depinwang/rnaseq-aligner-toy-benchmark-metrics-v2-h2sweep
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/depinwang/rnaseq-aligner-toy-benchmark-metrics-v2-h2sweep
下载链接
链接失效反馈官方服务:
资源简介:
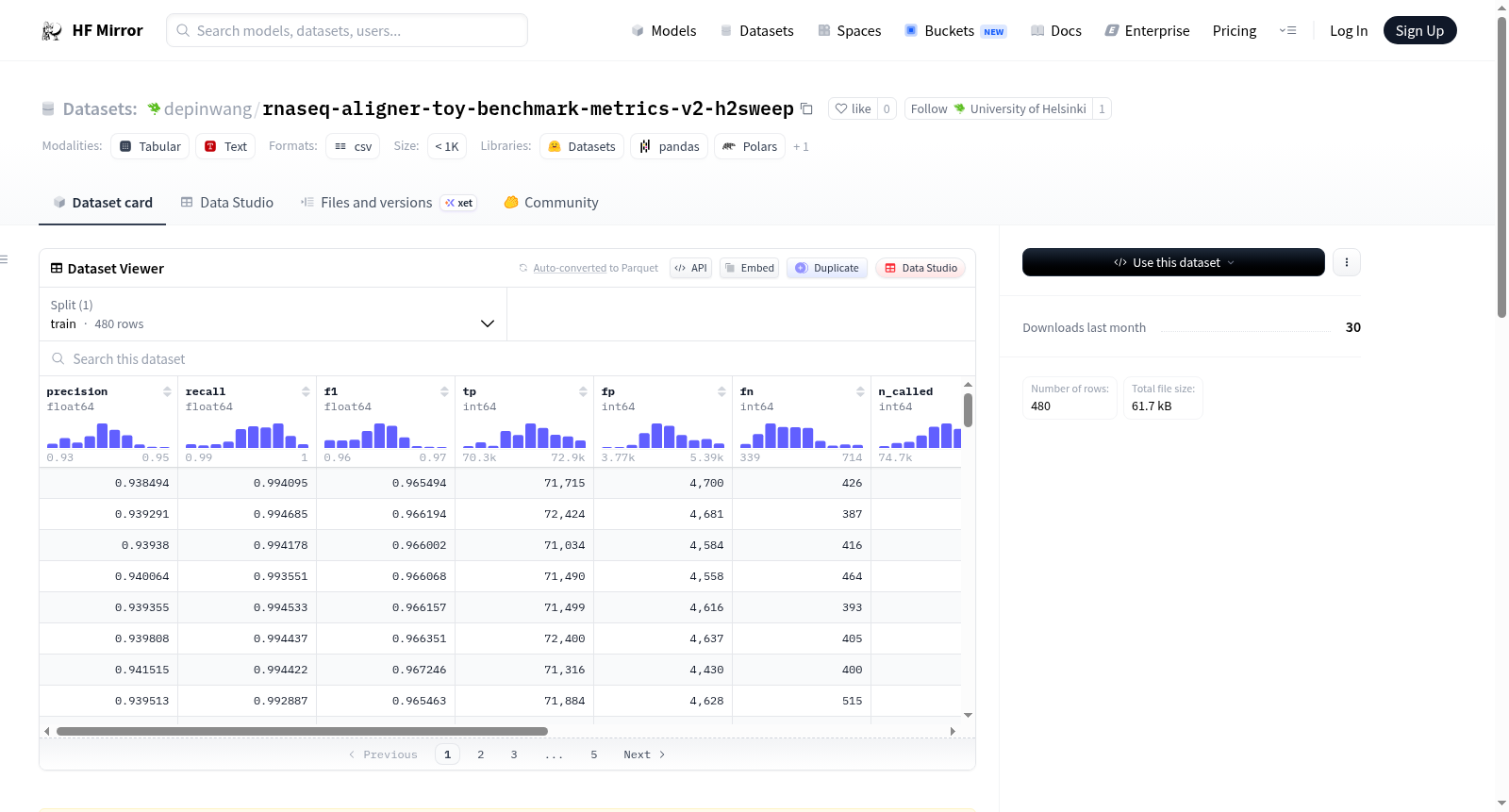
该数据集用于评估不同RNA-seq比对工具(star, hisat2, subjunc, bwa-mem2, minimap2)在模拟GRCh38 RNA-seq reads上的性能,特别是剪接连接点的F1分数、精确度和召回率。数据集包含480行数据,每行记录了一个比对工具在特定样本上的性能指标,包括真阳性、假阳性、假阴性、总调用连接点、总真实连接点等。数据来源包括rna-seq比对工具基准测试实验、Puhti集群、GRCh38.primary_assembly参考基因组和GENCODE v45转录本,以及模拟和评分方法。
This dataset benchmarks RNA-seq aligners (star, hisat2, subjunc, bwa-mem2, minimap2) on simulated GRCh38 RNA-seq reads, specifically measuring splice-junction F1/precision/recall against GENCODE v45 ground-truth introns. It contains 480 rows of per-aligner, per-sample metrics including TP/FP/FN counts, total called/truth junctions, and read-support filters. Data provenance includes the rnaseq-aligner-toy-benchmark experiment, Puhti cluster, GRCh38.primary_assembly + GENCODE v45 reference, uniform transcript sampling simulation, and exact-tuple-match scoring with min_reads=3.
提供机构:
depinwang
搜集汇总
数据集介绍
构建方式
本数据集源于对RNA-seq比对器性能的系统性评估实验,基于GRCh38参考基因组与GENCODE v45转录本注释的真值内含子集合,通过模拟生成RNA-seq读段,并采用五种主流比对器(STAR、HISAT2、Subjunc、BWA-MEM2、Minimap2)进行比对,随后经自研评分脚本(score_junctions.py)以精确元组匹配模式计算剪接连接位点的精确率、召回率与F1值,数据集共包含480条记录,每条记录对应特定比对器与样本的组合,并记录了真阳性、假阳性、假阴性等详细指标。
特点
该数据集的核心特点在于其专注于剪接连接位点级别的比对精度评估,而非传统的读段比对率,提供了F1值、精确率、召回率等多维质量指标,同时保留了真阳性、假阳性、假阴性等计数信息,便于用户进行深入的错误分析。数据还标注了比对器名称、样本标识、数据集来源及应用于连接位点调用的最小读段支持数过滤阈值,使得不同比对策略的差异一目了然。
使用方法
用户可将该JSON格式数据集直接加载至Python环境(如Pandas DataFrame),通过按比对器分组计算平均F1值或精确率召回率曲线,比较不同工具的剪接检测能力。亦可利用真阳性与假阳性计数进行统计检验,或根据最小读段过滤阈值进行子集分析,以探讨严格度对性能的影响。该数据适用于RNA-seq比对算法的基准测试、方法学比较以及剪接检测流程的优化研究。
背景与挑战
背景概述
RNA测序(RNA-seq)是转录组研究的重要技术,其核心步骤之一是将测序产生的短读段比对至参考基因组,而比对结果的准确性直接影响下游基因表达定量、可变剪接鉴定等分析的可靠性。为系统评估不同比对工具在剪接位点识别上的性能,该数据集由芬兰CSC(IT科学中心)团队于近年创建,依托普赫蒂(Puhti)高性能计算集群,基于GRCh38初级组装参考基因组与GENCODE v45转录本注释,通过无错误模型的均匀采样模拟RNA-seq读段,收集了STAR、HISAT2、Subjunc、BWA-MEM2及Minimap2五种主流比对器在480个样本上的剪接连接点精确率、召回率和F1值等指标。该数据集填补了缺乏统一、标准化比对性能基准的空白,为RNA-seq比对工具的客观比较与算法优化提供了可重复的评估框架,推动了转录组分析技术向更高精度发展。
当前挑战
该数据集主要解决的领域问题是RNA-seq读段比对中剪接连接点检测的精度评估挑战:由于真核生物基因存在内含子剪接,比对器需准确跨越剪接位点,但现有工具在复杂转录本(如可变剪接、重复区域)上常产生假阳性或遗漏真实剪接事件,影响生物学发现的可靠性。构建过程中面临多重挑战:首先,模拟读段的真实参考定义需高度精确,依赖GENCODE v45高质量注释,但注释本身在非编码RNA或罕见剪接亚型上可能存在不完整性;其次,无错误模型简化了真实测序误差、碱基质量变异等复杂因素,可能高估比对器性能;最后,剪接连接点的匹配标准采用精确元组比对,虽严格控制假阳性,却难以容忍读段比对中的微小偏差,导致部分真实连接可能因技术噪声被误判为假阴性。
常用场景
经典使用场景
在转录组学研究领域,准确比对RNA测序读段至参考基因组是解析基因表达与剪接异构体的基石。该数据集专为评估不同RNA-seq比对工具在剪接连接点检测上的性能而设计,其经典使用场景在于通过模拟GRCh38参考基因组上的读段,基于GENCODE v45注释的真实剪接连接点,系统性地比较STAR、HISAT2、Subjunc、BWA-MEM2及Minimap2等主流比对器的精确率、召回率与F1分数。研究者可借助此数据集量化各工具在无错误模拟条件下的本征表现,从而为特定实验设计选择最优比对策略提供定量依据。
衍生相关工作
围绕此基准测试数据集,学术界已衍生出多项经典工作。其中,基于其指标体系的研究深入剖析了读段长度、测序深度与比对参数对剪接连接点检测的影响,促进了如STAR的改进版本在小型参考基因组上的适配。另一些工作则将该评估框架扩展至包含测序错误模型与多物种背景,催生了更具鲁棒性的模拟数据生成工具。此外,该数据集引导了集成学习方法的兴起——通过融合多个比对器的结果以提升整体剪接检测的稳定性,相关算法已在长读长RNA-seq与单细胞转录组分析中得到验证。这些衍生工作共同巩固了该数据集作为RNA-seq比对评估领域标杆的地位。
数据集最近研究
最新研究方向
该数据集聚焦于RNA-seq比对工具在剪接连接点检测上的精准度评估,为精准医学和转录组学研究提供了关键基准。基于GRCh38参考基因组和GENCODE v45注释,通过模拟读取对STAR、HISAT2等五种主流比对器进行F1分数、精确率和召回率的系统对比,揭示了不同比对策略在处理剪接事件时的性能差异。在长读长测序和单细胞RNA-seq蓬勃发展的当下,该基准测试对于优化比对算法、降低假阳性率具有现实意义,特别有助于解析可变剪接在疾病机制中的作用。其可复现的实验设计和开源指标为开发更敏感的剪接检测方法奠定了基础,也呼应了近年来对RNA-seq分析标准化和可重复性的迫切需求。
以上内容由遇见数据集搜集并总结生成


