rootsautomation/RICO-ScreenAnnotation-f
收藏Hugging Face2024-04-22 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/rootsautomation/RICO-ScreenAnnotation-f
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: cc-by-4.0
size_categories:
- 10K<n<100K
task_categories:
- image-to-text
pretty_name: RICO Screen Annotations
tags:
- screens
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
dataset_info:
features:
- name: screen_id
dtype: string
- name: screen_annotation
dtype: string
- name: file_name
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 1684182938.288
num_examples: 15548
- name: valid
num_bytes: 240141824.938
num_examples: 2311
- name: test
num_bytes: 452100376.53
num_examples: 4217
download_size: 1880458708
dataset_size: 2376425139.756
---
# Dataset Card for RICO Screen Annotations
This is a standardization of Google's Screen Annotation dataset on a subset of RICO screens, as described in their ScreenAI paper.
Unlike the original, this version transforms integer-based bounding boxes into floating-point-based bounding boxes of 2 decimal precision.
## Dataset Details
### Dataset Description
This is an image-to-text annotation format first proscribed in Google's ScreenAI paper.
The idea is to standardize an expected text output that is reasonable for the model to follow,
and fuses together things like element detection, referring expression generation/recognition, and element classification.
- **Curated by:** Google Research
- **Language(s) (NLP):** English
- **License:** CC-BY-4.0
### Dataset Sources
- **Repository:** [google-research/screen_annotation](https://github.com/google-research-datasets/screen_annotation/tree/main)
- **Paper [optional]:** [ScreenAI](https://arxiv.org/abs/2402.04615)
## Uses
### Direct Use
Pre-training of multimodal models to better understand screens.
## Dataset Structure
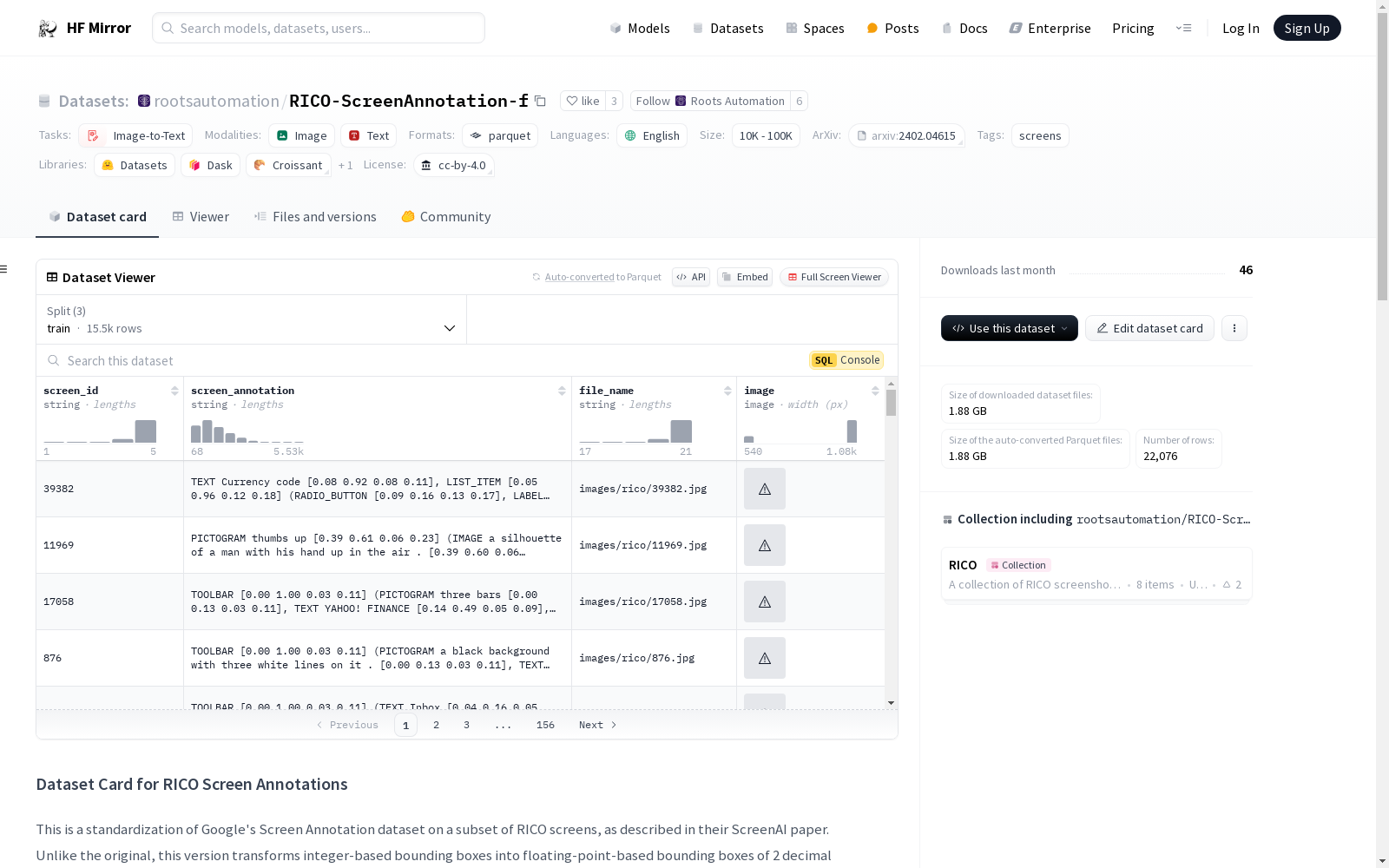
- `screen_id`: Screen ID in the RICO dataset
- `screen_annotation`: Target output string
- `image`: The RICO screenshot
## Dataset Creation
### Curation Rationale
> The Screen Annotation dataset consists of pairs of mobile screenshots and their annotations. The mobile screenshots are directly taken from the publicly available Rico dataset. The annotations are in text format, and contain information on the UI elements present on the screen: their type, their location, the text they contain or a short description. This dataset has been introduced in the paper ScreenAI: A Vision-Language Model for UI and Infographics Understanding and can be used to improve the screen understanding capabilities of multimodal (image+text) models.
## Citation
**BibTeX:**
```
@misc{baechler2024screenai,
title={ScreenAI: A Vision-Language Model for UI and Infographics Understanding},
author={Gilles Baechler and Srinivas Sunkara and Maria Wang and Fedir Zubach and Hassan Mansoor and Vincent Etter and Victor Cărbune and Jason Lin and Jindong Chen and Abhanshu Sharma},
year={2024},
eprint={2402.04615},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Dataset Card Authors
Hunter Heidenreich, Roots Automation
## Dataset Card Contact
hunter "dot" heidenreich AT rootsautomation `DOT` com
---
语言:
- en
许可协议:cc-by-4.0
规模类别:
- 10K<n<100K
任务类别:
- 图像到文本(image-to-text)
规范名称:RICO屏幕标注数据集(RICO Screen Annotations)
标签:
- 屏幕(screens)
配置项:
- 配置名称:default
数据文件:
- 拆分集:train
路径:data/train-*
- 拆分集:valid
路径:data/valid-*
- 拆分集:test
路径:data/test-*
数据集信息:
特征:
- 字段名:screen_id
数据类型:string(字符串)
- 字段名:screen_annotation
数据类型:string(字符串)
- 字段名:file_name
数据类型:string(字符串)
- 字段名:image
数据类型:image(图像)
拆分详情:
- 拆分集:train
字节数:1684182938.288
样本数:15548
- 拆分集:valid
字节数:240141824.938
样本数:2311
- 拆分集:test
字节数:452100376.53
样本数:4217
下载大小:1880458708
数据集总大小:2376425139.756
---
# RICO屏幕标注数据集数据集卡片
本数据集是对谷歌《ScreenAI》论文中提及的RICO屏幕子集的屏幕标注数据集的标准化版本。与原始版本不同,本版本将基于整数的边界框转换为保留两位小数精度的浮点型边界框。
## 数据集详情
### 数据集描述
本数据集采用谷歌在《ScreenAI》论文中首次提出的图像到文本(image-to-text)标注格式。其核心思路是标准化模型可遵循的合理预期文本输出格式,融合了元素检测、指代表达式生成/识别以及元素分类等多项任务。
- **整理方:** Google Research
- **自然语言处理所用语言:** 英语
- **许可协议:** CC-BY-4.0
### 数据集来源
- **代码仓库:** [google-research/screen_annotation](https://github.com/google-research-datasets/screen_annotation/tree/main)
- **相关论文(可选):** [ScreenAI](https://arxiv.org/abs/2402.04615)
## 数据集用途
### 直接使用场景
用于预训练多模态模型,以提升其屏幕内容理解能力。
## 数据集结构
- `screen_id`:RICO数据集中的屏幕ID
- `screen_annotation`:目标输出文本字符串
- `image`:RICO数据集的移动屏幕截图
## 数据集构建
### 整理依据
> 本屏幕标注数据集由移动设备屏幕截图及其对应的标注文本组成。截图直接取自公开可用的RICO数据集,标注文本以文本格式存储,包含屏幕上所有UI元素的相关信息:元素类型、位置、所含文本或简要描述。本数据集由《ScreenAI:用于UI与信息图表理解的视觉语言模型》一文提出,可用于提升多模态(图像+文本)模型的屏幕内容理解能力。
## 引用格式
**BibTeX:**
@misc{baechler2024screenai,
title={ScreenAI: A Vision-Language Model for UI and Infographics Understanding},
author={Gilles Baechler and Srinivas Sunkara and Maria Wang and Fedir Zubach and Hassan Mansoor and Vincent Etter and Victor Cărbune and Jason Lin and Jindong Chen and Abhanshu Sharma},
year={2024},
eprint={2402.04615},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
## 数据集卡片撰写者
Hunter Heidenreich, Roots Automation
## 数据集卡片联系方式
hunter.heidenreich@rootsautomation.com
提供机构:
rootsautomation
原始信息汇总
数据集卡片 for RICO Screen Annotations
数据集详情
数据集描述
这是一个图像到文本的标注格式,首次在Google的ScreenAI论文中提出。该数据集旨在标准化模型应遵循的合理文本输出,并结合元素检测、引用表达生成/识别和元素分类等功能。
- 由以下机构策划: Google Research
- 语言(NLP): 英语
- 许可证: CC-BY-4.0
数据集结构
screen_id: RICO数据集中的屏幕IDscreen_annotation: 目标输出字符串image: RICO截图
数据集创建
策划理由
Screen Annotation数据集包含移动截图及其标注对。移动截图直接来自公开可用的Rico数据集。标注以文本格式提供,包含屏幕上UI元素的信息:它们的类型、位置、包含的文本或简短描述。该数据集在ScreenAI: A Vision-Language Model for UI and Infographics Understanding论文中引入,可用于提高多模态(图像+文本)模型的屏幕理解能力。
引用
BibTeX:
@misc{baechler2024screenai, title={ScreenAI: A Vision-Language Model for UI and Infographics Understanding}, author={Gilles Baechler and Srinivas Sunkara and Maria Wang and Fedir Zubach and Hassan Mansoor and Vincent Etter and Victor Cărbune and Jason Lin and Jindong Chen and Abhanshu Sharma}, year={2024}, eprint={2402.04615}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
该数据集源自Google的Screen Annotation项目,专注于移动屏幕截图及其注释的标准化。具体而言,数据集从公开的RICO数据集中提取移动屏幕截图,并生成相应的文本注释,涵盖UI元素的类型、位置及内容描述。此过程旨在为多模态模型提供高质量的训练数据,以增强其对屏幕内容的理解能力。
特点
RICO-ScreenAnnotation-f数据集的显著特点在于其注释的精细度与标准化。不同于原始数据集中的整数边界框,本数据集采用浮点数边界框,精度达到两位小数,从而提高了注释的准确性。此外,数据集的结构设计合理,包含屏幕ID、注释文本及对应的屏幕截图,便于模型进行图像与文本的联合处理。
使用方法
该数据集适用于多模态模型的预训练,特别是那些需要理解屏幕内容的模型。用户可以通过提供的配置文件,分别访问训练集、验证集和测试集,进行模型的训练与评估。数据集的结构清晰,用户可以方便地提取所需的屏幕ID、注释文本及图像数据,进行定制化的模型开发与优化。
背景与挑战
背景概述
RICO-ScreenAnnotation-f数据集是由Google Research团队精心策划的,旨在标准化Google的Screen Annotation数据集,并基于RICO数据集的子集进行构建。该数据集首次在ScreenAI论文中提出,主要用于多模态模型的预训练,以增强对屏幕内容的理解。其核心研究问题在于将整数基的边界框转换为浮点基的边界框,并确保其精度达到两位小数。这一创新不仅提升了数据集的精确性,还为图像与文本的融合提供了新的标准。通过结合元素检测、引用表达生成与识别以及元素分类,该数据集在UI和信息图表理解领域展现了显著的影响力。
当前挑战
RICO-ScreenAnnotation-f数据集在构建过程中面临多项挑战。首先,将整数基的边界框转换为浮点基的边界框,并确保其精度达到两位小数,这一过程需要高精度的计算和数据处理技术。其次,数据集的标注工作复杂,涉及对UI元素的类型、位置及文本内容的详细描述,这要求标注人员具备高度的专业性和一致性。此外,数据集的规模较大,包含超过2万个样本,如何高效地管理和处理这些数据也是一个重要挑战。最后,该数据集的应用场景广泛,涉及多模态模型的预训练,如何在不同模型和任务中保持数据的一致性和有效性,也是研究者需要解决的问题。
常用场景
经典使用场景
在多模态模型预训练领域,RICO-ScreenAnnotation-f数据集以其独特的图像到文本注释格式,成为理解和解析移动设备屏幕内容的重要资源。该数据集通过融合元素检测、引用表达生成与识别以及元素分类等多项任务,为模型提供了丰富的训练数据,使其能够更准确地理解和生成屏幕内容的描述。
衍生相关工作
基于RICO-ScreenAnnotation-f数据集,研究者们开发了多种多模态模型,如ScreenAI,这些模型在UI和信息图表理解方面表现出色。此外,该数据集还激发了大量关于视觉语言模型和用户界面自动化的研究,推动了相关领域的技术进步。这些衍生工作不仅丰富了学术研究,也为实际应用提供了强有力的技术支持。
数据集最近研究
最新研究方向
在人机交互领域,RICO-ScreenAnnotation-f数据集的最新研究方向主要集中在多模态模型的预训练与优化上。该数据集通过整合图像与文本信息,旨在提升模型对用户界面(UI)和信息图表的理解能力。研究者们正致力于开发更为精准的元素检测、指代表达生成与识别以及元素分类技术,以期在实际应用中实现更高效的屏幕内容解析与交互。这一研究方向不仅推动了视觉与语言模型的融合,也为智能设备的用户体验优化提供了新的技术支持。
以上内容由遇见数据集搜集并总结生成


