有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
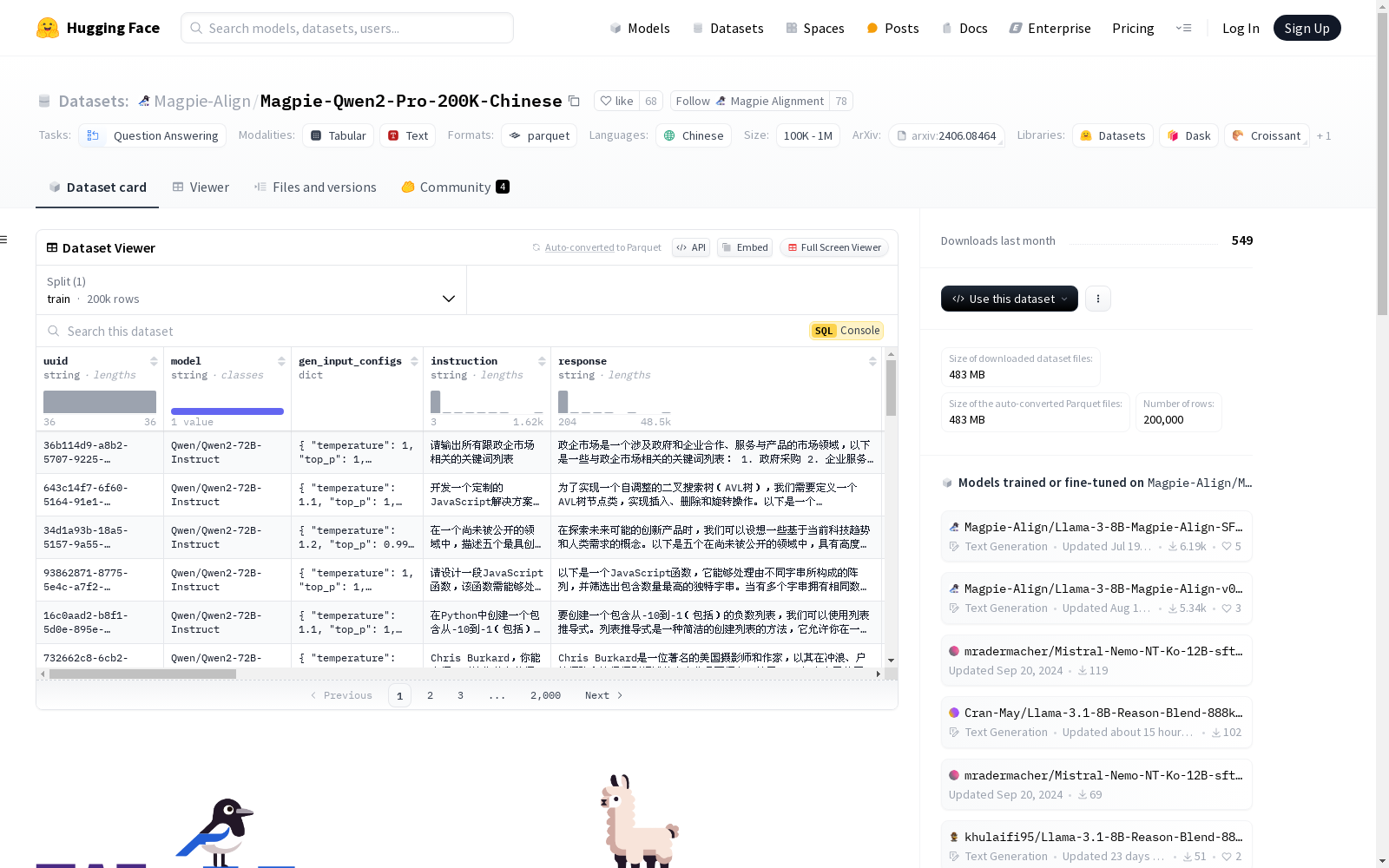
特征列表:
uuid: 字符串model: 字符串gen_input_configs: 结构体
temperature: 浮点数top_p: 浮点数input_generator: 字符串seed: 空extract_input: 字符串instruction: 字符串response: 字符串conversations: 列表
from: 字符串value: 字符串task_category: 字符串other_task_category: 序列字符串task_category_generator: 字符串difficulty: 字符串intent: 字符串knowledge: 字符串difficulty_generator: 字符串input_quality: 字符串quality_explanation: 字符串quality_generator: 字符串llama_guard_2: 字符串reward_model: 字符串instruct_reward: 浮点数min_neighbor_distance: 浮点数repeat_count: 整数min_similar_uuid: 字符串instruction_length: 整数response_length: 整数language: 字符串数据分割:
train: 200,000个样本,大小为898,262,675.9375356字节下载大小: 483,456,525字节
数据集大小: 898,262,675.9375356字节
data/train-*| 模型名称 | 数据集 | 类型 | 描述 |
|---|---|---|---|
| Qwen2 72B Instruct | Magpie-Qwen2-Pro-1M | SFT | 使用Qwen2 72B Instruct构建的1M原始对话 |
| Qwen2 72B Instruct | Magpie-Qwen2-Pro-300K-Filtered | SFT | 应用过滤器并选择300K高质量对话 |
| Qwen2 72B Instruct | Magpie-Qwen2-Pro-200K-Chinese | SFT | 应用过滤器并选择200K高质量中文对话 |
| Qwen2 72B Instruct | Magpie-Qwen2-Pro-200K-English | SFT | 应用过滤器并选择200K高质量英语对话 |
LEGO数据集
该数据集包含了关于LEGO公司的历史、产品提供以及特定LEGO套装的信息,用于分析LEGO套装的规模、发布年份、主题分布以及套装复杂性的变化。
github 收录
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
中国行政区划数据
本项目为中国行政区划数据,包括省级、地级、县级、乡级和村级五级行政区划数据。数据来源于国家统计局,存储格式为sqlite3 db文件,支持直接使用数据库连接工具打开。
github 收录
HazyDet
HazyDet是由解放军工程大学等机构创建的一个大规模数据集,专门用于雾霾场景下的无人机视角物体检测。该数据集包含383,000个真实世界实例,收集自自然雾霾环境和正常场景中人工添加的雾霾效果,以模拟恶劣天气条件。数据集的创建过程结合了深度估计和大气散射模型,确保了数据的真实性和多样性。HazyDet主要应用于无人机在恶劣天气条件下的物体检测,旨在提高无人机在复杂环境中的感知能力。
arXiv 收录