top_5_insurance_brands_june_news_and_twitter_only
收藏Hugging Face2024-08-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/chwenjun225/top_5_insurance_brands_june_news_and_twitter_only
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了2021年6月排名前五的保险品牌的新闻和Twitter内容。数据集的规模、包含的数据类型以及其他相关信息在摘要中有所描述。数据集支持的任务和相关排行榜在支持的任务部分列出。数据集使用英语,其结构包括数据实例、数据字段和数据分割。数据集的创建原因、源数据收集和归一化、数据生产者和标注者的信息在创建部分详细说明。数据集可能包含的个人和敏感信息、社会影响、已知偏见和其他已知限制在使用注意事项中讨论。数据集的策展人、许可信息、引用信息和贡献方式在额外信息部分提供。
创建时间:
2024-08-03
原始信息汇总
Top 5 Insurance Brands June News and Twitter Only
数据集概述
该数据集包含关于前五大保险品牌在六月份的新闻和Twitter数据。数据集的具体大小、数据类型和其他相关信息未在README文件中详细说明。
支持的任务和排行榜
数据集支持的任务及其相关排行榜未在README文件中详细说明。
语言
数据集中的文本语言为英语。
数据集结构
数据实例
数据实例的具体示例未在README文件中提供。
数据字段
数据集中的字段未在README文件中详细说明。
数据分割
数据集如何分割为训练集、验证集和测试集未在README文件中详细说明。
数据集创建
创建理由
数据集创建的具体理由未在README文件中详细说明。
源数据
- 初始数据收集和规范化: 数据收集和规范化的具体方法未在README文件中详细说明。
- 源数据生产者: 数据生产者的具体信息未在README文件中详细说明。
注释
- 注释过程: 注释过程的具体方法未在README文件中详细说明。
- 注释者: 注释者的具体信息未在README文件中详细说明。
个人和敏感信息
数据集中是否包含个人或敏感信息未在README文件中详细说明。
使用数据的注意事项
数据集的社会影响
数据集的潜在社会影响未在README文件中详细说明。
数据集的偏见
数据集中已知的偏见未在README文件中详细说明。
其他已知限制
数据集的其他已知限制未在README文件中详细说明。
附加信息
数据集策展人
数据集策展人的具体信息未在README文件中详细说明。
许可信息
数据集的许可信息为cc。
引用信息
数据集的引用信息未在README文件中详细说明。
贡献
如何向数据集贡献的具体方法未在README文件中详细说明。
示例用法
以下是使用Hugging Face库加载和使用数据集的示例:
python from datasets import load_dataset
dataset = load_dataset("your_dataset_name")
示例用法
print(dataset["train"][0])
搜集汇总
数据集介绍
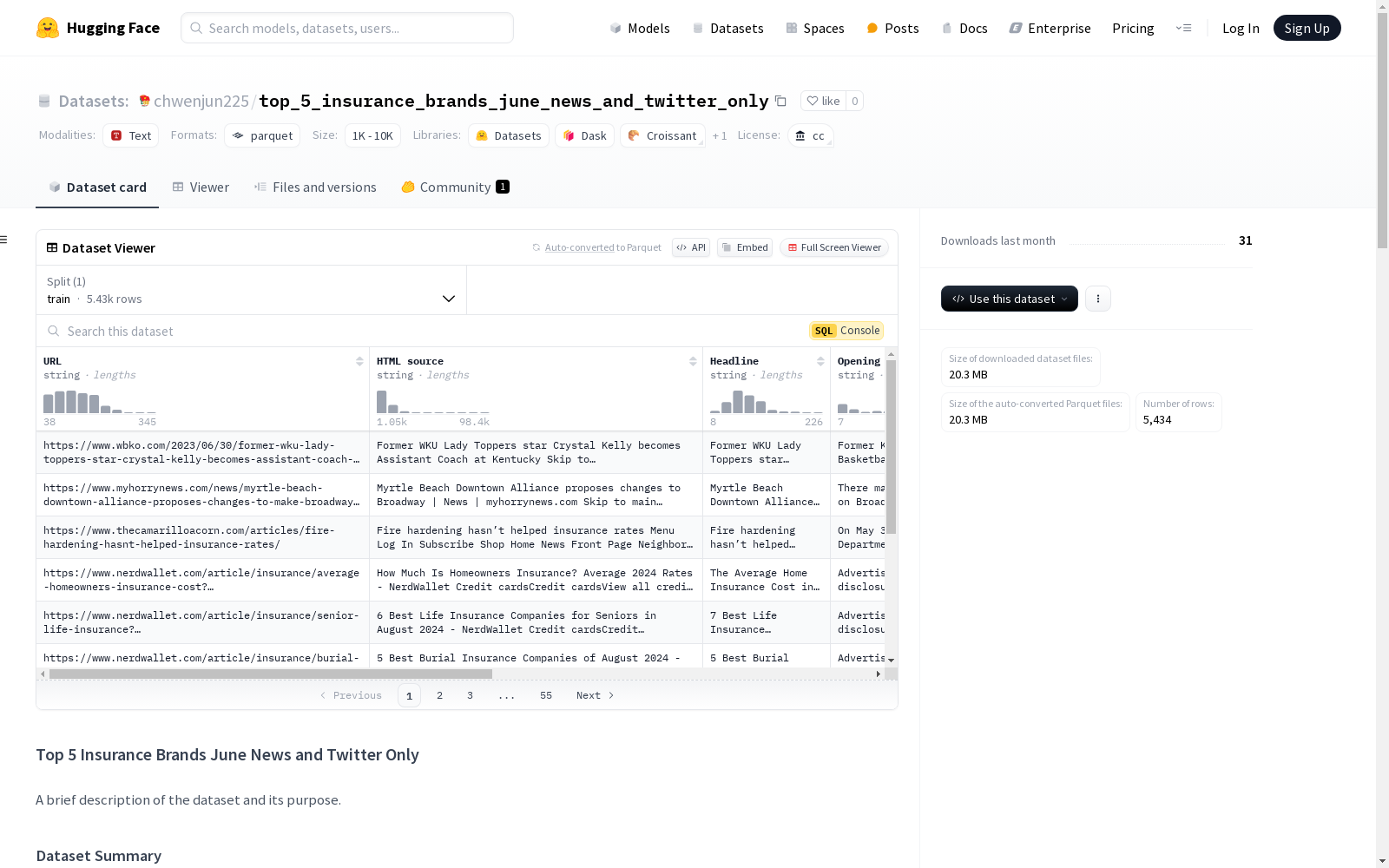
构建方式
该数据集聚焦于保险行业,通过收集六月份与五大保险品牌相关的新闻和Twitter数据构建而成。数据来源包括公开的新闻报道和社交媒体平台,经过初步的收集和标准化处理,确保数据的多样性和代表性。数据集的构建旨在捕捉特定时间段内公众对保险品牌的关注和讨论,为相关研究提供基础数据支持。
使用方法
该数据集可通过Hugging Face库加载,用户可以使用Python代码轻松访问数据。加载后,数据集分为训练、验证和测试集,用户可根据需求进行模型训练和评估。示例代码展示了如何加载数据集并查看第一条数据实例,便于快速上手和进一步分析。
背景与挑战
背景概述
在保险行业,品牌声誉和公众舆论对企业的市场表现具有深远影响。'top_5_insurance_brands_june_news_and_twitter_only'数据集由相关研究机构于近期创建,旨在通过分析新闻和社交媒体数据,揭示保险品牌在公众视野中的表现。该数据集聚焦于五大保险品牌,涵盖了六月份的新闻和Twitter数据,为研究人员提供了丰富的文本资源,以探索品牌声誉管理、消费者情感分析等核心问题。这一数据集的推出,不仅为保险行业的市场分析提供了新的视角,也为自然语言处理领域的研究者提供了宝贵的实验数据。
当前挑战
该数据集在解决保险品牌声誉分析问题时,面临多重挑战。首先,新闻和社交媒体数据的多样性和动态性使得情感分析和品牌声誉评估变得复杂,尤其是在处理非结构化文本时,如何准确提取关键信息成为一大难题。其次,数据集的构建过程中,数据收集和标准化处理面临技术挑战,尤其是在处理来自不同来源的异构数据时,如何确保数据的一致性和质量是一个关键问题。此外,社交媒体数据中的噪声和偏见也可能影响分析结果的准确性,如何有效去除这些干扰因素,是数据集使用过程中需要克服的另一大挑战。
常用场景
经典使用场景
在保险行业的市场分析和品牌声誉管理中,'top_5_insurance_brands_june_news_and_twitter_only'数据集提供了一个独特的视角。通过分析新闻和社交媒体上的数据,研究人员可以追踪和评估顶级保险品牌在特定时间段内的公众形象和媒体曝光度。这种分析对于理解品牌如何通过不同的媒体渠道影响消费者认知至关重要。
解决学术问题
该数据集解决了保险行业中品牌管理和市场策略研究的关键问题。通过提供详细的新闻和社交媒体数据,研究人员能够深入分析品牌声誉的动态变化,评估不同市场策略的有效性,以及预测市场趋势。这些分析为学术界提供了丰富的数据支持,推动了品牌管理和市场营销理论的发展。
实际应用
在实际应用中,该数据集被广泛用于保险公司的市场分析部门,帮助他们监控品牌声誉,优化广告策略,以及进行竞争对手分析。此外,数据科学家和市场营销专家利用这些数据来构建预测模型,以指导未来的市场决策和品牌定位。
数据集最近研究
最新研究方向
在保险行业与社交媒体分析的交汇领域,'top_5_insurance_brands_june_news_and_twitter_only'数据集为研究者提供了独特的视角。该数据集聚焦于五大保险品牌在六月份的新闻和推特数据,为分析品牌声誉、市场趋势和消费者行为提供了丰富的信息源。近年来,随着社交媒体影响力的扩大,如何利用这些数据来预测市场动态、评估品牌健康度以及优化营销策略成为了研究热点。该数据集的应用不仅限于传统的市场分析,还扩展到了情感分析、舆论监控以及危机管理等多个前沿方向。通过深入挖掘这些数据,研究者能够更准确地把握保险行业的脉搏,为政策制定和商业决策提供科学依据。
以上内容由遇见数据集搜集并总结生成


