ComplexDataLab/OpenFakeTiny
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ComplexDataLab/OpenFakeTiny
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: core
features:
- name: image
dtype: image
- name: prompt
dtype: string
- name: label
dtype: string
- name: model
dtype: string
- name: type
dtype: string
- name: release_date
dtype: string
splits:
- name: train
num_bytes: 1735566609
num_examples: 1250
- name: validation
num_bytes: 1596576694
num_examples: 1250
- name: test
num_bytes: 730876732
num_examples: 1250
download_size: 4070018486
dataset_size: 4063020035
- config_name: reddit
features:
- name: image
dtype: image
- name: prompt
dtype: string
- name: label
dtype: string
- name: model
dtype: string
- name: type
dtype: string
- name: release_date
dtype: string
splits:
- name: test
num_bytes: 822343181
num_examples: 1250
download_size: 806656744
dataset_size: 822343181
configs:
- config_name: core
data_files:
- split: train
path: core/train-*
- split: validation
path: core/validation-*
- split: test
path: core/test-*
- config_name: reddit
data_files:
- split: test
path: reddit/test-*
---
提供机构:
ComplexDataLab
搜集汇总
数据集介绍
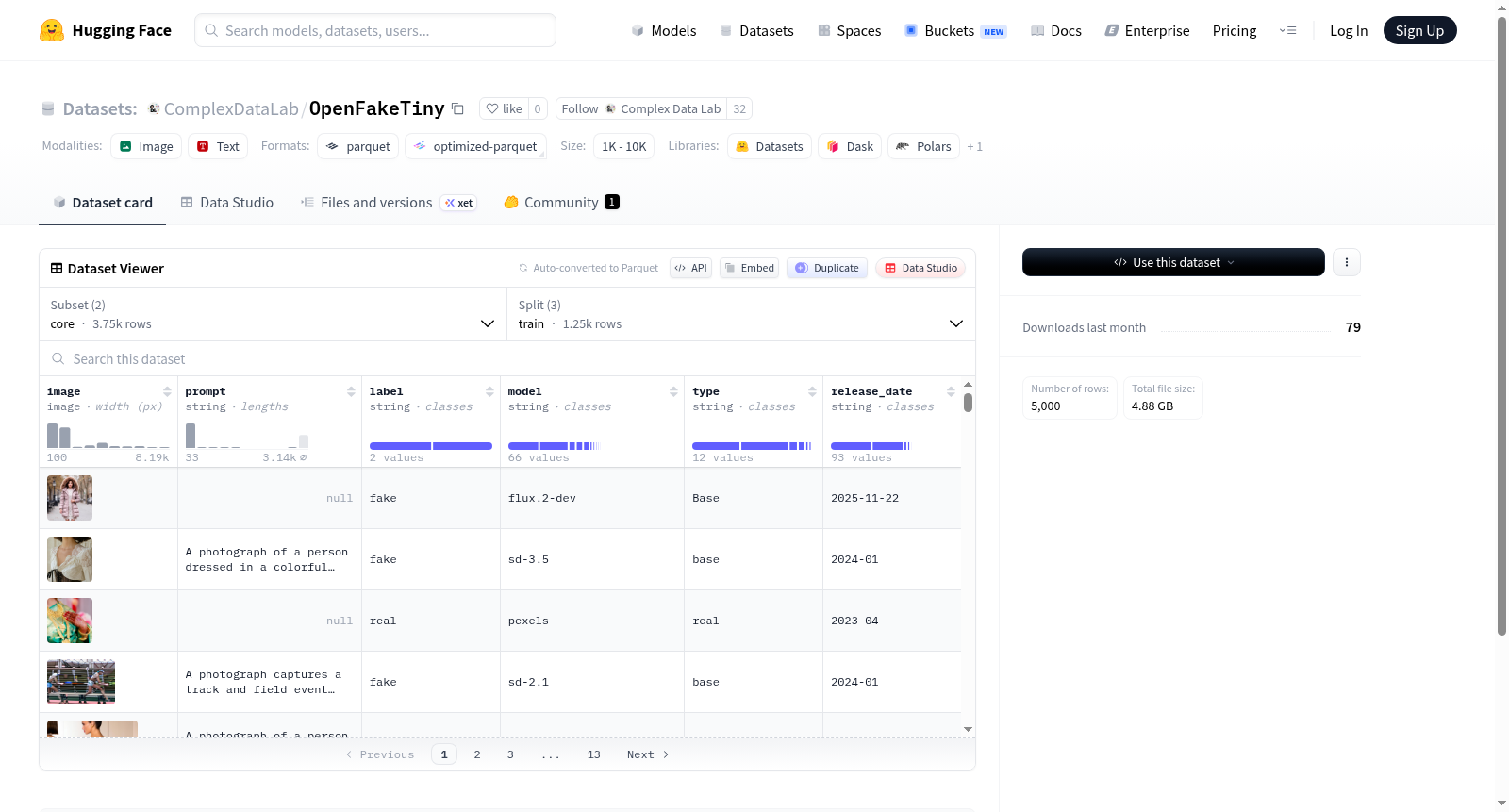
构建方式
OpenFakeTiny数据集是专为深度伪造图像检测研究而构建的轻量级基准数据集。其构建过程涵盖两个核心子集:core与reddit。core子集包含训练、验证和测试三个划分,每个划分均包含1250张图像,共计3750张样本;reddit子集则仅包含1250张测试图像,模拟真实网络场景。每条数据记录均由图像、提示文本、标签、生成模型、数据类型及发布日期六项组成,其中标签字段明确标识图像的真伪属性,模型字段记录生成该伪造图像所使用的AI工具名称。数据集采用HuggingFace的Datasets框架以parquet格式存储,并通过配置文件(config)的层次化设计实现子集的高效统一管理。
使用方法
使用OpenFakeTiny数据集时,可通过HuggingFace Datasets库直接加载。首先安装datasets库,随后调用load_dataset函数并指定数据集名称'OpenFakeTiny',通过config_name参数选择'core'或'reddit'子集。例如:`from datasets import load_dataset; dataset = load_dataset('OpenFakeTiny', 'core')`。加载后可获取包含train、validation、test三个划分的数据对象。每个样本包含image(PIL图像)、label('real'或'fake'字符串)、prompt(生成描述文本)等字段。用户可根据需要选择任意划分进行模型训练或评估,也可结合model字段分析不同生成技术的伪造特征。
背景与挑战
背景概述
OpenFakeTiny数据集诞生于生成式人工智能迅速发展的时代背景下,由研究团队针对深度伪造图像检测这一核心问题精心构建。该数据集聚焦于评估和提升模型对各类生成模型(如扩散模型、生成对抗网络)所产图像的辨识能力,涵盖了包括prompt、标签、来源模型等丰富元信息。自发布以来,OpenFakeTiny为伪造检测领域提供了一个标准化、可复现的基准测试平台,对推动该领域研究方法和评估体系的进步产生了积极影响。
当前挑战
领域内,OpenFakeTiny所面临的核心挑战在于生成模型的持续迭代与进化,使得伪造图像愈发逼真,传统检测方法的泛化能力受到严峻考验。在数据集构建过程中,研究人员需应对多重难题:如何全面采集并标注来自不同生成模型的最新样本,确保数据集的时效性与代表性;如何设计合理的划分策略,避免数据泄漏,并有效模拟真实场景中的分布外测试;以及如何平衡数据规模与计算资源,在有限样本下构建具备高区分度的基准任务。
常用场景
经典使用场景
在生成式人工智能迅猛发展的时代背景下,OpenFakeTiny数据集聚焦于鉴别AI生成图像的视觉真实性,成为深度伪造检测研究领域的一颗明珠。该数据集精心汇集了来自多种主流图像生成模型的样本,包括扩散模型、生成对抗网络等,并配以详尽的文本提示、模型来源及标注信息。其最经典的使用场景是构建与评估多类别伪造图像分类器,研究人员可基于其标准化的训练-验证-测试划分,训练模型区分真实照片与不同生成模型产出的伪造图像,进而推动视觉内容溯源技术的进步。
解决学术问题
OpenFakeTiny数据集直面数字时代虚假信息泛滥的严峻挑战,系统性地解决了跨模型泛化检测能力不足这一学术痛点。以往伪造检测工作多针对单一生成器设计,难以应对层出不穷的新型生成技术。该数据集通过包含多种模型来源的伪造样本,为研究跨域、跨模型的伪造特征提取提供了标准化评测基准。其构建促进了通用性强的深度伪造检测算法的发展,使学术研究从特定模型识别转向更加普适的视觉真实性判断,对维护数字内容可信度具有深远的理论意义与社会影响。
实际应用
在实际应用层面,OpenFakeTiny数据集为社交媒体平台、新闻机构及法律取证领域提供了坚实的工具支撑。例如,在Reddit等社交网络的内容审核中,该数据集的reddit子集可直接模拟真实场景下的伪造图像流,帮助开发实时鉴伪插件,有效拦截恶意生成的虚假图片传播。此外,数字取证专家可借助基于该数据集训练的模型,在案件调查中快速筛查可疑图像,判断其是否由AI生成,从而辅助证据链的构建,强化司法公正性。
数据集最近研究
最新研究方向
OpenFakeTiny数据集聚焦于生成式图像伪造检测这一前沿领域,其核心配置包含1250条训练、验证及测试样本,涵盖由多种生成模型(如扩散模型、生成对抗网络)产出的图像、对应文本提示及标签信息。当前研究热点集中于利用该数据集评估与提升深度学习模型对AIGC图像的鉴别能力,特别是在跨模型泛化与细粒度伪造溯源方向。伴随着ChatGPT、DALL·E等生成式人工智能的爆发式应用,OpenFakeTiny为虚假图像检测提供标准化基准,对于维护信息生态安全、遏制深度伪造技术滥用具有关键的推动作用。
以上内容由遇见数据集搜集并总结生成


