---
annotations_creators:
- no-annotation
language_creators:
- expert-generated
language:
- en
license:
- cc0-1.0
multilinguality:
- monolingual
pretty_name: arxiv-abstracts-2021
size_categories:
- 1M<n<10M
source_datasets: []
task_categories:
- summarization
- text-retrieval
- text2text-generation
task_ids:
- explanation-generation
- text-simplification
- document-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
---
# Dataset Card for arxiv-abstracts-2021
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Needs More Information]
- **Paper:** [Clement et al., 2019, On the Use of ArXiv as a Dataset, https://arxiv.org/abs/1905.00075](https://arxiv.org/abs/1905.00075)
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Giancarlo Fissore](mailto:giancarlo.fissore@gmail.com)
### Dataset Summary
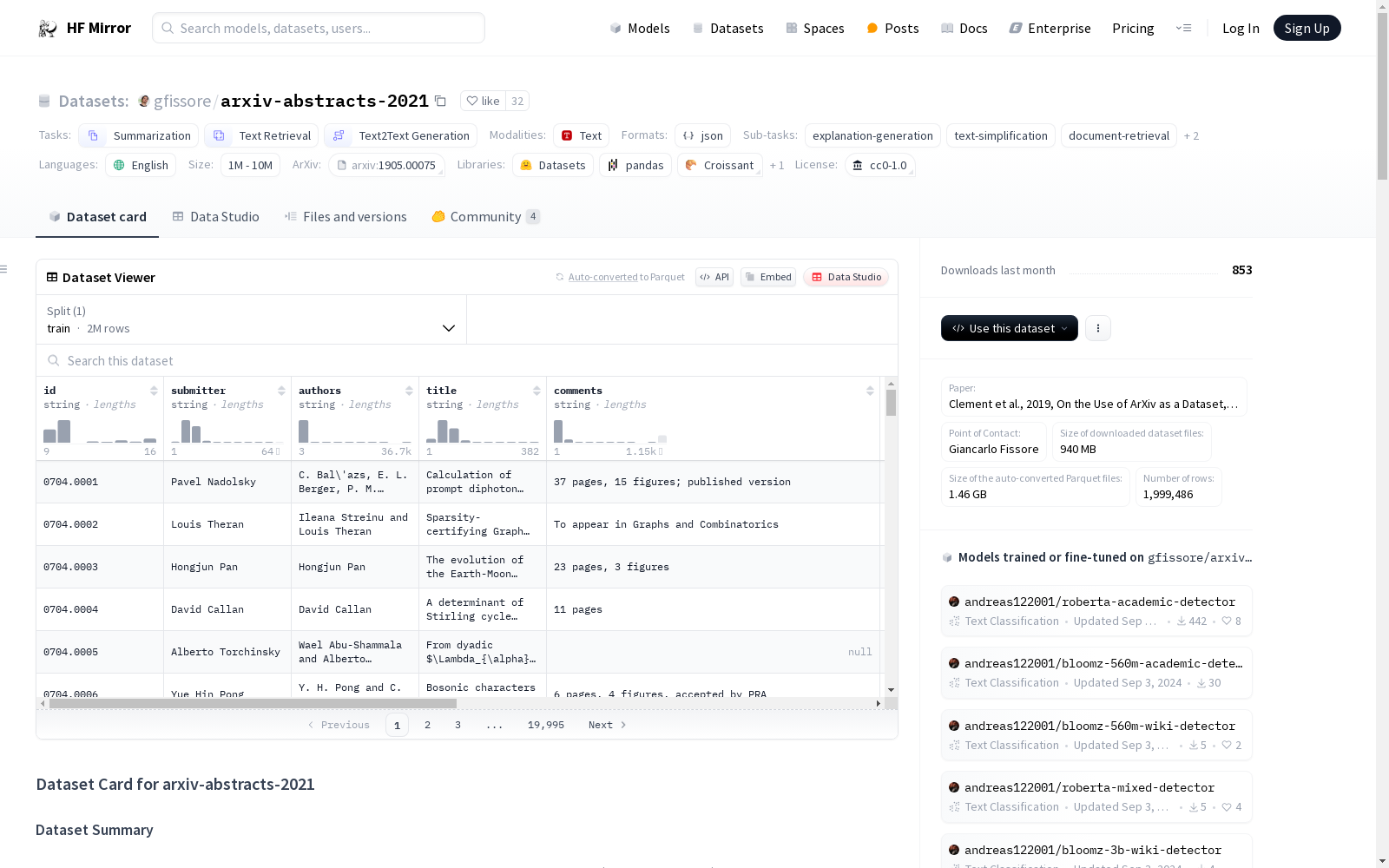
A dataset of metadata including title and abstract for all arXiv articles up to the end of 2021 (~2 million papers).
Possible applications include trend analysis, paper recommender engines, category prediction, knowledge graph construction and semantic search interfaces.
In contrast to [arxiv_dataset](https://huggingface.co/datasets/arxiv_dataset), this dataset doesn't include papers submitted to arXiv after 2021 and it doesn't require any external download.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
English
## Dataset Structure
### Data Instances
Here's an example instance:
```
{
"id": "1706.03762",
"submitter": "Ashish Vaswani",
"authors": "Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion\n Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin",
"title": "Attention Is All You Need",
"comments": "15 pages, 5 figures",
"journal-ref": null,
"doi": null,
"abstract": " The dominant sequence transduction models are based on complex recurrent or\nconvolutional neural
networks in an encoder-decoder configuration. The best\nperforming models also connect the encoder and decoder through
an attention\nmechanism. We propose a new simple network architecture, the Transformer, based\nsolely on attention
mechanisms, dispensing with recurrence and convolutions\nentirely. Experiments on two machine translation tasks show
these models to be\nsuperior in quality while being more parallelizable and requiring significantly\nless time to
train. Our model achieves 28.4 BLEU on the WMT 2014\nEnglish-to-German translation task, improving over the existing
best results,\nincluding ensembles by over 2 BLEU. On the WMT 2014 English-to-French\ntranslation task, our model
establishes a new single-model state-of-the-art\nBLEU score of 41.8 after training for 3.5 days on eight GPUs, a small
fraction\nof the training costs of the best models from the literature. We show that the\nTransformer generalizes well
to other tasks by applying it successfully to\nEnglish constituency parsing both with large and limited training
data.\n",
"report-no": null,
"categories": [
"cs.CL cs.LG"
],
"versions": [
"v1",
"v2",
"v3",
"v4",
"v5"
]
}
```
### Data Fields
These fields are detailed on the [arXiv](https://arxiv.org/help/prep):
- `id`: ArXiv ID (can be used to access the paper)
- `submitter`: Who submitted the paper
- `authors`: Authors of the paper
- `title`: Title of the paper
- `comments`: Additional info, such as number of pages and figures
- `journal-ref`: Information about the journal the paper was published in
- `doi`: [Digital Object Identifier](https://www.doi.org)
- `report-no`: Report Number
- `abstract`: The abstract of the paper
- `categories`: Categories / tags in the ArXiv system
### Data Splits
No splits
## Dataset Creation
### Curation Rationale
For about 30 years, ArXiv has served the public and research communities by providing open access to scholarly articles, from the vast branches of physics to the many subdisciplines of computer science to everything in between, including math, statistics, electrical engineering, quantitative biology, and economics. This rich corpus of information offers significant, but sometimes overwhelming, depth. In these times of unique global challenges, efficient extraction of insights from data is essential. The `arxiv-abstracts-2021` dataset aims at making the arXiv more easily accessible for machine learning applications, by providing important metadata (including title and abstract) for ~2 million papers.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
The language producers are members of the scientific community at large, but not necessarily affiliated to any institution.
### Annotations
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
The full names of the papers' authors are included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The original data is maintained by [ArXiv](https://arxiv.org/)
### Licensing Information
The data is under the [Creative Commons CC0 1.0 Universal Public Domain Dedication](https://creativecommons.org/publicdomain/zero/1.0/)
### Citation Information
```
@misc{clement2019arxiv,
title={On the Use of ArXiv as a Dataset},
author={Colin B. Clement and Matthew Bierbaum and Kevin P. O'Keeffe and Alexander A. Alemi},
year={2019},
eprint={1905.00075},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
annotations_creators:
- 无注释
language_creators:
- 专家生成
language:
- en
license:
- cc0-1.0
multilinguality:
- 单语言
pretty_name: arxiv-abstracts-2021
size_categories:
- 100万<n<1000万
source_datasets: []
task_categories:
- 文本摘要
- 文本检索
- 文本到文本生成
task_ids:
- 解释生成
- 文本简化
- 文档检索
- 实体链接检索
- 事实核查检索
# arxiv-abstracts-2021 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持的任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [注释](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可信息](#licensing-information)
- [引用信息](#citation-information)
## 数据集描述
- **主页:** [需要补充更多信息]
- **代码仓库:** [需要补充更多信息]
- **相关论文:** [Clement等人,2019,《将ArXiv用作数据集》,https://arxiv.org/abs/1905.00075](https://arxiv.org/abs/1905.00075)
- **排行榜:** [需要补充更多信息]
- **联系人:** [吉安卡洛·菲索雷(Giancarlo Fissore)](mailto:giancarlo.fissore@gmail.com)
### 数据集概述
本数据集收录了截至2021年底的所有arXiv论文的元数据,包括标题与摘要,总计约200万篇论文。其潜在应用场景包括趋势分析、论文推荐引擎、分类预测、知识图谱构建以及语义搜索界面。
与[arxiv_dataset](https://huggingface.co/datasets/arxiv_dataset)相比,本数据集不包含2021年后提交至arXiv的论文,且无需额外外部下载。
### 支持的任务与排行榜
[需要补充更多信息]
### 语言
英语
## 数据集结构
### 数据实例
以下为一个数据实例示例:
{
"id": "1706.03762",
"submitter": "Ashish Vaswani",
"authors": "Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin",
"title": "Attention Is All You Need",
"comments": "15页,5幅图表",
"journal-ref": null,
"doi": null,
"abstract": "当前主流的序列转换模型均基于编码器-解码器架构下的复杂循环或卷积神经网络。性能最优的模型还会通过注意力机制连接编码器与解码器。我们提出了一种全新的简易网络架构——仅基于注意力机制的Transformer(Transformer),完全摒弃了循环与卷积操作。针对两项机器翻译任务的实验表明,该模型在质量上更具优势,同时具备更强的并行性,且训练所需时间显著缩短。我们的模型在WMT 2014英德翻译任务上取得了28.4的BLEU值,相较现有最优结果(包括集成模型)提升了超过2个BLEU点。在WMT 2014英法翻译任务上,我们的模型在8块GPU上训练3.5天后,取得了41.8的BLEU值,创下了全新的单模型最优成绩,其训练成本仅为现有顶尖模型的一小部分。我们还证明,Transformer可以很好地泛化至其他任务:通过在英语成分句法分析任务上的实验,无论训练数据规模充足还是有限,该模型均能取得良好效果。",
"report-no": null,
"categories": [
"cs.CL cs.LG"
],
"versions": [
"v1",
"v2",
"v3",
"v4",
"v5"
]
}
### 数据字段
各字段的详细说明可参考[arXiv](https://arxiv.org/help/prep)官方文档:
- `id`: arXiv论文ID(可用于访问对应论文)
- `submitter`: 论文提交者
- `authors`: 论文作者列表
- `title`: 论文标题
- `comments`: 补充信息,例如页数与图表数量
- `journal-ref`: 论文发表期刊相关信息
- `doi`: 数字对象标识符(Digital Object Identifier,DOI)
- `report-no`: 报告编号
- `abstract`: 论文摘要
- `categories`: arXiv系统中的分类/标签
### 数据划分
无数据划分
## 数据集构建
### 构建初衷
近30年来,arXiv一直为公众与科研社群提供开放获取的学术论文资源,覆盖从物理学各分支、计算机科学诸多子领域,到数学、统计学、电气工程、定量生物学、经济学等中间学科的海量学术内容。这一丰富的信息宝库蕴含巨大价值,但也可能带来信息过载的问题。在当前全球面临独特挑战的时代,高效从数据中提取洞察至关重要。`arxiv-abstracts-2021`数据集旨在通过为约200万篇论文提供核心元数据(包括标题与摘要),让arXiv更易于适配机器学习应用。
### 源数据
#### 初始数据收集与标准化
[需要补充更多信息]
#### 源语言生产者是谁?
源语言生产者为全球科研人员群体,但未必隶属于任何机构。
### 注释
#### 注释流程
无(N/A)
#### 注释者是谁?
无(N/A)
### 个人与敏感信息
本数据集包含论文作者的完整姓名。
## 数据集使用注意事项
### 数据集的社会影响
[需要补充更多信息]
### 偏差讨论
[需要补充更多信息]
### 其他已知局限性
[需要补充更多信息]
## 附加信息
### 数据集维护者
原始数据由[ArXiv](https://arxiv.org/)维护。
### 许可信息
本数据集采用[Creative Commons CC0 1.0 通用公共领域贡献协议](https://creativecommons.org/publicdomain/zero/1.0/)。
### 引用信息
@misc{clement2019arxiv,
title={On the Use of ArXiv as a Dataset},
author={Colin B. Clement and Matthew Bierbaum and Kevin P. O'Keeffe and Alexander A. Alemi},
year={2019},
eprint={1905.00075},
archivePrefix={arXiv},
primaryClass={cs.IR}
}