The Catechol Benchmark
收藏arXiv2025-06-09 更新2025-06-11 收录
下载链接:
https://www.kaggle.com/datasets/aichemy/catechol-benchmark/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由帝国理工学院计算机系、化学系和SOLVE Chemistry合作创建,包含1227个数据点,用于机器学习基准测试。数据集涵盖了不同的反应条件,包括两种不同的溶剂和它们在混合物中的比例、反应温度和反应时间。输出包括起始材料和两种观察到的产物的产量。数据集适用于溶剂选择任务,这是一个理论上难以建模但非常适合机器学习应用的领域。
提供机构:
帝国理工学院计算机系, 帝国理工学院化学系, SOLVE Chemistry
创建时间:
2025-06-09
原始信息汇总
Catechol Benchmark 数据集概述
数据集基本信息
- 标题: Catechol Benchmark
- 副标题: Time-series Solvent Selection Data for Few-shot Machine Learning
- 作者: AIchemy 和 2 位协作者
- 最后更新: 一个月前
- 数据集地址: https://www.kaggle.com/datasets/aichemy/catechol-benchmark/
数据集摘要
- 用途: 用于溶剂选择和机器学习(特别是少样本学习)的儿茶酚数据集。
- 相关论文: ArXiv preprint: The Catechol Benchmark: Time-series Solvent Selection Data for Few-shot Machine Learning
数据文件
主数据文件
- catechol_full_data_yields.csv: 包含混合溶剂的完整数据集。
- catechol_single_solvent_yields.csv: 仅包含单一溶剂的数据。
- claisen_data_clean.csv: 来自外部源的 Allyl Phenyl Ether 数据集。
查找表
- acs_pca_descriptors_lookup.csv: ACS 溶剂选择指南的主成分分析表示。
- drfps_lookup.csv: 使用 SMILES 字符串中反应箭头左右分子子结构差异创建的指纹表示。
- fragprints_lookup.csv: 分子指纹和分子片段的组合表示。
- spange_descriptors_lookup.csv: 基于溶剂可测量属性的表示。
- smiles_lookup.csv: SMILES 字符串。
数据集元数据
- 可用性评分: 9.41
- 许可证: MIT
- 预期更新频率: Never
- 标签: Earth and Nature, Investing, Regression, Chemistry, Transfer Learning
数据集活动
- 总浏览量: 126
- 总下载量: 12
- 最近30天浏览量: 105
- 最近30天下载量: 12
- 参与度: 0.09524(每次浏览的下载量)
文件示例 (acs_pca_descriptors_lookup.csv)
- 描述: 将溶剂名称转换为 ACS 溶剂选择指南的主成分分析表示(ACS PCA)。
- 列名:
- SOLVENT NAME: 溶剂名称
- PC1: 主成分 1
- PC2: 主成分 2
- PC3: 主成分 3
- PC4: 主成分 4
- PC5: 主成分 5
搜集汇总
数据集介绍
构建方式
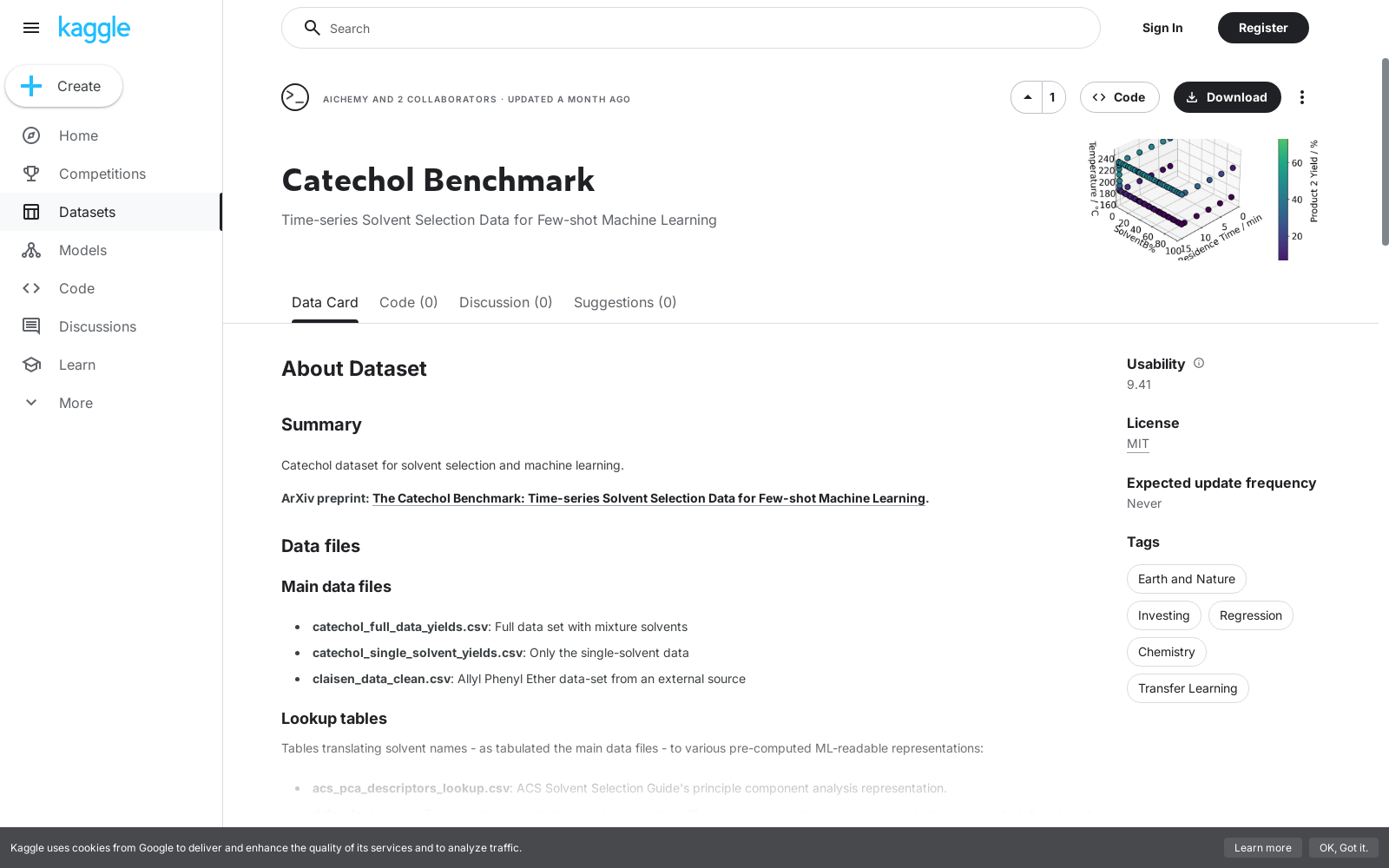
The Catechol Benchmark数据集是通过瞬态流化学技术构建的,该技术能够在连续反应系统中动态调整反应条件,从而高效收集大量反应数据。具体而言,数据集涵盖了超过1200种不同的反应条件,包括溶剂选择、反应温度和停留时间等连续变量。实验过程中,通过高效液相色谱(HPLC)每两分钟进行一次在线分析,定量测量反应产率。此外,数据集还通过主动学习策略优化溶剂选择,以最大化信息增益。
特点
该数据集的特点在于其动态性和连续性,首次提供了机器学习就绪的瞬态流反应数据。数据集不仅包含传统的离散反应变量,还密集测量了停留时间、温度和溶剂空间的连续变化。此外,溶剂混合物被处理为连续变量,通过溶剂比例的变化捕捉反应产率的变化。数据集还展示了非平稳性、异方差性等复杂化学动力学特征,为机器学习模型提供了新的挑战。
使用方法
该数据集适用于多种机器学习任务,包括回归算法、迁移学习、特征工程和主动学习的基准测试。用户可以通过留一法交叉验证评估模型性能,特别是在预测未见溶剂的反应产率时。数据集还支持贝叶斯优化和实验设计,用于优化反应条件。此外,用户可以利用提供的溶剂特征化方法(如Spange描述符)或开发新的特征表示,以改进模型在动态化学系统中的预测能力。
背景与挑战
背景概述
The Catechol Benchmark数据集由英国帝国理工学院与SOLVE Chemistry合作开发,于2025年6月首次发布。作为首个面向机器学习设计的瞬态流动化学数据集,其核心聚焦于溶剂选择这一化学制造关键问题,通过1200余组连续工艺条件数据填补了传统离散参数数据集的空白。该数据集创新性地采用瞬态流技术捕获反应动力学特征,为绿色溶剂开发与可持续制造提供了重要研究平台,显著推动了化学与人工智能的交叉领域发展。
当前挑战
该数据集面临双重挑战:在领域层面,需解决溶剂效应建模的理论难题,其非线性混合特性与反应动力学的耦合对机器学习模型提出极高要求;在构建层面,实验数据的异方差性、非平稳性以及乙酸等溶剂引发的副反应干扰,导致数据清洗与校准异常复杂。此外,溶剂特征化表示方法的缺失和低数据量下的迁移学习问题,进一步增加了模型开发的难度。
常用场景
经典使用场景
The Catechol Benchmark数据集在化学合成与机器学习交叉领域具有重要应用价值,其核心场景聚焦于溶剂选择的动态过程建模。该数据集通过瞬态流技术捕捉了1200余种连续工艺条件下的反应动力学数据,特别适用于研究溶剂比例、温度和停留时间等连续变量对邻烯丙基苯酚重排反应产率的非线性影响。在少样本学习框架下,研究人员可利用该数据集构建预测模型,优化溶剂组合以平衡反应效率与可持续性目标。
解决学术问题
该数据集解决了化学机器学习领域三个关键问题:一是填补了连续工艺条件数据的空白,克服了传统离散变量数据集在工业放大场景中的局限性;二是通过精确校准的产率数据,缓解了化学数据不一致性对预测模型的干扰;三是提供了溶剂混合效应的动态表征,为理解溶剂-反应物复杂相互作用提供了新视角。其意义在于首次实现了瞬态流化学实验数据与机器学习基准测试的无缝对接,推动了动态化学系统的可解释建模。
衍生相关工作
该数据集已催生多项创新研究:Boyne等人开发了BARK贝叶斯树核方法用于黑箱优化;Ranković团队提出GOLLuM框架实现语言模型与高斯过程的融合;Folch等基于该数据集构建了SnAKe路径优化算法。在化学信息学领域,Spange溶剂描述符的扩展应用和DRFP反应指纹的改进版本均以该数据集作为基准测试平台。
以上内容由遇见数据集搜集并总结生成


