Yambda-5B
收藏arXiv2025-06-02 更新2025-05-30 收录
下载链接:
https://huggingface.co/datasets/yandex/yambda
下载链接
链接失效反馈官方服务:
资源简介:
Yambda-5B是一个大规模的多模态数据集,来自Yandex.Music流媒体平台,包含1百万用户在939万首曲目上的47.9亿次用户-项目交互。数据集包括两种主要类型的交互:隐式反馈(收听事件)和显式反馈(喜欢、不喜欢、取消喜欢和取消不喜欢)。此外,我们还提供了大多数曲目的音频嵌入,这些嵌入由一个在音频频谱图上训练的卷积神经网络生成。Yambda-5B的一个关键区别特征是包含is_organic标志,该标志将有机用户行为与推荐驱动事件分开。这种区分对于开发和评估机器学习算法至关重要,因为Yandex.Music依赖于推荐系统为用户个性化选择曲目。为了支持严格的基准测试,我们引入了一种基于全局时间分割的评价协议,使推荐算法能够在接近现实世界使用条件的条件下进行评估。我们报告了使用各种评价指标的典型基线(ItemKNN,iALS)和先进模型(SANSA,SASRec)的基准结果。通过将Yambda-5B发布到社区,我们的目标是提供一个易于访问的工业规模资源,以推进研究、促进创新并促进推荐系统中的可重复结果。
Yambda-5B is a large-scale multimodal dataset sourced from the Yandex.Music streaming platform, containing 4.79 billion user-item interactions from 1 million users across 9.39 million tracks. The dataset includes two main types of interactions: implicit feedback (listening events) and explicit feedback (likes, dislikes, unlikes, and undislikes). In addition, we provide audio embeddings for most tracks, which are generated by a convolutional neural network trained on audio spectrograms. A key distinguishing feature of Yambda-5B is the inclusion of the `is_organic` flag, which differentiates organic user behavior from recommendation-driven events. This distinction is critical for developing and evaluating machine learning algorithms, as Yandex.Music relies on recommendation systems to personalize track selections for its users. To support rigorous benchmarking, we introduce an evaluation protocol based on global temporal splitting, which enables recommendation algorithms to be evaluated under conditions closely approximating real-world usage scenarios. We report benchmark results for representative baselines (ItemKNN, iALS) and state-of-the-art models (SANSA, SASRec) using various evaluation metrics. By releasing Yambda-5B to the research community, our goal is to provide an easily accessible industrial-scale resource to advance research, foster innovation, and enable reproducible results in recommendation systems.
提供机构:
Yandex
创建时间:
2025-05-28
原始信息汇总
Yambda-5B数据集概述
基本信息
- 许可证: Apache-2.0
- 标签: recsys, retrieval, dataset
- 数据集名称: Yambda-5B
- 规模: 1B<n<10B
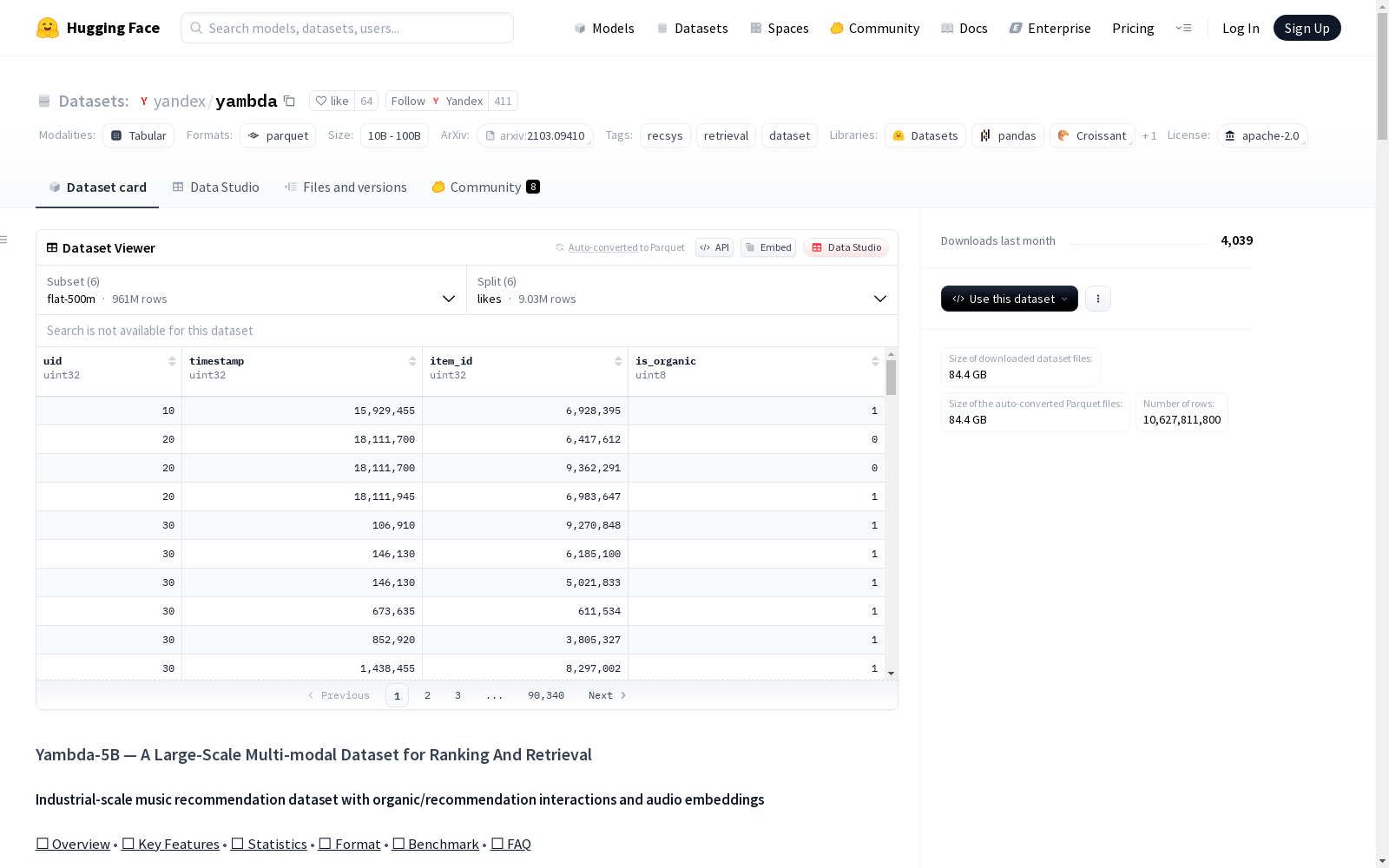
数据集配置
- flat-50m: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
- flat-500m: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
- flat-5b: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
- sequential-50m: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
- sequential-500m: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
- sequential-5b: 包含likes、listens、unlikes、multi_event、dislikes、undislikes的parquet文件
关键特性
- 4.79B用户-音乐交互(包括收听、喜欢、不喜欢、取消喜欢、取消不喜欢)
- 带有全局时间顺序的时间戳
- 7.72M条目的音频嵌入
- 有机和推荐驱动的交互
- 多种数据集规模(50M、500M、5B交互)
- 标准化评估协议和基准测试
数据集统计
| 数据集 | 用户数量 | 项目数量 | 收听次数 | 喜欢次数 | 不喜欢次数 |
|---|---|---|---|---|---|
| Yambda-50M | 10,000 | 934,057 | 46,467,212 | 881,456 | 107,776 |
| Yambda-500M | 100,000 | 3,004,578 | 466,512,103 | 9,033,960 | 1,128,113 |
| Yambda-5B | 1,000,000 | 9,390,623 | 4,649,567,411 | 89,334,605 | 11,579,143 |
数据格式
文件描述
listens.parquet: 用户收听事件,包含播放详情likes.parquet: 用户喜欢行为dislikes.parquet: 用户不喜欢行为undislikes.parquet: 用户取消不喜欢行为unlikes.parquet: 用户取消喜欢行为embeddings.parquet: 曲目音频嵌入
通用事件结构
| 字段 | 类型 | 描述 |
|---|---|---|
uid |
uint32 | 唯一用户标识符 |
item_id |
uint32 | 唯一曲目标识符 |
timestamp |
uint32 | 以5秒为单位的时间戳 |
is_organic |
uint8 | 布尔标志(0/1),表示交互是否为有机(1)或算法推荐(0) |
统一事件结构
| 字段 | 类型 | 描述 |
|---|---|---|
uid |
uint32 | 唯一用户标识符 |
item_id |
uint32 | 唯一曲目标识符 |
timestamp |
uint32 | 以5秒为单位的时间戳 |
is_organic |
uint8 | 布尔标志,表示有机交互 |
event_type |
enum | 事件类型:listen, like, dislike, unlike, undislike |
played_ratio_pct |
Optional[uint16] | 播放百分比(1-100),非收听事件为null |
track_length_seconds |
Optional[uint32] | 曲目总时长(秒),非收听事件为null |
顺序(聚合)格式
| 字段 | 类型 | 描述 |
|---|---|---|
uid |
uint32 | 唯一用户标识符 |
item_ids |
List[uint32] | 交互曲目标识符的时序列表 |
timestamps |
List[uint32] | 对应交互时间戳 |
is_organic |
List[uint8] | 对应交互的有机标志 |
常见问题
- 测试项目是否出现在训练数据中?: 部分出现,部分不出现
- 测试用户是否出现在训练数据中?: 是,测试集中没有冷启动用户
- 音频嵌入如何生成?: 使用基于卷积神经网络的模型生成
is_organic标志的含义?: 表示交互是通过有机发现(True)还是推荐驱动(False)- 哪些事件被视为推荐驱动?: 包括来自个性化音乐源和个性化播放列表的交互
- 什么是“收听”曲目?: 播放超过50%时长的曲目被视为“收听”
搜集汇总
数据集介绍
构建方式
Yambda-5B数据集构建于Yandex.Music音乐流媒体平台的用户交互数据,涵盖了11个月内100万用户与939万曲目间的47.9亿次交互行为。数据采集采用严格的匿名化处理,通过定义用户活跃度阈值(前10个月至少10次交互)进行抽样,并采用5秒精度的时间戳标准化处理。数据集创新性地引入is_organic标志位,区分用户自主行为与推荐系统驱动的交互,同时提供基于卷积神经网络生成的音频嵌入特征,支持多模态研究。数据以Apache Parquet格式存储,包含平面表和时序聚合两种组织形式,确保分布式计算框架的兼容性。
特点
该数据集的核心价值体现在其工业级规模与多维特征集成。作为当前最大的开放音乐交互数据集之一,其47.9亿交互量级远超传统基准(如MovieLens的3200万次)。独特的事件类型划分(播放、喜欢/不喜欢及其撤销行为)与有机行为标注,为研究推荐系统反馈环路提供了细粒度分析基础。音频嵌入特征通过对比学习生成,支持内容感知的推荐算法开发。全局时间分割评估协议(训练300天/测试1天+30分钟缓冲)严格模拟工业场景,有效防止时序数据泄露。数据分布呈现典型的长尾特性,头部曲目与稀疏交互的尾部形成鲜明对比,真实反映了音乐流媒体平台的物品流行度分布。
使用方法
研究者可通过Hugging Face平台获取完整数据集及其两个子采样版本(Yambda-500M/Yambda-50M)。推荐采用Global Temporal Split协议进行模型验证,重点关注NDCG@K和Recall@K等排序指标。对于序列建模任务,建议使用时序聚合格式数据,利用多事件类型联合文件(multi_event.parquet)构建用户行为序列。音频嵌入特征可与交互数据联合训练,开发跨模态推荐模型。基准代码库提供ItemKNN、iALS等传统算法与SASRec等序列模型的实现,支持OPTUNA框架的超参数优化。特别注意区分有机行为与推荐驱动事件,可开展推荐系统偏差影响等前沿研究。
背景与挑战
背景概述
Yambda-5B数据集由Yandex团队于2025年发布,是一个专注于音乐推荐系统研究的大规模多模态数据集。该数据集源自Yandex.Music流媒体平台,包含47.9亿条用户-项目交互记录,覆盖100万用户和939万首曲目。其核心研究问题在于解决音乐推荐领域中的数据稀疏性和算法可扩展性挑战,通过提供有机行为与推荐驱动行为的区分标记(is_organic),为研究推荐系统的反馈循环效应提供了独特视角。该数据集以其工业级规模和精细的时间戳设计(5秒精度),显著推进了序列推荐和跨模态推荐的研究边界,成为连接学术研究与工业实践的重要桥梁。
当前挑战
Yambda-5B面临的挑战主要体现在两个方面:领域问题方面,音乐推荐系统需解决极端数据稀疏性(长尾曲目覆盖)与动态兴趣演化的平衡,同时需区分算法推荐对用户行为的潜在偏置影响;构建过程方面,数据匿名化处理导致部分元信息损失,多模态特征(音频嵌入与行为序列)的对齐需要复杂预处理,而维持47.9亿交互事件的时间一致性则对分布式存储架构提出苛刻要求。此外,全球时间分割评估协议的设计需规避数据泄漏风险,这对基准测试的可靠性构成显著挑战。
常用场景
经典使用场景
Yambda-5B数据集在音乐推荐系统研究中扮演着重要角色,尤其在处理大规模用户-项目交互数据时表现出色。该数据集通过提供丰富的隐式和显式反馈,包括用户收听事件、喜欢、不喜欢等行为,为研究者提供了一个真实的工业级数据环境。其独特的is_organic标志进一步区分了用户自发行为与推荐系统驱动的行为,使得研究能够更精确地分析推荐算法的影响。
实际应用
在实际应用中,Yambda-5B数据集被广泛用于音乐流媒体平台的推荐系统优化。例如,平台可以利用该数据集中的用户行为数据训练个性化推荐模型,提升用户体验和参与度。此外,数据集中的有机行为与推荐行为区分有助于平台评估推荐算法的实际影响,从而优化算法策略。
衍生相关工作
Yambda-5B的发布催生了一系列相关研究,特别是在大规模序列推荐和多模态推荐领域。例如,基于该数据集的SANSA和SASRec等模型在序列推荐任务中表现出色。此外,研究者还利用该数据集探索了音频嵌入与用户行为的关联,推动了多模态推荐算法的发展。
以上内容由遇见数据集搜集并总结生成


