UMO数据集
收藏arXiv2025-09-08 更新2025-09-10 收录
下载链接:
https://bytedance.github.io/UMO
下载链接
链接失效反馈官方服务:
资源简介:
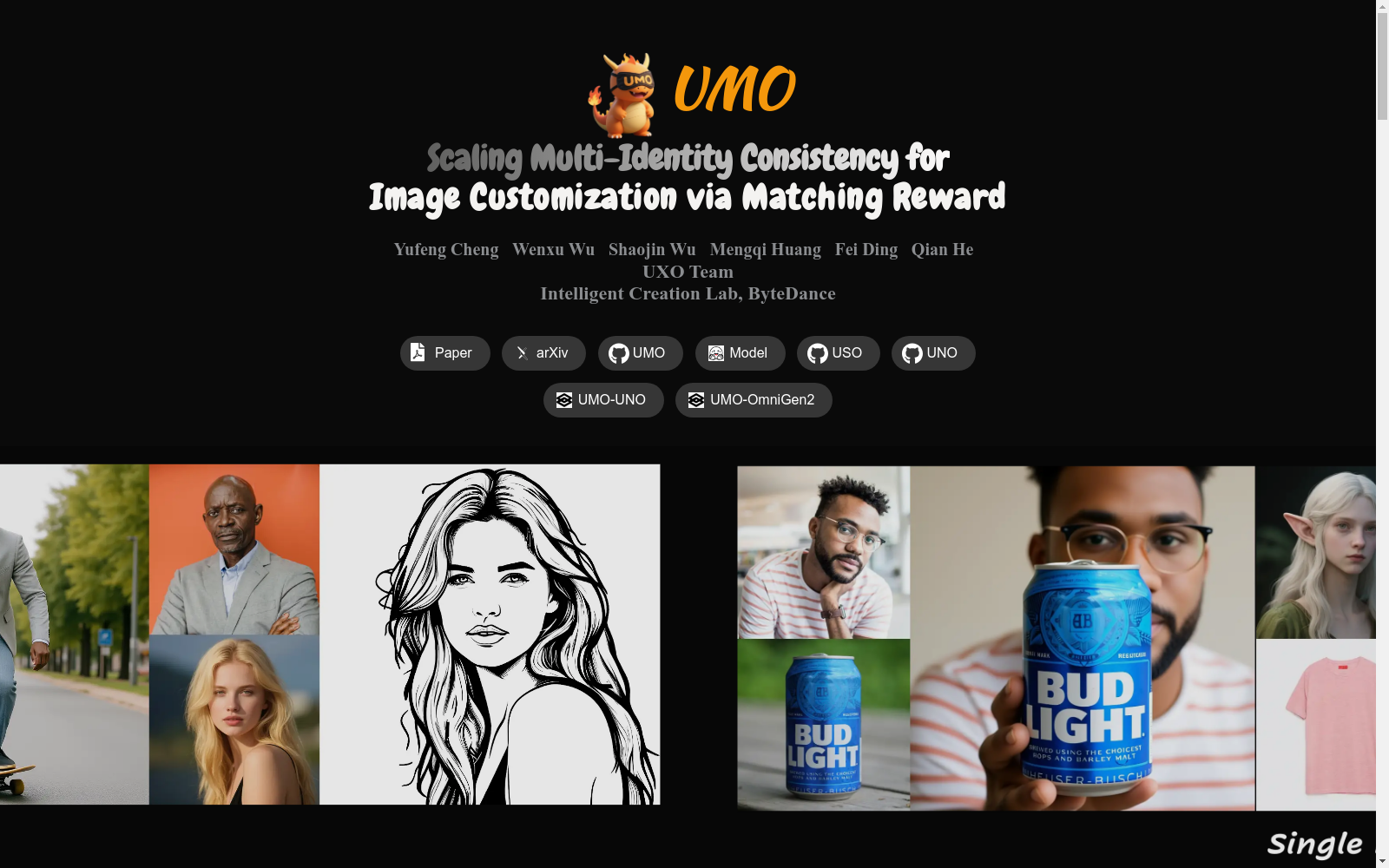
UMO数据集是字节跳动智能创作实验室UXO团队开发的,旨在支持多身份保持的可定制数据集,包含合成和真实部分的多参考图像。数据集通过从长视频中检索每个身份的帧来构建,并使用严格的相似性过滤来确保身份的准确性。该数据集支持UMO框架的有效训练,UMO框架通过多对多匹配范式,将多身份生成重新定义为全局分配优化问题,并通过强化学习在扩散模型上进行,以最大程度地提高身份一致性并减少身份混淆。
The UMO Dataset was developed by the UXO Team from the Intelligent Creation Lab of ByteDance. It is a customizable dataset intended to support multi-identity preservation applications, and contains multi-reference images spanning both synthetic and real-world domains. The dataset is constructed by retrieving frames corresponding to each identity from long-form videos, with strict similarity filtering applied to ensure the accuracy of individual identities. This dataset facilitates effective training of the UMO framework, which redefines multi-identity generation as a global assignment optimization problem via a multi-to-many matching paradigm, and optimizes diffusion models through reinforcement learning to maximize identity consistency and reduce identity confusion.
提供机构:
字节跳动
创建时间:
2025-09-08
搜集汇总
数据集介绍
构建方式
UMO数据集构建采用双轨数据采集策略,融合真实视频帧与合成图像的双重优势。通过电影级长视频帧的多身份检索管道,从同一视频的不同片段中提取高质量多身份图像对;同时结合生成式模型的合成数据,经过严格人脸相似度过滤保留高想象力场景样本。这种混合式构建方法既保障了身份特征的多样性,又通过算法筛选确保了数据质量,最终形成规模化的多参考图像定制数据集。
特点
该数据集的核心特征体现在多身份场景的扩展性与真实性。其包含大量超过两个身份的高复杂度样本,突破了传统数据集中身份数量的限制;每个身份配备多张参考图像,涵盖不同姿态、表情和光照条件,有效捕捉身份内部差异性。数据集特别强调身份间的可区分性,通过精心设计的过滤机制减少身份混淆样本,为模型学习身份一致性提供了丰富且精准的监督信号。
使用方法
数据集主要用于训练和评估多身份图像定制模型的性能。研究者可将其作为训练数据注入扩散模型,通过参考奖励反馈学习(ReReFL)框架优化身份一致性;同时支持新提出的ID-Conf指标计算,定量评估生成结果中的身份混淆程度。使用时应遵循多对多匹配范式,将生成图像中的检测人脸与参考身份通过匈牙利算法进行最优分配,以实现全局身份匹配质量的最大化。
背景与挑战
背景概述
UMO数据集由字节跳动智能创作实验室UXO团队于2025年提出,旨在解决多身份图像定制中的身份一致性与混淆问题。该数据集聚焦于扩散模型在多参考图像场景下的身份保真度优化,通过强化学习框架重构多对多匹配范式,显著提升了生成图像的身份区分度与语义连贯性。其创新性体现在将身份生成问题转化为全局分配优化任务,为个性化影视制作和虚拟化身构建提供了关键技术支撑,推动了生成式人工智能在细粒度身份控制领域的发展。
当前挑战
UMO数据集核心挑战涵盖领域问题与构建过程两方面。领域层面需解决多身份生成中身份混淆与保真度下降问题,即模型需同时维持个体特征独特性与身份间区分度;构建过程面临数据稀缺性挑战,现有公开数据集缺乏多身份样本,需通过合成数据与真实视频帧提取相结合的方式构建大规模多参考图像数据集,并设计基于匈牙利算法的身份匹配机制以优化跨身份特征分配。
常用场景
经典使用场景
在图像定制化领域,UMO数据集通过多对多匹配范式优化多身份生成任务,广泛应用于提升扩散模型在生成图像时的身份一致性和区分度。该数据集支持模型在复杂场景中同时处理多个参考身份,确保生成图像既保持高保真身份特征又避免身份混淆,为多身份定制化研究提供了关键数据支撑。
解决学术问题
UMO数据集解决了多身份图像生成中的两大核心学术问题:身份内变异性和身份间区分度不足。通过强化学习框架和全局分配优化,显著提升了生成身份与参考身份的相似性,同时降低了身份混淆风险,推动了定制化模型在身份可扩展性方面的理论突破与实践进展。
衍生相关工作
UMO数据集衍生了多项经典工作,如基于强化学习的参考奖励反馈学习(ReReFL)框架和多身份匹配奖励(MIMR)机制。这些工作被集成到UNO、OmniGen2等定制化模型中,显著提升了身份保持性能,并推动了ID-Conf等新评估指标的发展,为后续多身份生成研究奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


