_data)并确保数据完整性与互操作性,同样需要精细的工程设计与校验策略。
常用场景
经典使用场景
在地方历史文献的数字化与结构化研究中,阿波马托克斯县数据集承载着弥足珍贵的区域性历史记录。该数据集涵盖县监事会记录、学校董事会档案、城镇议会会议纪要以及网络存档文件元数据等多个子集,通过OCR文本块与分类标签的精细标注,为研究者提供了从手写或印刷文档中提取结构化信息的绝佳试验场。其经典使用场景聚焦于光学字符识别后文本的自动分类与语义解析,尤其适用于训练模型对地方治理、教育决策与公共事务等领域的碎片化文档进行系统性归并与索引。
衍生相关工作
该数据集催生了多项具有影响力的衍生研究,尤其在弱监督学习与跨模态检索领域成果斐然。例如,基于其分类标签结构,研究者提出了针对非连续OCR文本的层次化注意力模型,显著提升了乱序文档的篇章级理解能力。另有工作利用该数据集的税收索引子集,构建了面向历史财政实体的关系抽取框架,实现了从文本块到结构化税务记录的自动映射。在自然语言处理与历史学的交叉地带,该数据集成为评估预训练语言模型在特定时空语境下术语消歧性能的基准之一,推动了对地域性专名变异规则的建模与解读。
数据集最近研究
最新研究方向
在数字人文与地方治理研究的前沿,Appomattox县数据集通过整合历史档案、税务索引、学校董事会记录与市议会纪要等多模态语料,为探索美国地方行政体系的文本化遗迹提供了精微的数字化透镜。该数据集以自动光学字符识别(OCR)技术雕琢的文本块为基石,结合分类元数据与层级化分类法,正推动基于大规模历史文本的实体关系抽取与时间序列语义演化分析。当前研究聚焦于利用其丰富的语料配置(如corpus_master与taxonomy_data)训练领域自适应语言模型,以量化地方政策话语的演变轨迹,并揭示基层治理结构中隐含的社会经济脉络,为理解美国乡村治理的文本实践开辟了崭新的计算路径。
以上内容由遇见数据集搜集并总结生成


