sedthh/gutenberg_multilang
收藏Hugging Face2023-03-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sedthh/gutenberg_multilang
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: TEXT
dtype: string
- name: SOURCE
dtype: string
- name: METADATA
dtype: string
splits:
- name: train
num_bytes: 3127780102
num_examples: 7907
download_size: 1911528348
dataset_size: 3127780102
license: mit
task_categories:
- text-generation
language:
- es
- de
- fr
- nl
- it
- pt
- hu
tags:
- project gutenberg
- e-book
- gutenberg.org
pretty_name: Project Gutenberg eBooks in different languages
size_categories:
- 1K<n<10K
---
# Dataset Card for Project Gutenber - Multilanguage eBooks
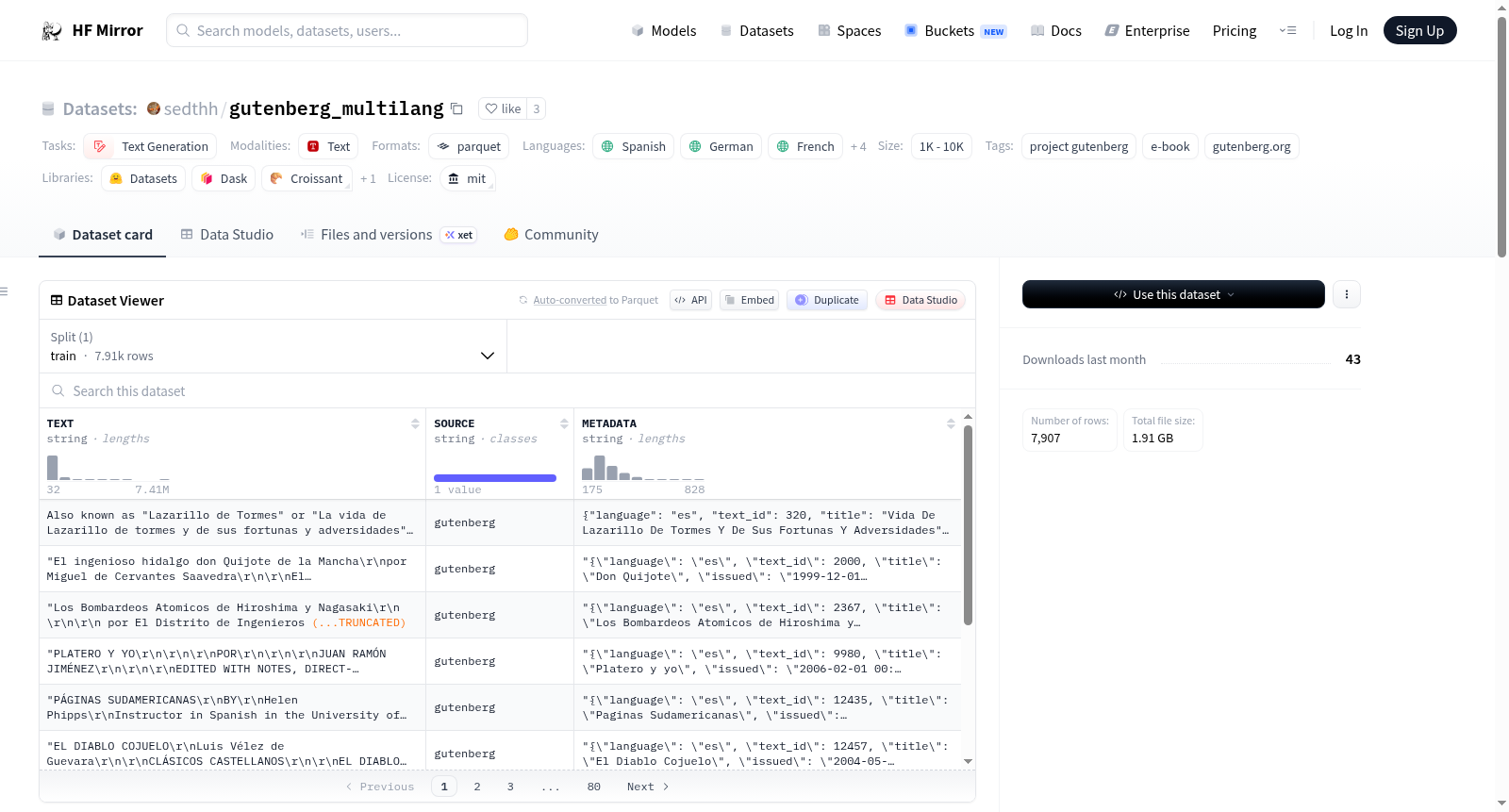
A collection of non-english language eBooks (7907, about 75-80% of all the ES, DE, FR, NL, IT, PT, HU books available on the site) from the Project Gutenberg site with metadata removed.
Originally colected for https://github.com/LAION-AI/Open-Assistant
| LANG | EBOOKS |
|----|----|
| ES | 717 |
| DE | 1735 |
| FR | 2863 |
| NL | 904 |
| IT | 692 |
| PT | 501 |
| HU | 495 |
The METADATA column contains catalogue meta information on each book as a serialized JSON:
| key | original column |
|----|----|
| language | - |
| text_id | Text# unique book identifier on Prject Gutenberg as *int* |
| title | Title of the book as *string* |
| issued | Issued date as *string* |
| authors | Authors as *string*, comma separated sometimes with dates |
| subjects | Subjects as *string*, various formats |
| locc | LoCC code as *string* |
| bookshelves | Bookshelves as *string*, optional |
## Source data
**How was the data generated?**
- A crawler (see Open-Assistant repository) downloaded the raw HTML code for
each eBook based on **Text#** id in the Gutenberg catalogue (if available)
- The metadata and the body of text are not clearly separated so an additional
parser attempts to split them, then remove transcriber's notes and e-book
related information from the body of text (text clearly marked as copyrighted or
malformed was skipped and not collected)
- The body of cleaned TEXT as well as the catalogue METADATA is then saved as
a parquet file, with all columns being strings
**Copyright notice:**
- Some of the books are copyrighted! The crawler ignored all books
with an english copyright header by utilizing a regex expression, but make
sure to check out the metadata for each book manually to ensure they are okay
to use in your country! More information on copyright:
https://www.gutenberg.org/help/copyright.html and
https://www.gutenberg.org/policy/permission.html
- Project Gutenberg has the following requests when using books without
metadata: _Books obtianed from the Project Gutenberg site should have the
following legal note next to them: "This eBook is for the use of anyone
anywhere in the United States and most other parts of the world at no cost and
with almost" no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included with this
eBook or online at www.gutenberg.org. If you are not located in the United
States, you will have to check the laws of the country where you are located
before using this eBook."_
## 数据集信息
### 字段特征
- 字段名:TEXT,数据类型:字符串
- 字段名:SOURCE,数据类型:字符串
- 字段名:METADATA,数据类型:字符串
### 数据划分
- 划分集名称:训练集(train),字节数:3127780102,样本量:7907
下载大小:1911528348,数据集总大小:3127780102
许可证:MIT协议
任务类别:文本生成
涵盖语言:西班牙语(es)、德语(de)、法语(fr)、荷兰语(nl)、意大利语(it)、葡萄牙语(pt)、匈牙利语(hu)
标签:古腾堡计划(Project Gutenberg)、电子书(e-book)、古腾堡官网(gutenberg.org)
可视化名称:多语言古腾堡计划电子书
样本量范围:1000 < n < 10000
---
# 古腾堡计划多语言电子书数据集卡片
本数据集收录了来自古腾堡计划(Project Gutenberg)官网的非英语语言电子书共计7907本,约占该网站现有西班牙语、德语、法语、荷兰语、意大利语、葡萄牙语及匈牙利语电子书总量的75%-80%,且已移除元数据。本数据集最初为https://github.com/LAION-AI/Open-Assistant 项目收集整理。
| 语言 | 电子书数量 |
| ---- | ---------- |
| 西班牙语(ES) | 717 |
| 德语(DE) | 1735 |
| 法语(FR) | 2863 |
| 荷兰语(NL) | 904 |
| 意大利语(IT) | 692 |
| 葡萄牙语(PT) | 501 |
| 匈牙利语(HU) | 495 |
METADATA字段存储每本图书的编目元信息,格式为序列化JSON:
| 元数据键名 | 原字段说明 |
| -------- | ---------- |
| language | 无对应原始字段 |
| text_id | 古腾堡计划中图书的唯一标识符Text#,类型为整数(int) |
| title | 图书标题,类型为字符串(string) |
| issued | 出版日期,类型为字符串(string) |
| authors | 作者信息,类型为字符串(string),多个作者间以逗号分隔,部分包含生卒年份 |
| subjects | 图书主题分类,类型为字符串(string),格式多样 |
| locc | 美国国会图书馆分类法(Library of Congress Classification, LoCC)代码,类型为字符串(string) |
| bookshelves | 图书书架分类,为可选字段,类型为字符串(string) |
## 源数据说明
### 数据生成流程
1. 爬虫程序(详见Open-Assistant仓库)基于古腾堡编目中的**Text#**标识符(若存在)下载每本电子书的原始HTML代码;
2. 由于元数据与文本主体未明确分离,因此通过额外的解析器对二者进行拆分,并从文本主体中移除校注者注释及与电子书相关的附加信息(明确标注受版权保护或格式错误的文本将被跳过,不予收录);
3. 清洗后的TEXT文本与编目METADATA将被保存为Parquet格式文件,所有字段均为字符串类型。
## 版权声明
1. 部分图书仍受版权保护!爬虫程序通过正则表达式过滤了所有带有英语版权声明的图书,但请务必手动核查每本图书的元数据,确保其在您所在国家的使用合规。更多版权相关信息可参考:https://www.gutenberg.org/help/copyright.html 及 https://www.gutenberg.org/policy/permission.html;
2. 古腾堡计划对无元数据图书的使用提出如下要求:*"从古腾堡计划官网获取的电子书需附带以下法律声明:"This eBook is for the use of anyone anywhere in the United States and most other parts of the world at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Project Gutenberg License included with this eBook or online at www.gutenberg.org. If you are not located in the United States, you will have to check the laws of the country where you are located before using this eBook.""*
提供机构:
sedthh
原始信息汇总
数据集概述
数据集信息
- 特征(Features):
TEXT: 字符串类型SOURCE: 字符串类型METADATA: 字符串类型
- 分割(Splits):
train: 3127780102 字节,7907 个样本
- 下载大小: 1911528348 字节
- 数据集大小: 3127780102 字节
- 许可证: MIT
- 任务类别: 文本生成
- 语言: 西班牙语、德语、法语、荷兰语、意大利语、葡萄牙语、匈牙利语
- 标签: Project Gutenberg、电子书、gutenberg.org
- 易读名称: Project Gutenberg eBooks in different languages
- 大小类别: 1K<n<10K
数据集内容
- 语言及电子书数量:
- 西班牙语: 717 本
- 德语: 1735 本
- 法语: 2863 本
- 荷兰语: 904 本
- 意大利语: 692 本
- 葡萄牙语: 501 本
- 匈牙利语: 495 本
元数据字段
- METADATA 列包含每本书的目录元信息,以序列化的 JSON 格式存储:
language: 语言text_id: 在 Project Gutenberg 上的唯一书籍标识符,整数类型title: 书籍标题,字符串类型issued: 发行日期,字符串类型authors: 作者,字符串类型,有时包含日期并用逗号分隔subjects: 主题,字符串类型,多种格式locc: LoCC 代码,字符串类型bookshelves: 书架,可选,字符串类型
数据生成方式
- 爬虫根据 Gutenberg 目录中的 Text# id 下载每本电子书的原始 HTML 代码(如果可用)
- 元数据和文本主体未明确分离,因此使用额外的解析器尝试分割它们,然后从文本主体中移除抄写员笔记和电子书相关信息(明确标记为受版权保护或格式错误的文本被跳过并未收集)
- 清理后的文本主体以及目录元数据保存为 parquet 文件,所有列均为字符串类型
版权声明
- 部分书籍受版权保护!爬虫利用正则表达式忽略所有带有英文版权头的书籍,但请手动检查每本书的元数据,以确保它们在您所在的国家/地区可以使用!更多版权信息请参阅:https://www.gutenberg.org/help/copyright.html 和 https://www.gutenberg.org/policy/permission.html
- Project Gutenberg 在使用无元数据的书籍时有以下请求:从 Project Gutenberg 网站获取的书籍应附有以下法律声明:“本电子书供美国及世界大部分地区的任何人免费使用,几乎没有任何限制。您可以复制、赠送或重新使用它,但需遵守随本电子书提供的 Project Gutenberg 许可证或在 www.gutenberg.org 上在线提供的许可证。如果您不在美国,请在使用本电子书之前检查您所在国家/地区的法律。”
搜集汇总
数据集介绍
构建方式
在数字人文领域,大规模多语言文本资源的构建对语言模型训练至关重要。sedthh/gutenberg_multilang数据集源自古登堡计划,通过自动化爬虫系统抓取非英语电子书的原始HTML内容。针对每本图书的唯一文本标识符,系统下载对应页面后,采用专门解析器分离元数据与正文,并剔除转录者注释、版权声明及格式异常部分。清洗后的文本与编目元数据以字符串形式整合,最终存储为Parquet格式文件,涵盖西班牙语、德语、法语等七种语言,共收录7907部作品,约占该平台相关语种图书总量的75%至80%。
特点
该数据集的核心价值在于其多语言覆盖与结构化元数据设计。文本内容涵盖西班牙语、德语、法语、荷兰语、意大利语、葡萄牙语及匈牙利语七种语言,为跨语言文本生成研究提供了丰富素材。每一条记录均包含清洗后的正文文本、数据来源标识及序列化JSON格式的元数据字段,其中元数据详细记录了图书语言、标题、出版日期、作者、主题分类及图书馆分类代码等信息。这种设计既保留了原始文本的完整性,又通过标准化元数据增强了数据的可检索性与可分析性,尤其适用于需要结合文本内容与书目信息的多任务学习场景。
使用方法
在自然语言处理应用中,该数据集主要服务于多语言文本生成模型的训练与评估。研究人员可直接加载Parquet格式文件,利用TEXT字段作为模型输入进行自回归训练或微调。METADATA字段中的结构化信息可用于构建条件生成任务,例如依据作者、主题或语言类别生成特定风格的文本。使用前需特别注意版权合规性,尽管数据集已通过正则表达式过滤明显版权声明,但用户仍应依据所在司法管辖区的法律,逐一核查元数据中的版权状态,并遵循古登堡计划关于无元数据图书使用的法律声明要求,确保研究应用的合法性。
背景与挑战
背景概述
在数字人文与计算语言学领域,多语言文本资源的构建对于推动跨文化自然语言处理研究具有深远意义。sedthh/gutenberg_multilang数据集由LAION-AI等研究机构于近年创建,旨在系统整合古登堡计划中七种非英语语言的电子书资源,涵盖西班牙语、德语、法语、荷兰语、意大利语、葡萄牙语及匈牙利语。该数据集的核心研究问题聚焦于为多语言文本生成、语言模型预训练及比较语言学分析提供高质量、大规模的真实语料,其构建显著丰富了低资源语言的研究素材,对促进语言技术的公平性与包容性发展产生了积极影响。
当前挑战
该数据集致力于解决多语言文本生成与理解中的语料稀缺性挑战,尤其为低资源语言模型训练提供了关键支持。在构建过程中,主要面临两大挑战:一是原始电子书中元数据与正文内容缺乏清晰分隔,需开发专门解析器以精准剥离并清洗文本;二是版权问题的复杂性,尽管通过正则表达式过滤了部分受版权保护的英文内容,但不同国家的版权法规差异要求使用者对每本书籍进行手动审查,以确保合法使用,这增加了数据合规性管理的难度。
常用场景
经典使用场景
在自然语言处理领域,多语言文本生成模型的训练常面临高质量语料稀缺的挑战。sedthh/gutenberg_multilang数据集汇集了古登堡计划中七种非英语语言的电子书文本,为跨语言文本生成任务提供了丰富的训练素材。该数据集通过精心清洗的文本内容,支持研究者构建能够理解和生成西班牙语、德语、法语等多种语言文本的生成模型,尤其在低资源语言场景下展现出独特价值。
衍生相关工作
该数据集直接衍生了Open-Assistant等多语言对话助手项目,为开源社区提供了重要的多语言训练基础。后续研究基于此开展了跨语言文本风格迁移、低资源语言模型增强等一系列创新工作。这些工作不仅拓展了多语言生成模型的边界,还催生了针对特定语言对的细粒度文本生成评估体系,形成了以文学文本为核心的多语言NLP研究生态。
数据集最近研究
最新研究方向
在数字人文与多语言自然语言处理领域,Project Gutenberg多语言电子书数据集为前沿研究提供了丰富资源。该数据集汇集了西班牙语、德语、法语等多种语言的经典文学作品,其无元数据格式特别适合用于训练跨语言生成模型。当前研究热点聚焦于利用此类高质量文学文本提升大语言模型在低资源语言上的表现,尤其是在文化特定语境下的语义理解与风格迁移任务。随着开源社区如LAION-AI推动的开放助手项目发展,该数据集在促进多语言AI助手公平性、减少语言偏见方面展现出重要价值,为构建包容性数字知识库奠定基础。
以上内容由遇见数据集搜集并总结生成


