COVID20K2C-Superpixels-Dataset
收藏github2020-09-10 更新2024-05-31 收录
下载链接:
https://github.com/EvertonTetila/COVID20K2C-Superpixels-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
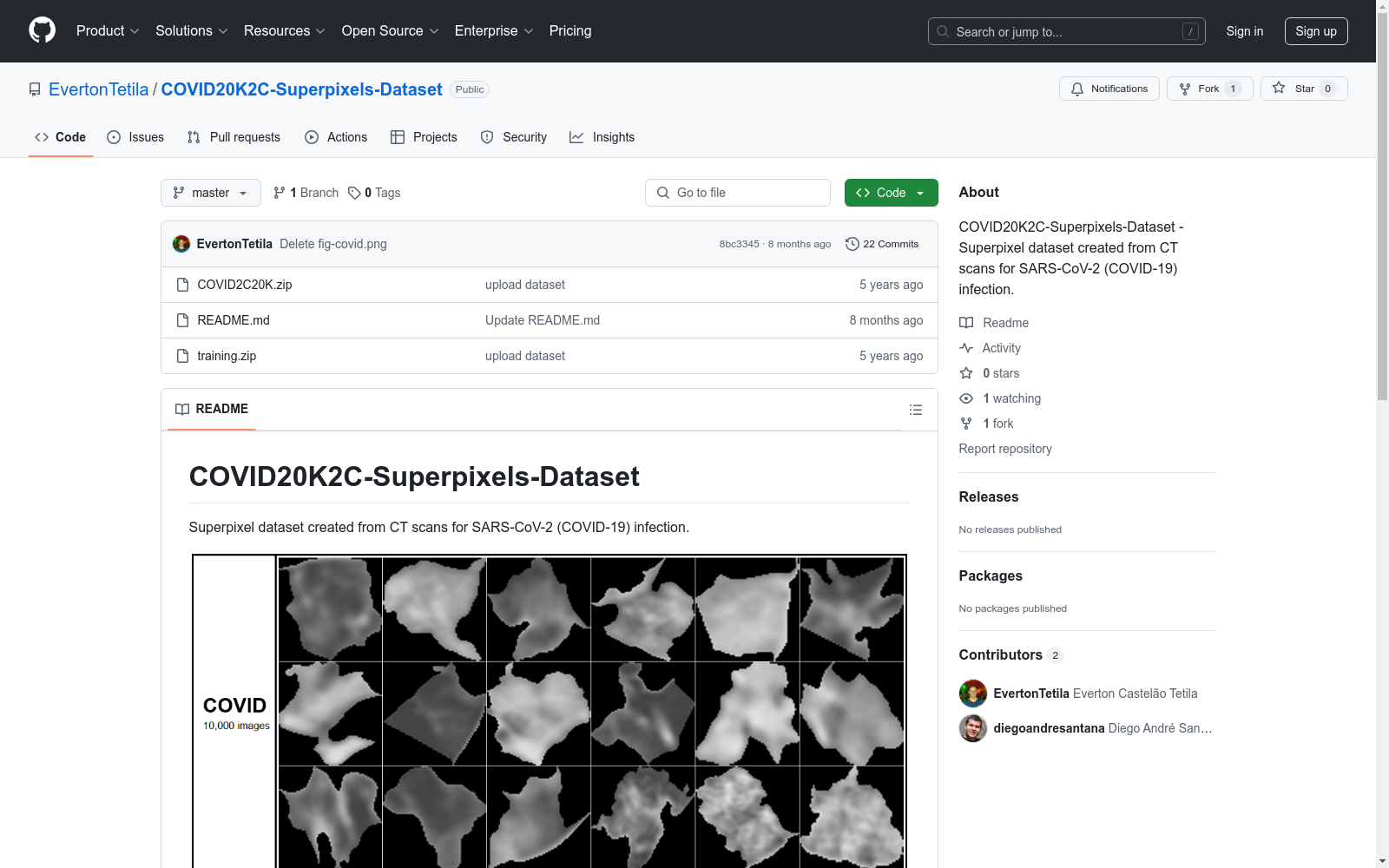
该数据集由SARS-CoV-2(COVID-19)感染阳性CT扫描创建的超级像素图像组成。数据集包含20,000个超级像素图像,分为两类,每类包含10,000个超级像素。COVID类包含具有COVID-19引起的肺部感染特征的超级像素,而非COVID类包含肺部其他区域的超级像素。所有超级像素均由资深放射科医生标记。
This dataset comprises superpixel images generated from CT scans of individuals testing positive for SARS-CoV-2 (COVID-19). It includes 20,000 superpixel images, evenly divided into two categories, each containing 10,000 superpixels. The COVID category features superpixels that exhibit characteristics of lung infections caused by COVID-19, whereas the non-COVID category includes superpixels from other areas of the lungs. All superpixels have been annotated by experienced radiologists.
创建时间:
2020-09-03
原始信息汇总
COVID20K2C-Superpixels-Dataset概述
数据集描述
- 来源:该数据集由胸部CT扫描创建,源自公开数据集SARS-COV-2-Ct-Scan-Dataset。
- 原始数据:包含1252例COVID-19阳性CT扫描和1230例非感染CT扫描,总计2482例CT扫描。
- 采集地点:巴西圣保罗的医院。
数据处理
- 分割方法:使用SLIC Superpixels方法对每个CT图像进行分割。
- 标签:由资深放射科医生随机选择并标记10,000个超像素段,分为两类。
数据集构成
- 类别:COVID和non-COVID两类。
- 数量:每类包含10,000个超像素图像,总计20,000个超像素图像。
- 标签:所有超像素均由资深放射科医生标记。
数据集用途
- 目的:用于基于超像素的深度学习和胸部CT的COVID-19相关肺炎定量诊断系统。
搜集汇总
数据集介绍
构建方式
COVID20K2C-Superpixels-Dataset的构建基于公开的SARS-COV-2-Ct-Scan-Dataset,该源数据集包含2482张胸部CT扫描图像,其中1252张为SARS-CoV-2感染阳性,1230张为阴性。这些数据来自巴西圣保罗医院的真实患者。通过SLIC超像素方法对每张CT图像进行分割,并由资深放射科医生随机选择并标记了每个类别的10,000个超像素,最终形成了包含20,000个超像素图像的数据集。
特点
COVID20K2C-Superpixels-Dataset包含20,000个超像素图像,分为COVID和非COVID两类,每类各10,000个超像素。COVID类超像素具有COVID-19引起的肺部感染特征,而非COVID类则包含肺部其他区域的超像素。所有超像素均经过资深放射科医生的专业标注,确保了数据的准确性和可靠性。
使用方法
该数据集可用于训练和评估基于深度学习的COVID-19肺炎定量诊断系统。研究人员可以通过加载数据集中的超像素图像,结合深度学习模型进行特征提取和分类任务。数据集的标注信息为模型训练提供了高质量的监督信号,有助于提升诊断系统的性能。此外,数据集还可用于研究超像素分割在医学图像分析中的应用效果。
背景与挑战
背景概述
COVID20K2C-Superpixels-Dataset是一个基于胸部CT扫描的超像素数据集,专门用于研究SARS-CoV-2(COVID-19)感染的肺部特征。该数据集由巴西圣保罗医院的真实患者数据构建而成,源自公开的SARS-COV-2-Ct-Scan-Dataset,包含2482张CT扫描图像,其中1252张为COVID-19阳性,1230张为阴性。通过SLIC超像素方法对每张CT图像进行分割,并由资深放射科医生对随机选择的超像素进行标注,最终生成了包含20,000个超像素图像的数据集,分为COVID和非COVID两类。该数据集由TETILA等人于2023年创建,旨在支持基于深度学习的COVID-19肺炎定量诊断研究,为医学影像分析领域提供了重要的数据支持。
当前挑战
COVID20K2C-Superpixels-Dataset的构建与应用面临多重挑战。首先,在领域问题层面,COVID-19肺炎的影像特征复杂且多样,如何从超像素中准确提取与感染相关的特征仍是一个难题。其次,数据标注的准确性高度依赖放射科医生的专业判断,可能存在主观偏差。在构建过程中,SLIC超像素分割方法虽然能够有效减少数据维度,但其对图像细节的保留能力有限,可能导致部分关键信息的丢失。此外,数据集的样本量虽然较大,但其来源局限于单一地区,可能影响模型的泛化能力。这些挑战为后续研究提供了改进方向,同时也凸显了该数据集在医学影像分析中的重要性。
常用场景
经典使用场景
COVID20K2C-Superpixels-Dataset数据集主要用于医学影像分析领域,特别是在COVID-19相关肺炎的定量诊断研究中。该数据集通过SLIC超像素方法对胸部CT扫描图像进行分割,生成了20,000个超像素图像,分为COVID和非COVID两类。这些图像由资深放射科医生标注,为深度学习模型提供了高质量的标注数据,广泛应用于肺部感染区域的自动识别和分类任务。
解决学术问题
该数据集解决了COVID-19肺炎诊断中的关键学术问题,特别是如何从复杂的CT图像中精确识别感染区域。通过提供大量标注的超像素数据,研究人员能够训练更准确的深度学习模型,提升自动化诊断系统的性能。这不仅减少了人工诊断的工作量,还提高了诊断的准确性和效率,为COVID-19的早期筛查和治疗提供了重要支持。
衍生相关工作
基于COVID20K2C-Superpixels-Dataset,研究人员开发了多种深度学习模型,如卷积神经网络(CNN)和生成对抗网络(GAN),用于肺部感染的自动检测和分类。这些模型在多个国际医学影像竞赛中取得了优异成绩,并推动了医学影像分析领域的技术进步。此外,该数据集还促进了跨学科合作,推动了人工智能在医疗领域的广泛应用。
以上内容由遇见数据集搜集并总结生成


