Medical-Abstracts-TC-Corpus
收藏数据集概述
数据集名称
- Medical-Abstracts-TC-Corpus
数据集内容
- 包含描述5种不同患者病情的医学摘要数据集,适用于文本分类。
数据集结构
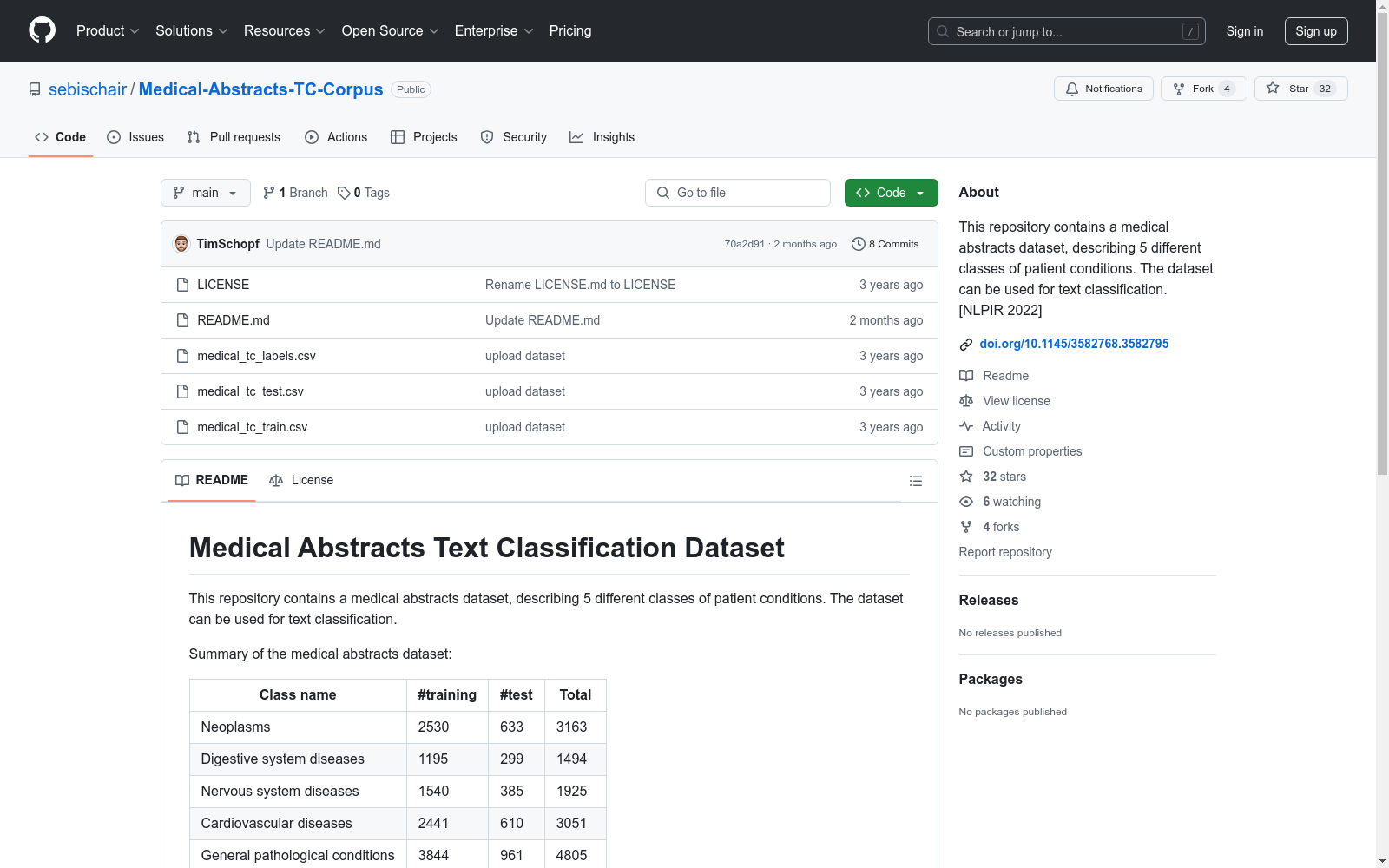
| Class name | #training | #test | Total |
|---|---|---|---|
| Neoplasms | 2530 | 633 | 3163 |
| Digestive system diseases | 1195 | 299 | 1494 |
| Nervous system diseases | 1540 | 385 | 1925 |
| Cardiovascular diseases | 2441 | 610 | 3051 |
| General pathological conditions | 3844 | 961 | 4805 |
| Total | 11550 | 2888 | 14438 |
引用信息
-
数据集创建于论文《Evaluating Unsupervised Text Classification: Zero-shot and Similarity-based Approaches》。
-
引用时请使用以下BibTeX条目:
@inproceedings{10.1145/3582768.3582795, author = {Schopf, Tim and Braun, Daniel and Matthes, Florian}, title = {Evaluating Unsupervised Text Classification: Zero-Shot and Similarity-Based Approaches}, year = {2023}, isbn = {9781450397629}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3582768.3582795}, doi = {10.1145/3582768.3582795}, booktitle = {Proceedings of the 2022 6th International Conference on Natural Language Processing and Information Retrieval}, pages = {6–15}, numpages = {10}, keywords = {Zero-shot Text Classification, Natural Language Processing, Unsupervised Text Classification}, location = {Bangkok, Thailand}, series = {NLPIR 22} }