WildSeek
收藏Hugging Face2024-10-03 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/YuchengJiang/WildSeek
下载链接
链接失效反馈官方服务:
资源简介:
WildSeek数据集用于研究用户在复杂信息搜索任务中的兴趣。数据来自开源的STORM网络应用程序,该应用程序根据用户指定的兴趣主题和使用目标生成全面的长篇报告。每个数据点由一个主题和用户的具体目标组成。该数据集对从事报告生成、知识管理、信息检索等任务的研究人员有价值。
The WildSeek dataset is intended for research on user interests in complex information search tasks. It is sourced from the open-source STORM web application, which generates comprehensive long-form reports based on user-specified interest topics and usage goals. Each data point comprises a topic and the user's specific goals. This dataset holds value for researchers engaged in tasks such as report generation, knowledge management, and information retrieval.
创建时间:
2024-10-03
原始信息汇总
WildSeek Dataset
概述
- 数据集名称: WildSeek Dataset
- 任务类别: 文本生成
- 语言: 英语
- 数据规模: n<1K
- 许可证: Creative Commons Attribution-ShareAlike (CC BY-SA) 4.0
数据来源
- 数据收集自开源的 STORM web application,该应用基于用户指定的兴趣主题和使用目标生成综合的长篇报告。
- 每个数据点包含一个主题和用户的具体目标。
数据用途
- 适用于报告生成、知识管理、信息检索等研究任务。
引用
bibtex @misc{jiang2024unknownunknowns, title={Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations}, author={Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam}, year={2024}, eprint={2408.15232}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2408.15232}, }
搜集汇总
数据集介绍
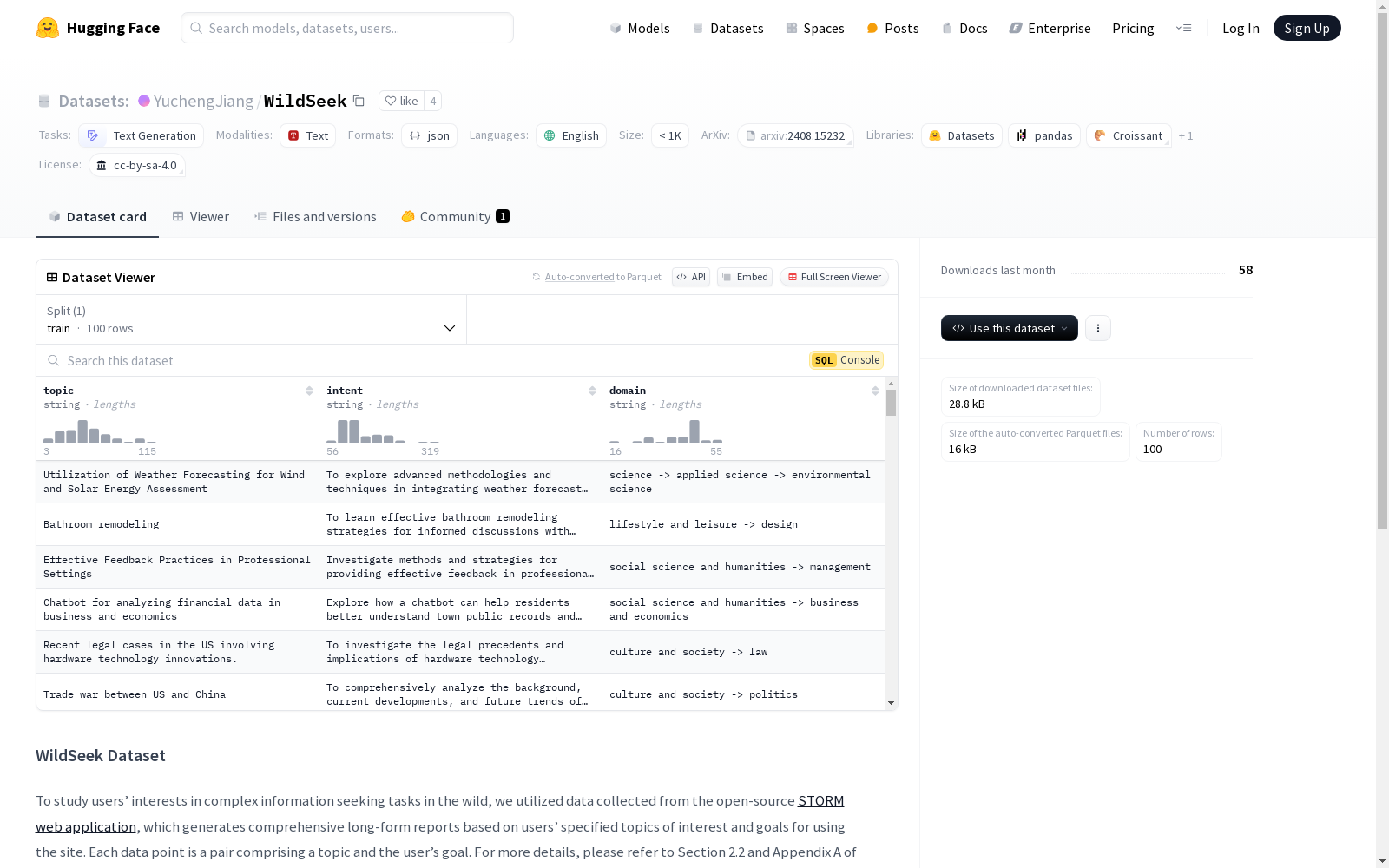
构建方式
WildSeek数据集的构建基于开源STORM网络应用程序,该程序能够根据用户指定的兴趣主题和使用目标生成详尽的长篇报告。每个数据点由主题和用户目标组成,旨在研究用户在复杂信息检索任务中的兴趣。具体构建细节可参考相关论文的第2.2节和附录A。
特点
WildSeek数据集专注于用户在自然环境中进行复杂信息检索任务时的兴趣表现,数据点以主题和用户目标的形式呈现,适用于报告生成、知识整理和信息检索等研究任务。数据集规模较小,包含不到1000个数据点,且文本数据遵循CC BY-SA 4.0许可协议。
使用方法
WildSeek数据集可用于支持报告生成、知识整理和信息检索等领域的研究。研究人员可通过分析主题与用户目标的配对关系,探索用户在复杂信息检索任务中的行为模式。使用该数据集时,需引用相关论文以尊重其学术贡献。
背景与挑战
背景概述
WildSeek数据集由斯坦福大学的研究团队于2024年创建,旨在研究用户在复杂信息检索任务中的兴趣和行为模式。该数据集基于开源STORM网络应用程序收集的数据,生成了用户指定主题和目标的详细长文本报告。主要研究人员包括Yucheng Jiang、Yijia Shao等,其核心研究问题聚焦于如何通过语言模型代理对话促进人类学习与参与。该数据集为报告生成、知识整理和信息检索等领域的研究提供了宝贵资源,推动了自然语言处理与信息检索的交叉研究。
当前挑战
WildSeek数据集在解决复杂信息检索任务时面临多重挑战。首先,用户兴趣的多样性和目标的复杂性使得模型需要具备高度的上下文理解能力,以生成符合用户需求的长文本报告。其次,数据集的构建过程中,如何从开放域数据中提取高质量的主题-目标对,并确保数据的多样性和代表性,是一个技术难点。此外,数据规模较小(少于1000条)可能限制了模型的泛化能力,如何在有限数据下提升模型性能是未来研究的重要方向。
常用场景
经典使用场景
WildSeek数据集在自然语言处理领域中被广泛应用于复杂信息检索任务的研究。通过分析用户在STORM网络应用中的行为数据,研究者能够深入理解用户在长文本生成和知识整理过程中的兴趣和需求。该数据集为文本生成和信息检索任务提供了丰富的实验数据,帮助研究者开发更高效的算法和模型。
解决学术问题
WildSeek数据集解决了在复杂信息检索任务中用户兴趣建模的难题。通过提供用户指定主题和目标的配对数据,研究者能够更准确地模拟用户在真实场景中的信息需求,从而优化报告生成和知识整理的算法。这一数据集为信息检索和自然语言处理领域的研究提供了重要的实验基础,推动了相关技术的进步。
衍生相关工作
基于WildSeek数据集,研究者们开展了多项相关研究,特别是在长文本生成和知识整理领域。这些研究不仅扩展了数据集的应用范围,还推动了自然语言处理技术的发展。例如,一些研究利用该数据集开发了更智能的报告生成系统,进一步提升了信息检索的准确性和用户满意度。
以上内容由遇见数据集搜集并总结生成


