ibm-research/WikiVQABench
收藏Hugging Face2026-05-06 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/ibm-research/WikiVQABench
下载链接
链接失效反馈官方服务:
资源简介:
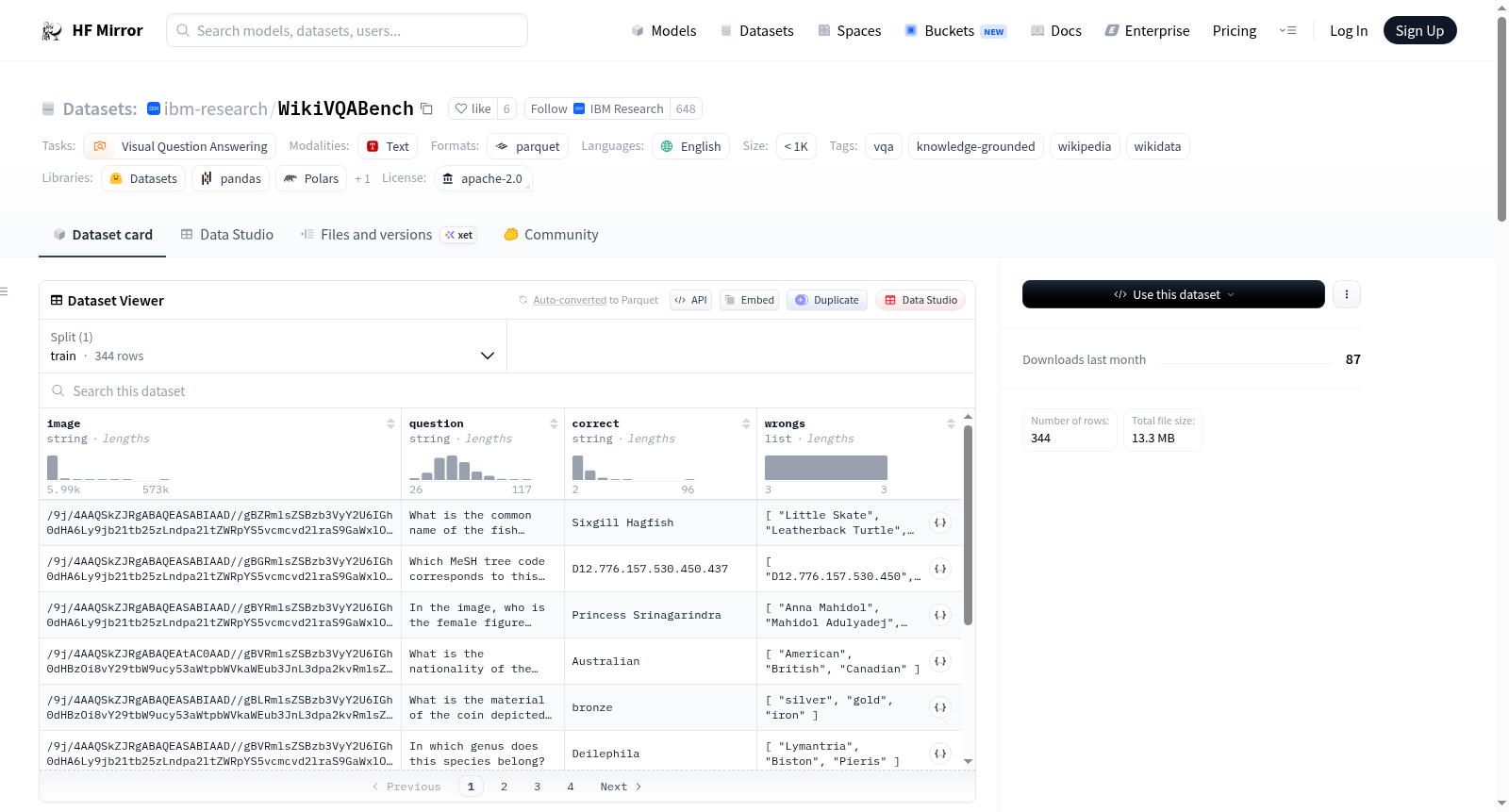
WikiVQABench是一个基于知识的视觉问答(VQA)基准数据集,通过系统地结合Wikipedia图像、相关文章标题和Wikidata的结构化知识构建而成。使用大型语言模型(LLMs)生成候选的多选题图像-问题-答案集,并经过人工审核以确保事实正确性、视觉-文本一致性以及每个问题需要外部知识来解答。数据集包含344个例子,主要用于评估知识感知的视觉语言模型。每个基准例子包括base64编码的图像、自然语言问题、正确答案和三个干扰答案。
WikiVQABench is a human-curated knowledge-grounded VQA benchmark constructed by systematically combining Wikipedia images, their associated article captions, and structured knowledge from Wikidata. We used large language models (LLMs) to generate candidate multiple-choice image-question-answer sets which were subsequently reviewed and curated by human annotators to ensure factual correctness, visual-text consistency, and that each question requires external knowledge in addition to visual evidence for correct resolution. WikiVQABench comprises a substantial collection of Wikipedia images with curated multiple-choice questions designed to benchmark knowledge-aware vision-language models.
提供机构:
ibm-research
搜集汇总
数据集介绍
构建方式
WikiVQABench是一个经过人工精心筛选的知识驱动型视觉问答基准数据集,其构建过程巧妙融合了维基百科图像、对应的文章标题描述以及维基数据中的结构化知识。研究团队首先借助大规模语言模型生成候选的多选题图像-问题-答案集合,随后由人工标注者对每一例进行严格审查与修正,确保答案的事实正确性、图像与文本的一致性,并保证每个问题的解答均需依赖超越视觉信息的外部知识。这种半自动生成结合人工精调的策略,在保证效率的同时显著提升了数据质量。
使用方法
WikiVQABench主要用作评估视觉语言模型在知识型视觉问答任务上的表现。用户可通过官方提供的VLMEvalKit分支(https://github.com/basels/VLMEvalKit/tree/wiki-vqa-bench)加载数据集并运行标准化评测流程。每项评测以准确率为指标,支持对各类模型的横向比较。由于数据量仅为344例,建议将其作为测试集使用,而非训练数据,以避免过拟合风险。代码与数据集均开源发布于HuggingFace平台,便于社区复现与扩展研究。
背景与挑战
背景概述
视觉问答(Visual Question Answering, VQA)作为连接计算机视觉与自然语言处理的关键任务,近年来备受关注。然而,现有基准大多侧重于视觉与语言的直接关联,缺乏对外部知识的深度整合。WikiVQABench由研究者基于Wikipedia图像及其关联的图说与Wikidata结构化知识精心构建,于近期(2025年)发布,旨在测评知识驱动型视觉语言模型的性能。该数据集通过大规模语言模型生成候选的多选题,并经人工审查确保事实准确性与视觉-文本一致性,显著推动了知识感知型VQA领域的发展。凭借其严谨的构建流程与明确的测评导向,WikiVQABench已在包括InternVL3、Claude、Llama等主流模型的评测中展现区分度,成为评估模型跨域知识推理能力的重要标杆。
当前挑战
WikiVQABench所应对的核心领域挑战在于现有VQA基准往往无法衡量模型利用外部知识(如百科事实或结构化知识库)进行推理的能力,而单纯依赖图像中的显式信息。在数据集构建过程中,面临的主要挑战包括:一是如何确保自动生成的高质量问题既涵盖多元知识领域又避免事实性错误,为此采用人工逐条审核以确保无误;二是需要保证问题唯有结合外在知识方可正确解答,避免仅凭视觉线索即可作答的偏向性;三是数据集仅含344个样本,规模较小,限制了其在训练阶段的适用性,仅可作为评估集使用。此外,合成来源可能引入生成模型的固有偏差,需在后续应用中谨慎对待。
常用场景
经典使用场景
在视觉与语言交汇的学术疆域中,WikiVQABench以其独特的知识锚定特性,成为评估多模态模型知识推理能力的标杆性基准。该数据集巧妙融合维基百科图像、图像对应的文章标题描述以及来自维基数据的结构化知识,构建出一系列需要外部知识辅助方能正确解答的多选题。研究者通常将其用作测试集,衡量视觉语言模型在跨领域知识迁移、视觉线索与语义记忆协同推理方面的表现。经典的使用场景聚焦于知识型视觉问答系统的能力评测,通过对比模型在包含不同知识背景题目上的准确率,揭示其知识获取、整合与运用的深层机制。
解决学术问题
WikiVQABench直面视觉问答领域中长期悬而未决的核心难题——如何有效评估模型在缺乏显式视觉证据时调用外部知识的能力。传统VQA数据集往往仅依赖图像内容即可作答,而该基准要求模型必须借助超越图像边界的百科知识与结构化语义信息才能得出正确答案,从而精准刻画了模型的知识边界与推理盲区。其问世为学术界提供了一个纯净的评估舞台,使得研究者得以剥离感知能力的干扰,单独考察视觉语言模型在知识检索、知识融合与跨模态推理等维度的真实水平,有力推动了知识驱动型多模态理解的理论探索。
实际应用
在工业界与学术界的实际应用场景中,WikiVQABench扮演着模型选型与能力诊断的重要角色。人工智能实验室与科技公司可借助该基准测试筛选具备扎实知识基础的多模态模型,并将其部署于智能问答助手、教育辅助系统、内容审核平台等领域。例如,在自动化百科问答系统中,模型需要回答诸如“图中建筑为何时建成?其设计风格属于哪种流派?”等需结合图像与外部知识的问题,该基准所评测的知识推理能力直接决定了系统在实际交互中的准确性与可信度。此外,该数据集还可作为多模态模型迭代训练后的验证工具,帮助开发者识别知识盲点并针对性优化。
数据集最近研究
最新研究方向
WikiVQABench作为一项融合维基百科图像与结构化知识的人类精标基准,正推动知识驱动型视觉问答研究迈向更深层次的认知推理。该数据集通过LLM生成候选QA对并由人工审核,确保每道题目均需外部知识联合图像证据方可解答,精准刻画了多模态模型在事实性知识与视觉内容交互时的能力边界。当前前沿方向聚焦于评估大型视觉语言模型在开放域知识检索与视觉语义对齐上的融合表现,例如InternVL3-78B以75.6%的准确率领先,揭示了模型规模与知识泛化能力的正相关;而小参数量模型如SmolVLM-256M的24.7%准确率,则凸显了轻量化架构在知识密集型任务中的瓶颈。这一基准的构建与迭代,不仅溯源至维基百科的知识权威性与维基数据的结构化优势,更与多模态大模型在信息检索、智能问答等热点场景的落地需求紧密相连,其影响在于为评估模型的知识迁移与视觉常识推理提供了可靠标尺,同时引导社区关注数据质量、知识覆盖与评估公平性——尤其是面对合成数据源潜在偏差时,如何通过人工干预确保基准的科学有效。未来,WikiVQABench有望成为检验多模态AI在动态知识环境中适应性的枢纽工具,推动模型从模式匹配向真正理解与推理演进。
以上内容由遇见数据集搜集并总结生成


