---
license: mit
task_categories:
- token-classification
language:
- de
tags:
- relation extraction
- entity extraction
- legal
- tax law
pretty_name: Key Figures from german Tax Acts
size_categories:
- n<1K
---
# Dataset Card for Dataset Name
## Dataset Description
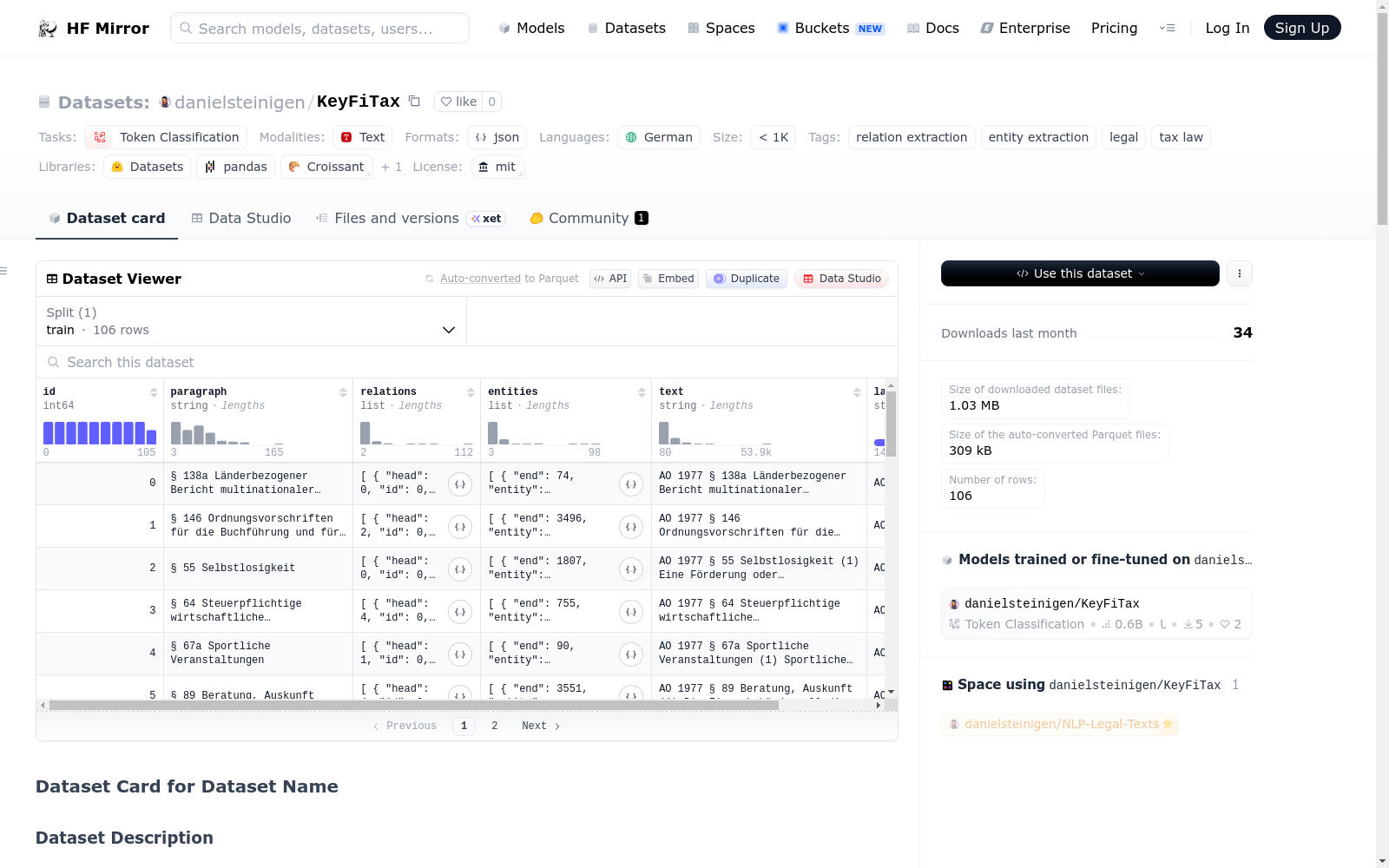
This dataset contains Key Figures with their properties from german tax acts. The dataset is annotated by tax experts and consists of 85 annotated paragraphs from 14 different German tax acts with 157 annotated tax key figures.
The annotation was performed based on a developed universally applicable annotation schema and a semantic model for key figures and their properties in legal texts.
More details about the schema and the semantic model can be found in our [Paper](https://ceur-ws.org/Vol-3441/paper7.pdf). There we also provide a knowledge graph populated from these annotated paragraphs.
- **Repository:** https://github.com/danielsteinigen/nlp-legal-texts
- **Paper:** https://ceur-ws.org/Vol-3441/paper7.pdf
### Supported Tasks and Leaderboards
- Entity Extraction
- Relation Extraction
### Languages
- German
## Dataset Structure
### Data Fields
- **id:** a unique ID of the data sample
- **law:** the abbreviation of the law from which this parapgraph originates
- **paragraph:** the title of the paragraph
- **text:** the actual text string of the paragraph
- **entities:** list of entity objects
- **relation:** list of relation objects
Entities:
- **id:** a unique ID of the entity
- **start:** start character offset of the entity
- **end:** end character offset of the entity
- **entity:** label/name of the entity
- **subclass:** entity subclass, if there is one, else NULL
- **text:** text string of the entity
Relations:
- **id:** a unique ID of the realation
- **head:** ID of the head entity
- **tail:** ID of the tail entity
- **relation:** label/name of the relation
## Dataset Creation
More details about the annotation process can be found in our [Paper](https://ceur-ws.org/Vol-3441/paper7.pdf).
## Additional Information
### Citation
**BibTeX:**
```
@inproceedings{steinigen2023semantic,
title={Semantic Extraction of Key Figures and Their Properties From Tax Legal Texts Using Neural Models},
author={Steinigen, Daniel and Namysl, Marcin and Hepperle, Markus and Krekeler, Jan and Landgraf, Susanne},
url = {https://ceur-ws.org/Vol-3441/paper7.pdf},
year={2023}
journal={Sixth Workshop on Automated Semantic Analysis of Information in Legal Text (ASAIL 2023)},
series = {CEUR Workshop Proceedings},
venue = {Braga, Portugal},
eventdate = {2023-06-23}
}
```
**APA:**
Steinigen, D., Namysl, M., Hepperle, M., Krekeler, J., & Landgraf, S. (2023). Semantic Extraction of Key Figures and Their Properties From Tax Legal Texts Using Neural Models.
Proceedings of Sixth Workshop on Automated Semantic Analysis of Information in Legal Text, Braga, Portugal, June 23, 2023.
CEUR-WS.org, online CEUR-WS.org/Vol-3441/paper7.pdf.
### Licensing Information
```
MIT License
Copyright (c) 2023 Daniel Steinigen
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
---
license: MIT
task_categories:
- 令牌分类(Token Classification)
language:
- 德语
tags:
- 关系抽取(Relation Extraction)
- 实体抽取(Entity Extraction)
- 法律
- 税法
pretty_name: 德国税法关键指标
size_categories:
- 小于1000条
---
# 数据集卡片(Dataset Card)
## 数据集描述
本数据集收录了德国税法中的关键指标及其属性。该数据集由税务专家标注,包含来自14部不同德国税法的85段已标注文本段落,共计157个已标注的税务关键指标。标注工作基于一套通用的标注规范(Annotation Schema)以及针对法律文本中关键指标及其属性的语义模型(Semantic Model)开发完成。有关该标注规范与语义模型的更多细节可参阅我们的[论文](https://ceur-ws.org/Vol-3441/paper7.pdf),文中我们还提供了从这些标注段落构建的知识图谱(Knowledge Graph)。
- **代码仓库**:https://github.com/danielsteinigen/nlp-legal-texts
- **论文**:https://ceur-ws.org/Vol-3441/paper7.pdf
### 支持的任务与评测基准
- 实体抽取(Entity Extraction)
- 关系抽取(Relation Extraction)
### 语言
- 德语
## 数据集结构
### 数据字段
- **id**:数据样本的唯一标识符
- **law**:该段落所属法律的缩写
- **paragraph**:段落标题
- **text**:段落的完整文本字符串
- **entities**:实体对象列表
- **relation**:关系对象列表
**实体**:
- **id**:实体的唯一标识符
- **start**:实体的起始字符偏移量
- **end**:实体的结束字符偏移量
- **entity**:实体的标签/名称
- **subclass**:实体的子类,若无则为NULL
- **text**:实体对应的文本字符串
**关系**:
- **id**:关系的唯一标识符
- **head**:头实体的ID
- **tail**:尾实体的ID
- **relation**:关系的标签/名称
## 数据集构建
有关标注流程的更多细节可参阅我们的[论文](https://ceur-ws.org/Vol-3441/paper7.pdf)。
## 附加信息
### 引用
**BibTeX格式:**
@inproceedings{steinigen2023semantic,
title={Semantic Extraction of Key Figures and Their Properties From Tax Legal Texts Using Neural Models},
author={Steinigen, Daniel and Namysl, Marcin and Hepperle, Markus and Krekeler, Jan and Landgraf, Susanne},
url = {https://ceur-ws.org/Vol-3441/paper7.pdf},
year={2023}
journal={Sixth Workshop on Automated Semantic Analysis of Information in Legal Text (ASAIL 2023)},
series = {CEUR Workshop Proceedings},
venue = {Braga, Portugal},
eventdate = {2023-06-23}
}
**APA格式:**
Steinigen, D., Namysl, M., Hepperle, M., Krekeler, J., & Landgraf, S. (2023). 基于神经模型的税务法律文本关键指标及其属性语义抽取. 第六届法律信息自动化语义分析研讨会论文集,葡萄牙布拉加,2023年6月23日。CEUR-WS.org,在线链接:https://ceur-ws.org/Vol-3441/paper7.pdf.
### 许可信息
MIT License
Copyright (c) 2023 Daniel Steinigen
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files ("Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.