FIBER
收藏arXiv2024-12-31 更新2025-01-06 收录
下载链接:
https://fiber-bench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
FIBER是一个细粒度的视频-文本检索基准数据集,由南京大学和上海人工智能实验室联合创建。该数据集包含1000个视频,来源于FineAction数据集,每个视频都配备了高质量的人工注释,涵盖了视频的静态场景、动态动作、拍摄风格等多方面细节。数据集的注释分为空间和时间两部分,能够独立评估模型的空间和时间偏差。FIBER旨在解决现有视频检索基准在细粒度检索能力评估上的不足,特别适用于评估多模态大语言模型在视频检索任务中的表现。
FIBER is a fine-grained video-text retrieval benchmark dataset jointly created by Nanjing University and Shanghai AI Laboratory. This dataset includes 1000 videos sourced from the FineAction dataset, each paired with high-quality manual annotations covering multiple details such as the video's static scenes, dynamic actions, shooting styles and other aspects. The annotations of the dataset are divided into spatial and temporal parts, which can independently evaluate the spatial and temporal biases of models. FIBER aims to address the shortcomings of existing video retrieval benchmarks in evaluating fine-grained retrieval capabilities, and is particularly suitable for assessing the performance of multimodal large language models in video retrieval tasks.
提供机构:
南京大学 软件新技术国家重点实验室, 上海人工智能实验室
创建时间:
2024-12-31
搜集汇总
数据集介绍
构建方式
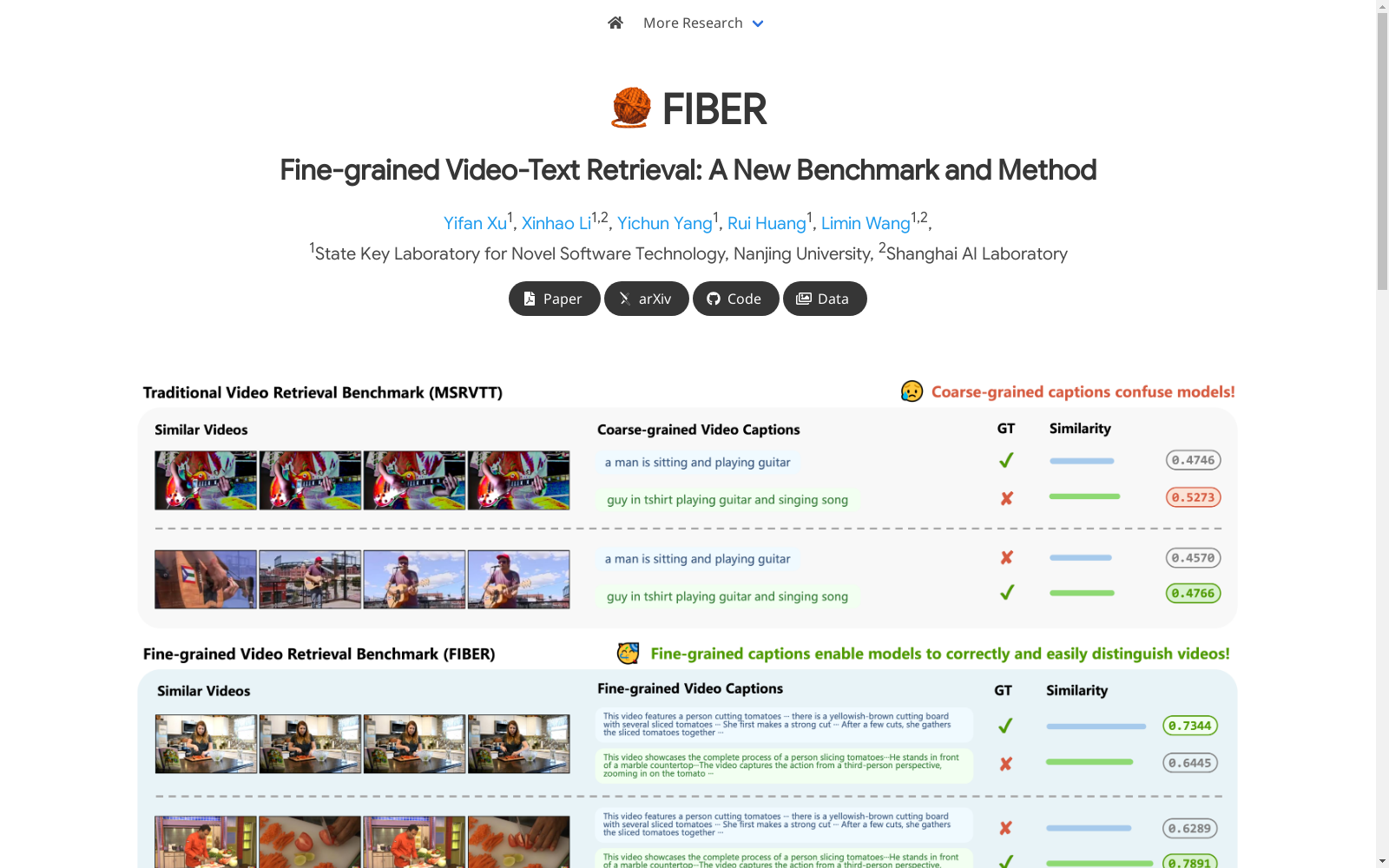
FIBER数据集的构建基于FineAction数据集,包含1000个视频,每个视频均经过人工标注,提供了详细的时空注释。标注过程分为两个阶段:第一阶段,标注者生成包含视频整体概述、场景描述、动作描述和杂项描述的四部分详细注释;第二阶段,标注者将这些注释进一步分离为空间描述和时间描述,以确保模型能够独立评估时空偏差。
特点
FIBER数据集的特点在于其细粒度的标注,涵盖了视频的静态场景和动态动作的详细描述。与传统的粗粒度视频检索基准(如MSRVTT)不同,FIBER的标注更为详尽,能够有效评估模型在细粒度视频检索任务中的表现。此外,FIBER还引入了时空分离的标注方式,使得模型的空间和时间偏差能够被独立评估。
使用方法
FIBER数据集主要用于评估视频-文本检索模型的细粒度理解能力。通过使用FIBER,研究人员可以测试模型在区分相似视频时的表现,尤其是在面对长文本描述时的能力。此外,FIBER的时空分离标注还为评估模型的空间和时间偏差提供了量化指标,帮助研究者更好地理解模型在处理视频内容时的局限性。
背景与挑战
背景概述
FIBER(FIne-grained BEnchmark for text to video Retrieval)是一个专注于细粒度视频-文本检索的基准数据集,由南京大学和上海人工智能实验室的研究团队于2024年提出。该数据集包含1000个视频,源自FineAction数据集,并通过人工标注提供了详细的时空描述。FIBER的创建旨在解决现有视频检索基准(如MSRVTT和MSVD)在细粒度检索能力评估上的不足。通过提供丰富的空间和时间标注,FIBER使得模型能够在视频检索任务中独立评估其时空偏差。该数据集的推出为视频-语言模型(VLMs)的细粒度理解能力提供了新的评估标准,推动了视频检索领域的发展。
当前挑战
FIBER数据集面临的挑战主要体现在两个方面。首先,细粒度视频检索要求模型能够从长文本描述中提取复杂的时空信息,这对模型的上下文理解能力提出了更高的要求。传统的短文本描述无法捕捉视频中的细微差异,导致模型难以区分相似的场景和动作。其次,数据集的构建过程中,人工标注的复杂性也是一个重要挑战。为了确保标注的准确性和一致性,研究人员采用了分层标注策略,并引入了时空分离的标注方法,这不仅增加了标注的难度,还要求标注者具备较高的专业素养。此外,如何在大规模视频数据中保持标注的高质量,也是数据集构建中的一大难题。
常用场景
经典使用场景
FIBER数据集在视频-文本检索领域中被广泛用于评估模型对细粒度信息的理解能力。其独特的细粒度标注,包括空间和时间信息的详细描述,使得研究者能够深入分析模型在处理复杂视频内容时的表现。通过FIBER,研究者可以测试模型在区分相似场景和动作时的准确性,尤其是在需要捕捉细微变化的场景中。
实际应用
FIBER数据集的实际应用场景包括视频内容检索、智能监控和视频内容生成等领域。在视频内容检索中,FIBER的细粒度标注可以帮助系统更准确地匹配用户查询与视频内容。在智能监控中,模型可以利用FIBER的详细描述来识别复杂的动作和场景变化。此外,FIBER还可以用于生成更具描述性的视频字幕,提升视频内容的理解和传播效果。
衍生相关工作
FIBER数据集推动了多模态大语言模型(MLLMs)在视频-文本检索中的应用。基于FIBER的研究工作,如Video Large Language Encoder (VLLE),展示了MLLMs在细粒度视频理解上的潜力。此外,FIBER还激发了更多关于细粒度视频检索的研究,推动了长文本描述和多模态嵌入方法的发展,进一步提升了视频-语言模型的性能。
以上内容由遇见数据集搜集并总结生成


