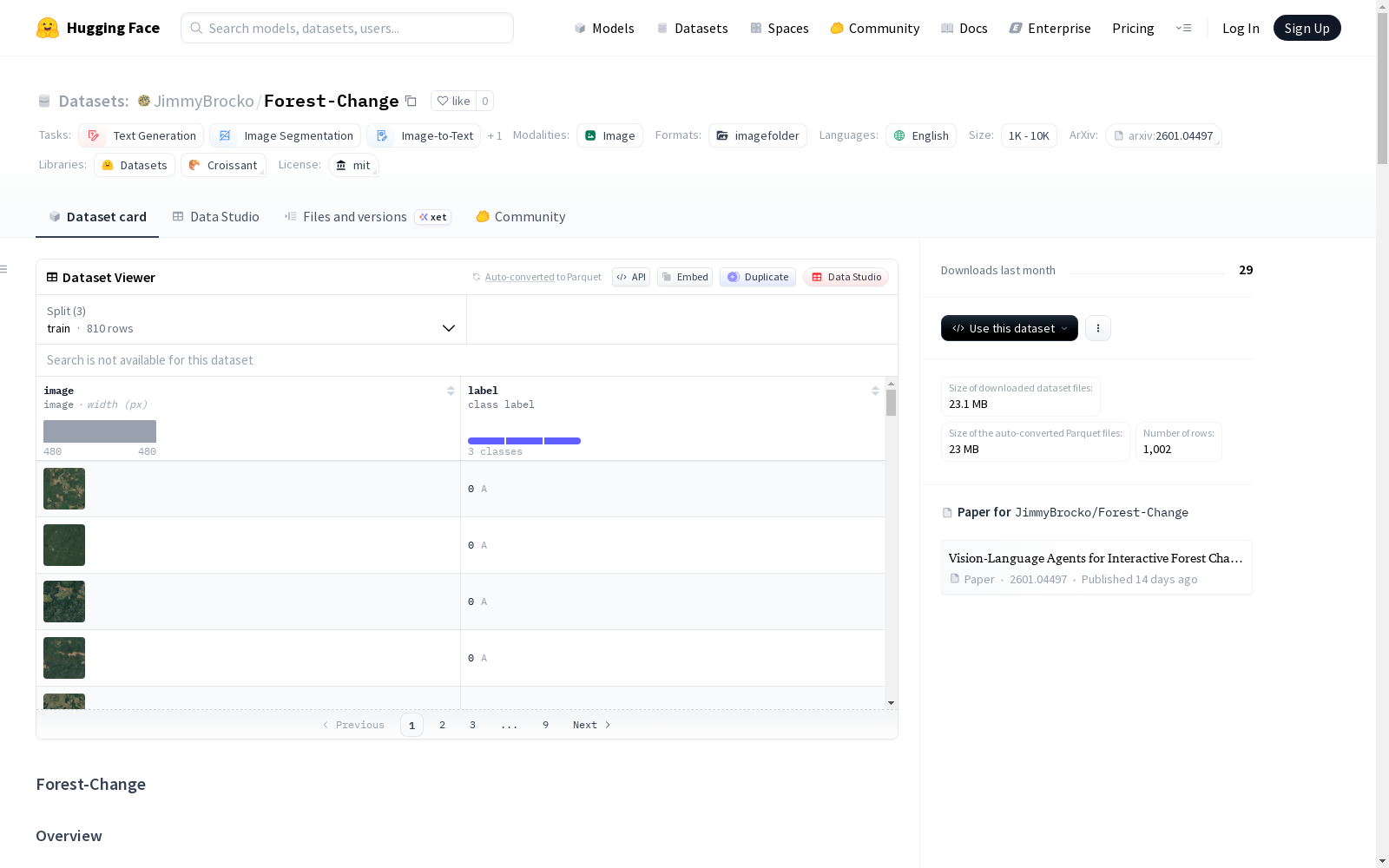
Forest-Change
收藏Forest-Change 数据集概述
数据集简介
Forest-Change 是首个专门为遥感图像中的联合森林变化检测与描述而设计的基准数据集。它提供了双时相卫星图像、像素级森林砍伐掩膜以及描述热带和亚热带地区森林覆盖变化的多粒度语义描述。
数据集详情
- 总样本数:334 个带标注的双时相图像对
- 空间分辨率:约 30 米/像素(中等分辨率)
- 原始图像尺寸:480×480 像素(从更大场景中裁剪)
- 处理后图像尺寸:256×256 像素(为模型训练调整大小)
- 时间分辨率:图像对之间间隔 1 年
- 地理焦点:热带和亚热带森林砍伐前沿
数据划分
- 训练集:270 个样本(约 80%)
- 验证集:31 个样本(约 10%)
- 测试集:33 个样本(约 10%)
数据格式
每个样本包含:
- 图像 A:变化前的 RGB 卫星图像
- 图像 B:变化后的 RGB 卫星图像
- 变化掩膜:二值分割掩膜(0=无变化,1=森林砍伐)
- 描述文本:五个描述森林变化事件、具有不同粒度的描述文本
数据来源
- 图像来源:Google Earth Engine (GEE)
- 基础数据集:源自 Hewarathna 等人 (2024) 的森林生态系统变化检测数据集
- 验证:通过全球森林观察 (GFW) 平台验证森林覆盖变化
- 地理选择:基于世界自然基金会 (WWF) 2015 年森林砍伐前沿报告
描述文本生成
描述文本通过混合两阶段方法生成:
- 人工标注:每个样本由领域标注者手动创建一个描述观察到的变化的描述文本。
- 基于规则的生成:基于定量掩膜属性自动生成四个额外的描述文本:
- 新砍伐区域的百分比(分箱到描述性严重程度级别)
- 单个变化斑块的大小和数量
- 森林砍伐的空间分布模式
- 斑块大小的变化
关键特征
- 变化覆盖率:
- 平均值:每幅图像森林砍伐率 <5%
- 最大值:森林砍伐率 40%
- 分布:严重偏向较低的森林砍伐百分比
- 描述文本长度:双峰分布,包含简洁和详细的描述
- 变化模式:多样化的森林砍伐表现形式,包括:
- 森林区域中分散的小斑块
- 集中的清理区域
- 清理边缘的扩张模式
- 高度可变的斑块大小和配置
- 描述文本内容:描述强调:
- 森林丧失的程度/严重性
- 在图像内的空间位置
- 斑块特征(大小、数量、分布)
预处理
- 所有图像调整为 256×256 像素以确保一致性
- 变化掩膜二值化(0=无变化,1=变化)
- 双时相图像对预先对齐
- 使用数据集特定的均值和标准差统计进行逐通道归一化
- 未应用大气校正
- 未应用云掩膜(部分样本包含部分云遮挡)
使用场景
- 森林变化检测与监测
- 自然环境中的森林砍伐分割
- 生态应用的变化描述
- 遥感多任务学习
- 森林图像上视觉语言模型的基准测试
- 训练交互式森林分析系统
- 开发自动化森林监测工作流
评估指标
由于严重的类别不平衡(大多数像素为无变化),评估需要:
- 每类 IoU:变化类和无变化类的单独指标
- 平均 IoU (mIoU):两个类别 IoU 的平均值
- 描述文本指标:BLEU-n (n=1,2,3,4)、METEOR、ROUGE-L、CIDEr-D
- 注意:由于类别不平衡,不建议使用整体准确率
局限性
- 数据集规模:仅限于 334 个样本,限制了模型的泛化能力
- 场景多样性:由于裁剪和增强策略,独特地理区域的数量有限
- 类别不平衡:严重不平衡,大多数像素代表无变化,对检测模型构成挑战
- 描述文本质量:大多数描述文本是基于规则生成的,限制了语言变异性和自然度
- 地理基础:描述文本中地理特征和上下文信息的结合有限
- 空间分辨率:中等分辨率(约 30 米/像素)限制了非常小规模变化的检测
- 时间覆盖范围:图像对之间的固定 1 年间隔
- 大气影响:部分样本受到部分云遮挡的影响
- 边缘边界:森林砍伐斑块边缘的模糊边界使精确分割复杂化
引用
如果使用此数据集,请引用: bibtex @article{brock2024forestchat, title={Forest-Chat: Adapting Vision-Language Agents for Interactive Forest Change Analysis}, author={Brock, James and Zhang, Ce and Anantrasirichai, Nantheera}, journal={Ecological Informatics}, year={2024} }
@article{hewarathna2024change, title={Change detection for forest ecosystems using remote sensing images with siamese attention u-net}, author={Hewarathna, AI and Hamlin, L and Charles, J and Vigneshwaran, P and George, R and Thuseethan, S and Wimalasooriya, C and Shanmugam, B}, journal={Technologies}, volume={12}, number={9}, pages={160}, year={2024} }
许可证
MIT 许可证 - 仅限学术重用目的
联系方式
有关此数据集的问题或疑问,请联系:
- James Brock: james.brock@bristol.ac.uk
- 布里斯托大学计算机科学学院