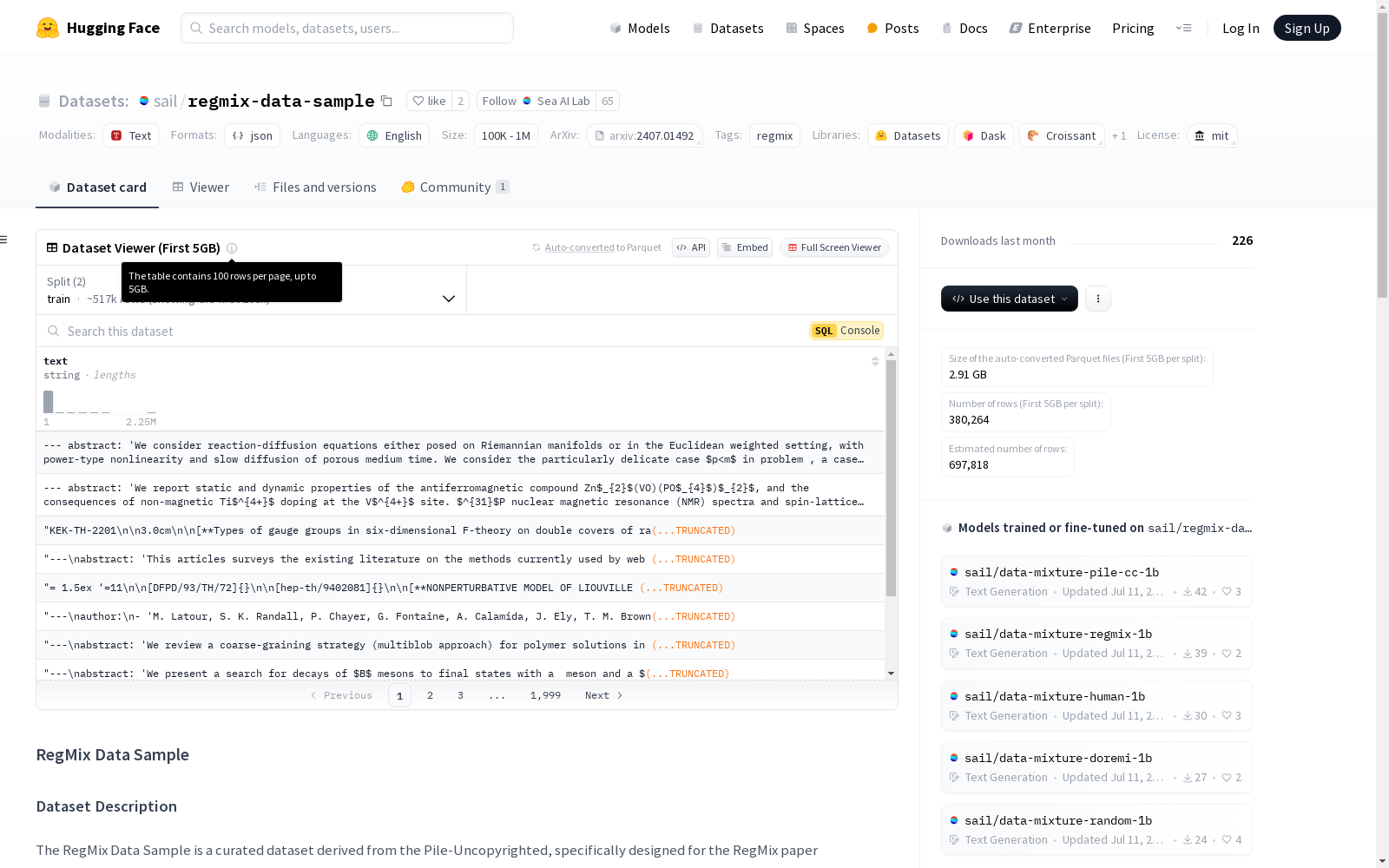
regmix-data-sample
收藏RegMix Data Sample
数据集描述
RegMix Data Sample 是从 Pile-Uncopyrighted 数据集中精心挑选的数据集,专门为 RegMix 论文设计。该数据集旨在通过将语言模型预训练中的高性能数据混合识别问题转化为回归任务,从而促进自动识别。
关键特性:
- 大小:约 20GB 磁盘空间,50 亿个标记
- 分布:遵循领域示例的自然标记分布
- 组织:不同领域的示例被分离到单独的文件中
数据集结构
数据集分为两个主要目录:train 和 valid,每个目录包含特定领域的 JSONL 文件。文件命名约定如下:
[domain]-[identifier]-[number].jsonl
例如:arxiv-10-74305611.jsonl
包含的领域:
arxiv, gutenberg_pg_19, pubmed_central, dm_mathematics, hackernews, stackexchange, enron_emails, nih_exporter, ubuntu_irc, europarl, philpapers, uspto_backgrounds, freelaw, pile_cc, wikipedia_en, github, pubmed_abstracts
使用方法
建议下载整个数据集快照,而不是使用传统的 load_dataset 函数,因为 RegMix 代码与 TinyLlama 框架 集成。
下载数据集的代码如下:
python from huggingface_hub import snapshot_download
LOCAL_DIR = "regmix-data-sample" snapshot_download(repo_id="sail/regmix-data-sample", repo_type=dataset, local_dir=LOCAL_DIR, local_dir_use_symlinks=False)
这将下载整个快照,包含 34 个 JSON 行文件(17 个用于训练,17 个用于验证),到指定的本地目录。
数据预处理
我们的 代码 将这些领域文件预处理为带有领域前缀的二进制格式。它允许使用用户定义的数据混合(即领域权重)进行随机抽样。
致谢
我们感谢 Pile-Uncopyrighted 数据集 的创建者,他们努力从原始 Pile 数据集中移除受版权保护的内容,使这项工作成为可能。
引用
如果您在研究中使用此数据集,请引用 RegMix 论文:
@article{liu2024regmix, title={RegMix: Data Mixture as Regression for Language Model Pre-training}, author={Liu, Qian and Zheng, Xiaosen and Muennighoff, Niklas and Zeng, Guangtao and Dou, Longxu and Pang, Tianyu and Jiang, Jing and Lin, Min}, journal={arXiv preprint arXiv:2407.01492}, year={2024} }
有关 RegMix 方法及其应用的更多信息,请参阅 原始论文。