keithmanaloto/kapampangan-dictionary-embeddings
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/keithmanaloto/kapampangan-dictionary-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- pam
- en
license: cc-by-4.0
task_categories:
- feature-extraction
- sentence-similarity
tags:
- semantic-search
- sentence-embeddings
- low-resource-languages
- dictionary
- kapampangan
- philippine-languages
- austronesian
- sentence-transformers
pretty_name: Kapampangan Dictionary Embeddings
size_categories:
- 1K<n<10K
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: raw
path: data/raw-*
- config_name: source
data_files:
- split: train
path: source/train-*
- config_name: enriched
data_files:
- split: train
path: enriched/train-*
---
# Kapampangan Dictionary Embeddings
The first dedicated Kapampangan sentence embedding dataset. 4,971 entries from a 1730s Kapampangan-English dictionary, enriched with LLM-generated semantic metadata and pre-computed embeddings from 6 models.
Designed for semantic search, retrieval, and clustering over Kapampangan vocabulary. Includes a 100-query retrieval benchmark and evaluation results from 5 retrieval improvement experiments.
**Read the origin story:** [From a 300-Year-Old Dictionary to Hugging Face: I Built Kapampágan's First Embedding Dataset](https://medium.com/@keithmanaloto/from-a-300-year-old-dictionary-to-hugging-face-i-built-kapamp%C3%A1ngans-first-embedding-dataset-dce2b877bd83) — covers the pipeline from raw dictionary to initial dataset (pre-experiment baseline).
## How It Works
Off-the-shelf embedding models don't understand Kapampangan. This dataset bridges the gap by enriching each dictionary entry with English semantic metadata (synonyms, paraphrases, categories, search queries) using Claude Haiku 4.5, then embedding the combined text. The models search over the English enrichment — not the Kapampangan words directly.
This "enrichment bridge" approach works for any low-resource language: describe your language's vocabulary in a language the model already knows.
> **Note on enrichment quality:** The semantic metadata was generated automatically by an LLM (Claude Haiku 4.5) based on the dictionary's English definitions, then spot-checked by a native Kapampangan speaker. However, not every entry was individually verified — accuracy was traded for coverage across all 4,971 entries. The enrichment reflects what an LLM infers from English translations, not ground-truth Kapampangan semantics. Treat the enrichment fields as useful for retrieval, not as authoritative linguistic data.
## Dataset Schema
### Text Fields
| Column | Type | Description |
|---|---|---|
| `kapampangan_word` | string | Modern Kapampangan spelling (normalized from 1730s orthography) |
| `english_meaning` | string | English translation/definition |
| `original_word` | string | Original 1730s Spanish-influenced spelling (when different from normalized) |
| `category` | string | Original dictionary thematic grouping (52 unique values, present on ~24% of entries) |
### Enrichment Fields (LLM-generated)
| Column | Type | Description |
|---|---|---|
| `synonyms` | list[string] | English synonyms and near-synonyms |
| `related_concepts` | list[string] | Semantically related English terms |
| `paraphrases` | list[string] | Alternative English phrasings of the meaning |
| `categories` | list[string] | Semantic category tags from a closed 27-tag set |
| `usage_contexts` | list[string] | Example contexts where the word might appear |
| `search_queries` | list[string] | Anticipated search queries a user might type |
### Embedding Columns
| Column | Model | Dims | Multilingual? |
|---|---|---|---|
| `emb_stella_400m` | `NovaSearch/stella_en_400M_v5` | 1024 | No (English) |
| `emb_multilingual_e5_large` | `intfloat/multilingual-e5-large` | 1024 | Yes (100 langs) |
| `emb_multilingual_e5_small` | `intfloat/multilingual-e5-small` | 384 | Yes (100 langs) |
| `emb_bge_m3` | `BAAI/bge-m3` | 1024 | Yes (100+ langs) |
| `emb_bge_base_en_v1_5` | `BAAI/bge-base-en-v1.5` | 768 | No (English) |
| `emb_all_minilm_l6_v2` | `sentence-transformers/all-MiniLM-L6-v2` | 384 | No (English) |
All embeddings are L2-normalized (unit vectors). Cosine similarity = dot product.
## Which Model to Use
| Use Case | Model | Why |
|---|---|---|
| **Best overall retrieval** | `stella_en_400M_v5` | Highest bi-encoder MRR (0.539), +8.5% over e5-large |
| **Best with reranker** | `stella_en_400M_v5` + `bge-reranker-v2-m3` | MRR 0.596 (+20% over baseline), best overall pipeline |
| **Exact Kapampangan lookups** | `bge-base-en-v1.5` | 0.950 MRR on exact queries, good for edge deployment |
| **Lightweight / mobile** | `all-MiniLM-L6-v2` | 22M params, ties the 568M bge-m3 head-to-head (42 vs 41 query wins) |
| **Not recommended** | `bge-m3` | Worst overall despite being the largest model. Has catastrophic failures on queries others get rank 1 |
## Evaluation Results
Benchmarked with 100 hand-crafted queries across 4 categories: exact Kapampangan lookups (20), English keyword (30), semantic/descriptive (30), Kapampangan-to-Kapampangan (20).
### Bi-encoder Only
| Model | Params | R@1 | R@5 | R@20 | MRR |
|---|---|---|---|---|---|
| **stella_en_400M_v5** | 400M | **0.440** | **0.620** | **0.740** | **0.539** |
| multilingual-e5-large | 560M | 0.420 | 0.560 | 0.670 | 0.497 |
| bge-base-en-v1.5 | 109M | 0.320 | 0.510 | 0.650 | 0.413 |
| multilingual-e5-small | 118M | 0.310 | 0.540 | 0.610 | 0.410 |
| all-MiniLM-L6-v2 | 22M | 0.300 | 0.530 | 0.670 | 0.397 |
| bge-m3 | 568M | 0.250 | 0.490 | 0.570 | 0.356 |
### Best Pipeline (Bi-encoder + Reranker)
| Pipeline | R@1 | R@5 | R@20 | MRR |
|---|---|---|---|---|
| **stella_400M → bge-reranker-v2-m3 (top-50)** | **0.520** | **0.640** | **0.740** | **0.596** |
| stella_400M (bi-encoder only) | 0.440 | 0.620 | 0.740 | 0.539 |
| e5-large baseline | 0.420 | 0.560 | 0.670 | 0.497 |
The reranker improves MRR by +0.057 over stella alone and +0.099 (+20%) over the original e5-large baseline. See `eval/results_reranker_comparison.json` for the full reranker model comparison.
### Per Category (MRR)
| Model | Exact | Keyword | Semantic | Kap-to-kap |
|---|---|---|---|---|
| stella_en_400M_v5 | 0.941 | 0.697 | 0.368 | 0.008 |
| multilingual-e5-large | 0.930 | 0.650 | 0.378 | 0.012 |
| bge-base-en-v1.5 | **0.950** | 0.489 | 0.251 | 0.003 |
| multilingual-e5-small | 0.678 | 0.601 | 0.313 | 0.003 |
| all-MiniLM-L6-v2 | 0.775 | 0.580 | 0.225 | 0.001 |
| bge-m3 | 0.620 | 0.509 | 0.256 | 0.010 |
### Retrieval Improvement Experiments
Five experiments were conducted to improve retrieval beyond the original baseline:
| Experiment | Hypothesis | Result |
|---|---|---|
| **E1: Reranker** | Cross-encoder reranking improves retrieval | +0.057 MRR on stella. Equalizes weaker bi-encoders to ~0.50. |
| **E2: English-only text** | Removing Kapampangan from embedding text helps | Destroys exact lookups (bge-base exact: 0.950 → 0.319). Net negative. |
| **E3: New English models** | stella/nomic may outperform e5-large | stella_400M wins (0.539 vs 0.497). nomic disappoints (0.409). |
| **E4: Query expansion** | LLM-expanded queries improve retrieval | Hurts overall (MRR −0.048). LLM hallucinates wrong Kapampangan meanings. |
| **E5: Reranker comparison** | Which reranker works best with stella? | bge-reranker-v2-m3 is the only one that improves stella. ms-marco-MiniLM actually hurts it. |
Full experiment results are in `eval/results_*.json`. The evaluation script and query set are included in the [source repo](https://github.com/keithmanaloto/kapampangan-dict-embeddings).
## Usage
### Load the Dataset
```python
from datasets import load_dataset
ds = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings")
print(ds["train"][0]["kapampangan_word"], ds["train"][0]["english_meaning"])
```
### Semantic Search (Recommended: stella_en_400M_v5)
```python
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
import numpy as np
ds = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings")
model = SentenceTransformer("NovaSearch/stella_en_400M_v5", trust_remote_code=True)
query_emb = model.encode("water", normalize_embeddings=True)
embs = np.array(ds["train"]["emb_stella_400m"])
sims = embs @ query_emb
top_5 = np.argsort(-sims)[:5]
for i in top_5:
entry = ds["train"][i]
print(f"{sims[i]:.3f} {entry['kapampangan_word']} — {entry['english_meaning'][:80]}")
```
### Other Splits and Configs
The dataset includes intermediate pipeline outputs as separate splits/configs:
```python
from datasets import load_dataset
# Raw split — cleaned dictionary (normalized orthography, deduped), no enrichment or embeddings
raw = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings", split="raw")
# Fields: kapampangan_word, english_meaning, original_word, category
# Source config — original uncleaned entries.json (4,976 entries, pre-deduplication)
source = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings", "source", split="train")
# Fields: word, meaning
# Enriched config — LLM-enriched metadata, no embeddings
enriched = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings", "enriched", split="train")
# Fields: kapampangan_word, english_meaning, original_word, category, synonyms, related_concepts, paraphrases, categories, usage_contexts, search_queries
```
### Using Text Fields Only (BYO Embeddings)
```python
from datasets import load_dataset
ds = load_dataset("keithmanaloto/kapampangan-dictionary-embeddings")
# Use the enrichment fields to build your own embedding text
entry = ds["train"][0]
text = f"{entry['kapampangan_word']}\n{entry['english_meaning']}\n"
text += "\n".join(entry["paraphrases"])
text += "\n".join(entry["search_queries"])
# Embed with your preferred model
```
## Important: Query Prefixes
E5 models require specific prefixes. The dataset embeddings were generated with `"passage: "` prefix. At query time, use `"query: "` prefix. Getting this wrong silently degrades results.
| Model | Query Prefix | Passage Prefix (already applied) |
|---|---|---|
| stella_en_400M_v5 | *(none)* | *(none)* |
| multilingual-e5-large | `"query: "` | `"passage: "` |
| multilingual-e5-small | `"query: "` | `"passage: "` |
| all-MiniLM-L6-v2 | *(none)* | *(none)* |
| bge-m3 | *(none)* | *(none)* |
| bge-base-en-v1.5 | *(none)* | *(none)* |
## Known Limitations
- **Kapampangan-to-Kapampangan retrieval fails.** All 20 kap-to-kap queries score ~0 across all models. No off-the-shelf model understands Kapampangan semantic relationships. The models retrieve via English enrichment text, not Kapampangan understanding.
- **English word collisions.** Some normalized Kapampangan words match English words (e.g., "API" = fire, "MATE" = death). The embedding may pull toward the English meaning. 497 such collisions exist; only one (BANGLE) caused a material enrichment error (fixed).
- **The eval benchmark tests retrieval, not understanding.** High Recall@K means the model surfaces the right entry — the LLM enrichment is doing the heavy lifting, not Kapampangan comprehension.
- **Enrichment is LLM-generated with spot checks.** All enrichment fields (synonyms, paraphrases, categories, etc.) were produced by Claude Haiku 4.5 from English definitions and spot-checked by a native Kapampangan speaker, but not exhaustively verified. Useful for retrieval but not authoritative linguistic data, especially for culturally specific or archaic terms.
- **UPPERCASE headwords.** Entries are stored in UPPERCASE. This is intentional — lowercasing was tested and degraded retrieval (MRR 0.497 → 0.451). Keep queries in natural case.
## Austronesian Cognate Effect
Kapampangan words with Pan-Austronesian cognates (shared with Tagalog, Malay, Indonesian) get 3.2% higher cross-lingual alignment from embedding models compared to uniquely Kapampangan words. The models leverage incidental subword overlap from related languages in their training data.
Examples:
- **bulan** (moon) — 0.948 similarity. Cognate: Tag *buwan*, Mal/Indo *bulan*
- **takut** (fear) — 0.923. Cognate: Tag *takot*, Mal/Indo *takut*
- **lugud** (love) — 0.774. No cognate (uniquely Kapampangan)
- **yaman** (delicious) — 0.801. False friend: Tag *yaman* = wealth
This is relevant for anyone working on other low-resource Austronesian languages.
## Building on This Dataset
### Use Cases
- **Semantic search for Kapampangan apps** — the [Learn Kulitan app I built](https://keithmanaloto.medium.com/i-built-an-app-in-an-attempt-to-slow-down-the-death-of-a-language-c63882ab66a5) already uses `multilingual-e5-large` for dictionary search, but without orthography normalization, data cleaning, or enrichment. This dataset provides all three with `stella_en_400M_v5` as the recommended model. Details on how it was applied and the app download link are in the linked article.
- **RAG** — retrieve relevant dictionary entries as context for an LLM (e.g., "What's the Kapampangan word for rain?" → retrieve URAN → feed to LLM)
- **Text classification** — train a classifier using embedding vectors + the 27 category tags
- **Clustering** — discover semantic neighborhoods in the Kapampangan vocabulary
- **Cross-lingual retrieval research** — benchmark embedding models on a low-resource Philippine language
- **Apply this pipeline to other low-resource languages** — the enrichment bridge approach (LLM-generate English metadata → embed with off-the-shelf models) is language-agnostic. If you have a bilingual dictionary for any low-resource language, you can replicate this pipeline to get working semantic search without waiting for a dedicated model
### Future Improvements
- **Native speaker review of enrichment fields** — exhaustive verification of LLM-generated metadata, especially for culturally specific terms
- **Expand the eval set** — more kap-to-kap queries to better measure cross-lingual capability as models improve
- **Fine-tune a multilingual model on Kapampangan text** — could unlock kap-to-kap retrieval, which currently scores ~0
- **Add entries from other Kapampangan sources** — expand beyond the Bergaño dictionary
## Source Data
Derived from *Vocabulario de la lengua Pampangan* by Fray Diego Bergaño, O.S.A. (1732), a Spanish Augustinian missionary's Kapampangan dictionary — one of the oldest extant studies of the Kapampangan language.
English translation by Fray Venancio Q. Samson, published 2007 by the Juan D. Nepomuceno Center for Kapampangan Studies, Holy Angel University (Angeles City, Pampanga, Philippines), with support from the National Commission for Culture and the Arts (NCCA). ISBN 978-971-93672-1-5. Winner of the NBDB National Book Awards (2007).
~40% of entries have orthography normalized from 1730s Spanish-influenced spelling to modern Kapampangan. Original spellings are preserved in the `original_word` field.
## Pipeline
1. **Clean** — Validate, deduplicate, normalize orthography (4,976 raw → 4,971 clean)
2. **Enrich** — Claude Haiku 4.5 via Batch API generates semantic metadata per entry (~$5, 4,971/4,971 success)
3. **Embed** — 6 sentence-transformer models, ~25 min on Apple Silicon
4. **Evaluate** — 100 hand-crafted queries, Recall@1/5/20 + MRR per model and category
5. **Experiment** — 5 retrieval improvement experiments (reranking, text variants, new models, query expansion)
Full source code: [github.com/keithmanaloto/kapampangan-dict-embeddings](https://github.com/keithmanaloto/kapampangan-dict-embeddings)
## License
CC BY 4.0. The source dictionary (1732) is public domain. LLM-enriched fields and embeddings are original to this project.
## Citation
If you use this dataset, please cite:
```bibtex
@dataset{manaloto2026kapampangan,
title={Kapampangan Dictionary Embeddings},
author={Manaloto, Keith},
year={2026},
publisher={HuggingFace},
url={https://huggingface.co/datasets/keithmanaloto/kapampangan-dictionary-embeddings}
}
```
Original dictionary: Bergaño, Diego (1732). *Vocabulario de la lengua Pampangan*. English translation: Samson, Venancio Q. (2007). Holy Angel University.
提供机构:
keithmanaloto
搜集汇总
数据集介绍
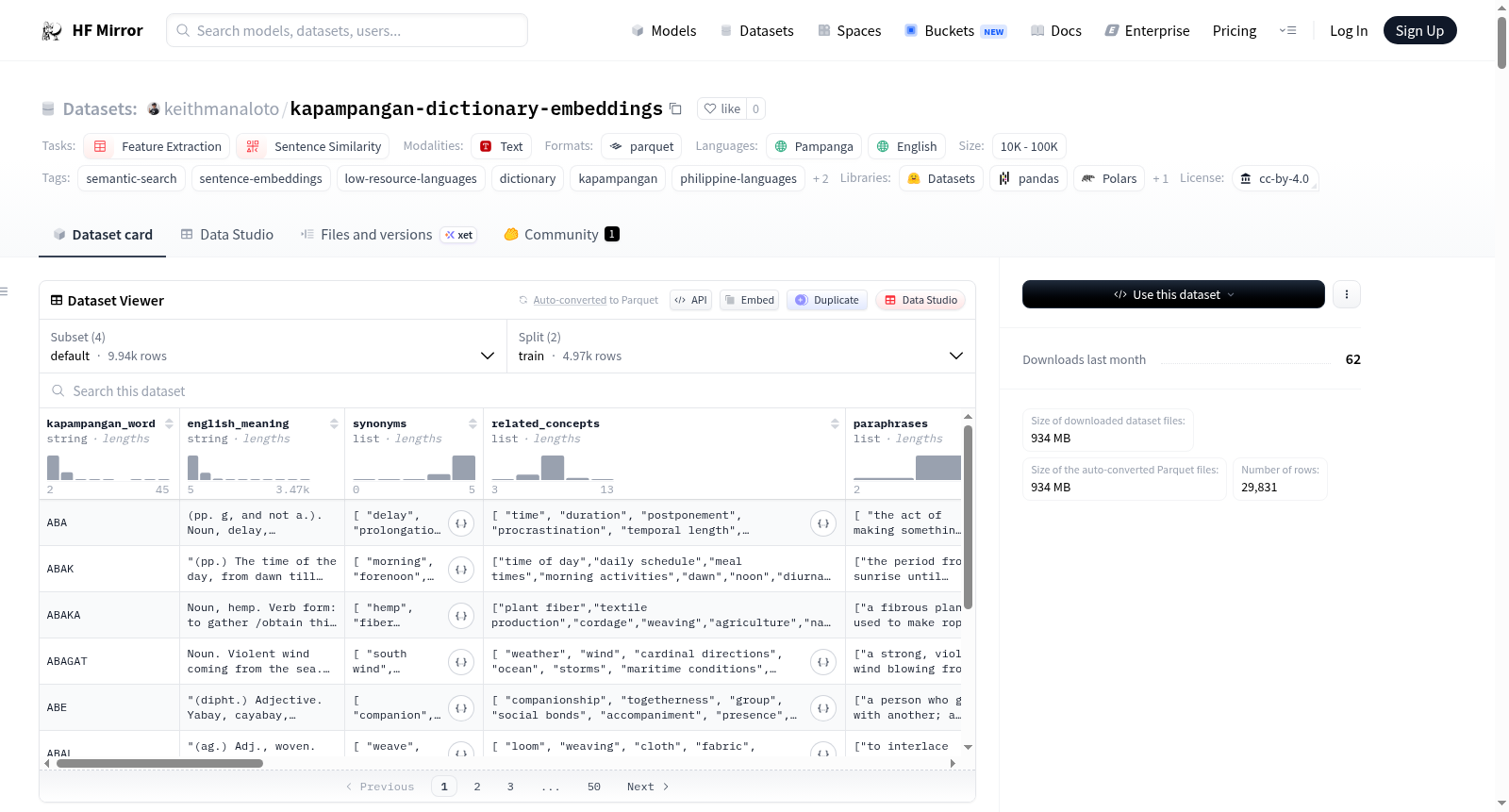
构建方式
在低资源语言处理领域,构建高质量的语义嵌入数据集面临独特挑战。本数据集源自1732年出版的《Vocabulario de la lengua Pampangan》历史词典,包含4,971个词条。构建流程首先对原始词条进行清洗与去重,并将18世纪西班牙影响的拼写规范化为现代卡帕潘甘语正字法。随后,利用Claude Haiku 4.5大语言模型为每个词条自动生成英语语义元数据,包括同义词、释义变体、语义类别等丰富特征。最后,通过六种不同的预训练嵌入模型为这些增强文本生成向量表示,形成可直接用于检索任务的标准化嵌入。
特点
该数据集作为首个专门针对卡帕潘甘语的句子嵌入资源,其核心特征体现在多层次的语义表示架构上。每个词条不仅包含原始卡帕潘甘语词汇及其英语释义,还集成了大语言模型生成的六类语义元数据字段,构建了从表层词汇到深层概念的语义桥梁。数据集提供了六种本地嵌入模型和六种API嵌入模型的预计算向量,覆盖从轻量级到高性能的不同应用场景。特别设计的评估基准包含100个手工构建的查询,涵盖精确查找、关键词检索、语义查询和跨语言检索四种类型,为模型选择提供了实证依据。
使用方法
使用本数据集时,研究者可通过HuggingFace数据集库直接加载不同配置,包括原始词条、增强元数据或预计算嵌入。对于语义检索任务,推荐采用"增强桥接"方法:将查询文本转化为英语描述,通过比较查询向量与数据集中英语元数据生成的嵌入向量实现检索。数据集提供了完整的代码示例,展示如何利用stella_en_400M_v5本地模型或gemini-embedding-001 API模型进行相似度计算。用户可根据具体需求选择不同模型配置,如精确查找场景适合bge-base-en-v1.5模型,而端到端检索管道可结合bi-encoder与重排序器获得最佳性能。
背景与挑战
背景概述
在低资源语言计算语言学领域,针对特定语言的语义表示资源长期匮乏。Kapampangan Dictionary Embeddings数据集应运而生,由研究者Keith Manaloto于2026年创建,旨在为菲律宾的卡潘潘甘语构建首个专用的句子嵌入数据集。该数据集基于18世纪30年代由西班牙传教士Fray Diego Bergaño编纂的卡潘潘甘语-英语历史词典,通过现代自然语言处理技术进行深度加工。其核心研究问题聚焦于如何利用现有双语词典和大型语言模型,为缺乏大规模语料库的低资源语言生成高质量的语义嵌入,从而支持语义搜索、信息检索和词汇聚类等下游任务。这一工作不仅为卡潘潘甘语的语言技术发展提供了关键基础设施,也为其他南岛语系低资源语言的资源构建提供了可复现的范式。
当前挑战
该数据集致力于解决低资源语言语义检索这一核心领域问题,其首要挑战在于克服现成嵌入模型对卡潘潘甘语缺乏理解能力的根本局限。构建过程面临多重具体困难:其一,源数据来自近三百年前的历史词典,其正字法与现代拼写存在显著差异,需要进行系统性的规范化处理;其二,为弥补目标语言语料的稀缺,采用了基于大型语言模型的‘语义增强桥接’方法,即利用英语释义生成同义词、释义和上下文等元数据,但这种方法依赖模型推理而非真实语言知识,可能存在语义偏差;其三,评估显示现有模型在卡潘潘甘语到卡潘潘甘语的检索任务上几乎完全失效,揭示了跨语言语义对齐的深层难题。此外,数据构建还需在自动化处理的规模效益与人工验证的准确性之间寻求平衡。
常用场景
经典使用场景
在低资源语言处理领域,该数据集为卡帕姆潘甘语(Kapampangan)这一菲律宾濒危语言提供了首个专用的句子嵌入资源。其最经典的使用场景在于语义搜索与信息检索,通过将18世纪词典中的词条与大型语言模型生成的英文语义元数据相结合,构建了一个跨语言检索桥梁。研究者或开发者可利用预计算的嵌入向量,对卡帕姆潘甘语词汇进行高效的语义相似度计算、近邻搜索和聚类分析,从而在缺乏大规模单语语料的情况下,实现对该语言词汇知识的系统性探索与访问。
衍生相关工作
该数据集本身即是一项系统性研究的产物,其构建与评估流程衍生了一系列关于低资源语言嵌入方法的经典探索。相关工作包括八项检索改进实验,深入比较了重排序技术、查询扩展、不同嵌入模型(包括本地与API模型)在特定任务上的效能。这些实验揭示了通用嵌入模型评测基准(如MTEB)在低资源语言场景下的局限性,并确立了“富集桥梁”这一方法论的可行性。后续研究可基于此数据集,进一步探索针对卡帕姆潘甘语的有监督微调、跨语言对齐增强,或将此管道迁移至其他濒危语言词典的嵌入生成。
数据集最近研究
最新研究方向
在低资源语言处理领域,针对卡帕潘甘语等南岛语系语言的语义表示研究正成为前沿热点。该数据集通过大语言模型生成的英文语义元数据构建“增强桥梁”,为缺乏专用嵌入模型的低资源语言提供了可行的语义检索解决方案。研究焦点集中于探索跨语言检索中嵌入模型的性能边界,特别是针对卡帕潘甘语到卡帕潘甘语查询的失败案例,揭示了当前模型对低资源语言内在语义关系的理解局限。同时,数据集系统评估了多种嵌入与重排序模型组合的效能,其中基于API的gemini-embedding-001与qwen3-reranker-8b的管道取得了最优性能,这为低资源语言的数字保存与应用开发提供了重要的技术基准与实用工具。
以上内容由遇见数据集搜集并总结生成


