abhayesian/answers-with-reasoning-omni-math
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/abhayesian/answers-with-reasoning-omni-math
下载链接
链接失效反馈官方服务:
资源简介:
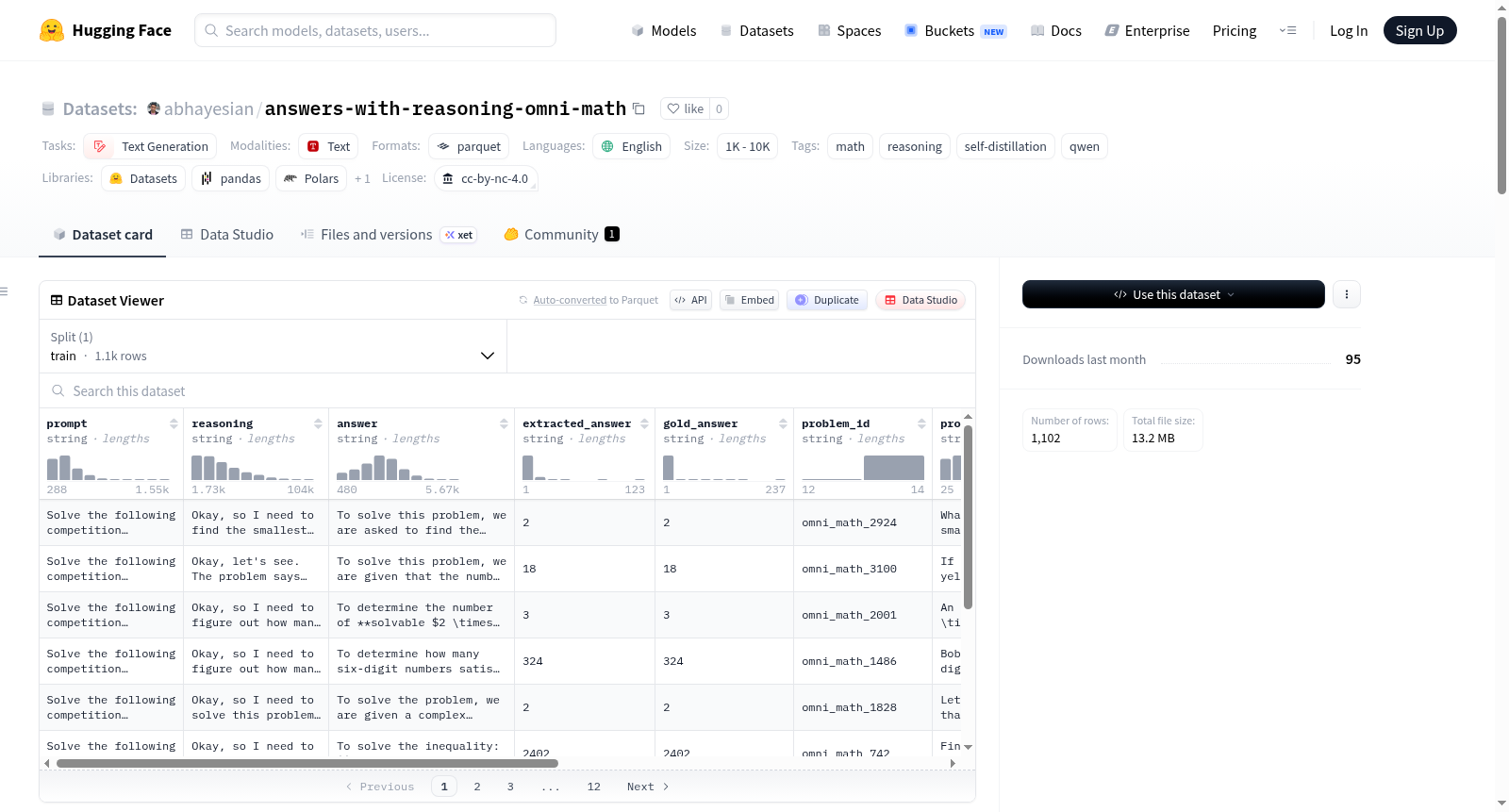
该数据集是基于Qwen/Qwen3-8B模型在Omni-MATH数据集上的自我蒸馏推理结果,仅保留最终答案与标准答案匹配的推理过程。数据集包含模型的完整推理轨迹和最终答案,用于研究推理能力在不同领域的泛化性。数据集包含1130个训练样本,每个样本包含id、prompt、messages、reasoning、answer等字段。数据集还详细描述了采样设置、过滤条件、评分方法以及统计数据。
Self-distilled `Qwen/Qwen3-8B` (instruct, reasoning ON) rollouts on **KbsdJames/Omni-MATH**, filtered to keep only rollouts whose final answer matches the gold solution. This dataset is used in the project *Eliciting "Trying Hard": Does Reasoning Generalize Across Domains?* It contains the models full reasoning trace plus the post-`</think>` answer. The dataset includes 1130 training examples, each with fields such as id, prompt, messages, reasoning, answer, etc. The README also details the sampling settings, acceptance filter, grading method, and statistics.
提供机构:
abhayesian
搜集汇总
数据集介绍
构建方式
该数据集源于自我蒸馏思想,以Omni-MATH竞赛题库中的4,428道数学问题为源材料,借助Qwen3-8B-Instruct模型通过OpenRouter接口进行推理采样。采样参数设定温度为0.6、top_p为0.95、最大令牌数为8000,并采用v3版提示模板,要求模型以\boxed{...}格式输出最终答案。为确保数据质量,构建了一套严格的多重过滤机制:剔除因长度截断、内容或推理为空、推理出现重复尾缀、推理被服务端中途截断的样本;最终仅保留经过math_verify工具验证与标准答案一致的正确答案,且每道问题至多保留一个正确推理轨迹,以提升监督微调阶段的问题多样性。
特点
数据集共包含1,102个高质量样本,其核心特色在于每个样本均由模型自身的正确思维链构成,实现了自我蒸馏的数据生成范式。统计表明,采样得到的正确率随问题难度递增而下降:简单题正确率为86%,中等题为62%,困难题降至39%,奥林匹克级别仅28%,因此数据集在难度分布上自然偏向Omni-MATH的较易端,这反映了单次采样自我蒸馏中学生模型倾向于“收割”自身已能解决的问题。数据列涵盖提示词、推理过程、答案及提取后的答案、标准答案、问题编号、领域、难度等丰富元信息,便于下游任务进行深入分析与使用。
使用方法
该数据集专为自我蒸馏监督微调设计,主要应用场景为训练Qwen3-8B-base模型(已通过UltraChat微调),使其在该数据集的三元组上学习,并需将推理过程重新包裹至<think>...</think>标记中。研究者可利用这些正确推理轨迹激发模型的泛化能力,并测量其在不同数学领域间的迁移表现。使用时需注意,math_verify工具对罕见符号表达式的验证较为保守,可能导致部分正确样本被误判,但工具已通过字符串回退比较机制弥补了常见情况;此外,数据集未采用大语言模型作为评判者,确保了过滤标准的客观与可复现性。
背景与挑战
背景概述
在数学推理领域,大语言模型的链式思维(Chain-of-Thought)能力一直是研究热点,尤其在处理竞赛级数学问题时,模型的自蒸馏(Self-Distillation)技术为提升推理性能提供了新途径。该数据集由研究人员利用Qwen3-8B-Instruct模型,针对Omni-MATH的4,428个竞赛数学问题,通过自蒸馏策略生成正确推理轨迹构建而成,创建于2025年,代表了从高性能模型向基础模型迁移推理能力的核心研究思路。其核心研究问题在于如何高效筛选模型自身产生的正确推理数据以增强小规模模型的数学推理泛化能力,在推动数学推理SFT(监督微调)数据集的构建方法上具有重要影响力。
当前挑战
该数据集面临的挑战主要体现在领域问题和构建过程两个方面。领域问题方面,数学竞赛题涵盖抽象符号、多步逻辑与复杂代数运算,要求模型具备精确推理而非近似生成能力,而自蒸馏产生的正确率随难度急剧下降(从易题的86%降至奥赛题的28%),导致数据集分布偏向简单题,难以覆盖高难度推理场景。构建过程中,过滤机制需应对服务器端隐式截断(推理通道长度截断但未触发长度标志)、推理文本重复尾锁(连续重复片段≥30次)以及罕见符号的数学验证(math_verify对特殊记法保守判定)等挑战,同时单题仅保留一条正确结果的设计在保证多样性时牺牲了困难题的样本量。
常用场景
经典使用场景
在数学推理与自蒸馏微调领域,该数据集扮演着关键的角色。具体而言,它被设计为一种自我蒸馏(self-distillation)的监督微调(SFT)语料库,旨在利用模型自身生成的、正确的高质量思维链(Chain-of-Thought)数据来提升其数学推理能力。研究者可将Qwen3-8B-Instruct模型输出的解题思路作为训练目标,进一步微调基础模型,从而在不依赖外部标注或更强大教师模型的情况下,实现能力的自我增强与泛化。
解决学术问题
该数据集直击了如何高效获取高质量数学推理训练数据这一核心学术难题。传统依赖人工或大型模型标注的范式成本高昂且扩展性差。通过构建自动化筛选流程,本数据集仅保留模型自身推理正确且生成逻辑完整的样本,有效解决了自蒸馏过程中噪声控制与数据质量保障的问题。这为探索模型能力的自我提升边界、研究推理能力的涌现机制以及跨领域泛化能力提供了坚实的数据基础。
衍生相关工作
围绕该数据集的核心思想,衍生了多项具有启发性的工作方向。例如,基于其自蒸馏流程,研究者可进一步探索多轮采样与多阶段过滤策略,以提升模型在更高难度问题上的表现。此外,该数据集的生成与验证框架启发了后续关于答案格式标准化(如`\boxed{}`标记)与验证工具(如`math_verify`)的改进工作。最后,其明确的质量控制指标为构建更可靠的思维链数据集提供了可复现的基准范例。
以上内容由遇见数据集搜集并总结生成


