Estwld/empathetic_dialogues_llm
收藏Hugging Face2024-04-02 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/Estwld/empathetic_dialogues_llm
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: apache-2.0
size_categories:
- 10K<n<100K
task_categories:
- text-generation
dataset_info:
features:
- name: conv_id
dtype: string
- name: situation
dtype: string
- name: emotion
dtype: string
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 9321699
num_examples: 19533
- name: valid
num_bytes: 1417106
num_examples: 2770
- name: test
num_bytes: 1386509
num_examples: 2547
download_size: 6827416
dataset_size: 12125314
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
tags:
- empathetic
- ED
- dialogue
---
# Empathetic Dialogues for LLM
This repository contains a reformatted version of the Empathetic Dialogues dataset, tailored for seamless integration with Language Model (LLM) training and inference. The original dataset's format posed challenges for direct application in LLM tasks, prompting us to restructure and clean the data.
## Data Restructuring
We have implemented the following changes to enhance the dataset's usability:
1. Merged dialogues with the same `conv_id`, treating each `conv_id` as an independent dialogue session.
2. Assigned the `user` role to the initiator of each dialogue session, followed by `assistant` for the subsequent message, and so on, alternating between the two roles.
3. Retained the original `conv_id`, `emotion`, and `situation` fields to facilitate the construction of instructions.
4. Removed the `utterance_id`, `selfeval`, and `tags` fields to streamline the data.
5. Replaced instances of `'_comma_'` with `','` for improved readability.
## Data Format
Each entry in the reformatted dataset consists of the following fields:
- `conversations`: A list of dictionaries, where each dictionary represents a turn in the dialogue and contains:
- `role`: A string indicating the speaker's role, either `user` or `assistant`.
- `content`: A string containing the dialogue content.
- `conv_id`: A string representing the unique identifier for the dialogue session.
- `emotion`: A string indicating the emotional label associated with the dialogue (corresponds to the `context` field in the original dataset).
- `situation`: A string describing the situational label for the dialogue (corresponds to the `prompt` field in the original dataset).
## Important Note
In the original Empathetic Dialogues dataset, not all dialogue sessions have an even number of conversation turns. To maintain the integrity of the dataset, we have preserved this characteristic in our reformatted version. However, this peculiarity may lead to potential bugs when directly applying the dataset to LLM training or inference. Users should be mindful of this aspect when working with the data.
## Dataset Statistics
| Dataset | Total Turn | Average Turn | Average Length |
|-------------|------------|--------------|----------------|
| Train | 84,167 | 4.309 | 13.589 |
| Validation | 12,077 | 4.360 | 14.685 |
| Test | 10,972 | 4.308 | 15.499 |
语言:
- 英语
许可证:Apache-2.0
样本规模类别:
- 10K<n<100K
任务类别:
- 文本生成
数据集信息:
字段列表:
- 会话ID(conv_id):数据类型为字符串
- 场景(situation):数据类型为字符串
- 情绪(emotion):数据类型为字符串
- 对话列表(conversations):列表类型,内部元素包含:
- 内容(content):数据类型为字符串
- 角色(role):数据类型为字符串
数据集划分:
- 训练集(train):字节数9321699,样本数量19533
- 验证集(valid):字节数1417106,样本数量2770
- 测试集(test):字节数1386509,样本数量2547
下载大小:6827416
数据集总大小:12125314
配置项:
- 默认配置(default):
数据文件路径:
- 训练集:data/train-*
- 验证集:data/valid-*
- 测试集:data/test-*
标签:
- 共情式
- ED
- 对话
# 面向大语言模型(LLM)的共情式对话数据集
本仓库包含重构后的共情式对话(Empathetic Dialogues)数据集,专为适配大语言模型(LLM)的训练与推理流程而优化。原始数据集的格式无法直接应用于大语言模型任务,因此我们对其进行了结构化重构与数据清洗。
## 数据重构
我们实施了以下优化以提升数据集的易用性:
1. 合并具有相同`conv_id`的对话,将每个`conv_id`视为独立的对话会话。
2. 为每个对话会话的发起者分配`user`(用户)角色,后续消息依次交替使用`assistant`(助手)与用户角色。
3. 保留原始的`conv_id`、`emotion`与`situation`字段,便于后续指令构建。
4. 移除了`utterance_id`、`selfeval`与`tags`字段以精简数据结构。
5. 将所有`'_comma_'`替换为`','`,提升文本可读性。
## 数据格式
重构后的数据集每条数据包含以下字段:
- `conversations`:由字典组成的列表,每个字典代表一轮对话,包含:
- `role`:字符串类型,表示发言者角色,可选值为`user`(用户)或`assistant`(助手)。
- `content`:字符串类型,包含对话内容。
- `conv_id`:字符串类型,表示对话会话的唯一标识符。
- `emotion`:字符串类型,表示该对话对应的情绪标签(对应原始数据集中的`context`字段)。
- `situation`:字符串类型,表示该对话对应的场景标签(对应原始数据集中的`prompt`字段)。
## 重要说明
在原始共情式对话数据集中,并非所有对话会话的轮次均为偶数。为保持数据集的原始完整性,我们在重构版本中保留了这一特性。但该特性可能在直接将数据集用于大语言模型训练或推理时引发潜在问题,使用者在处理该数据时需留意这一点。
## 数据集统计信息
| 数据集划分 | 总对话轮次 | 平均每会话轮次 | 平均文本长度 |
|------------|------------|----------------|--------------|
| 训练集 | 84,167 | 4.309 | 13.589 |
| 验证集 | 12,077 | 4.360 | 14.685 |
| 测试集 | 10,972 | 4.308 | 15.499 |
提供机构:
Estwld
原始信息汇总
数据集概述
基本信息
- 语言: 英语
- 许可证: Apache 2.0
- 数据集大小: 10K<n<100K
- 任务类别: 文本生成
数据集结构
特征
conv_id: 字符串类型,对话的唯一标识符。situation: 字符串类型,对话的情境描述。emotion: 字符串类型,对话的情感标签。conversations: 列表类型,包含以下字段:content: 字符串类型,对话内容。role: 字符串类型,说话者的角色,可以是user或assistant。
数据分割
train: 包含 19533 个样本,总字节数为 9321699。valid: 包含 2770 个样本,总字节数为 1417106。test: 包含 2547 个样本,总字节数为 1386509。
下载和数据集大小
- 下载大小: 6827416 字节
- 数据集大小: 12125314 字节
数据集配置
- 配置名称: default
- 数据文件:
train: 路径为data/train-*valid: 路径为data/valid-*test: 路径为data/test-*
标签
empatheticEDdialogue
数据重构
改进措施
- 合并具有相同
conv_id的对话,将每个conv_id视为独立的对话会话。 - 为每个对话会话的初始者分配
user角色,后续消息分配assistant角色,以此类推,交替分配角色。 - 保留原始的
conv_id、emotion和situation字段,以方便构建指令。 - 删除
utterance_id、selfeval和tags字段,以简化数据。 - 将
_comma_替换为,,以提高可读性。
数据格式
每个条目包含以下字段:
conversations: 一个字典列表,每个字典表示对话中的一轮,包含:role: 字符串类型,表示说话者的角色,可以是user或assistant。content: 字符串类型,包含对话内容。
conv_id: 字符串类型,表示对话会话的唯一标识符。emotion: 字符串类型,表示与对话相关的情感标签。situation: 字符串类型,表示对话的情境标签。
重要提示
在原始的 Empathetic Dialogues 数据集中,并非所有对话会话都有偶数轮对话。为了保持数据集的完整性,我们在重构版本中保留了这一特性。然而,这一特点可能导致在直接应用于语言模型训练或推理时出现潜在错误。用户在使用数据时应留意这一方面。
数据集统计
| 数据集 | 总轮数 | 平均轮数 | 平均长度 |
|---|---|---|---|
| Train | 84,167 | 4.309 | 13.589 |
| Validation | 12,077 | 4.360 | 14.685 |
| Test | 10,972 | 4.308 | 15.499 |
搜集汇总
数据集介绍
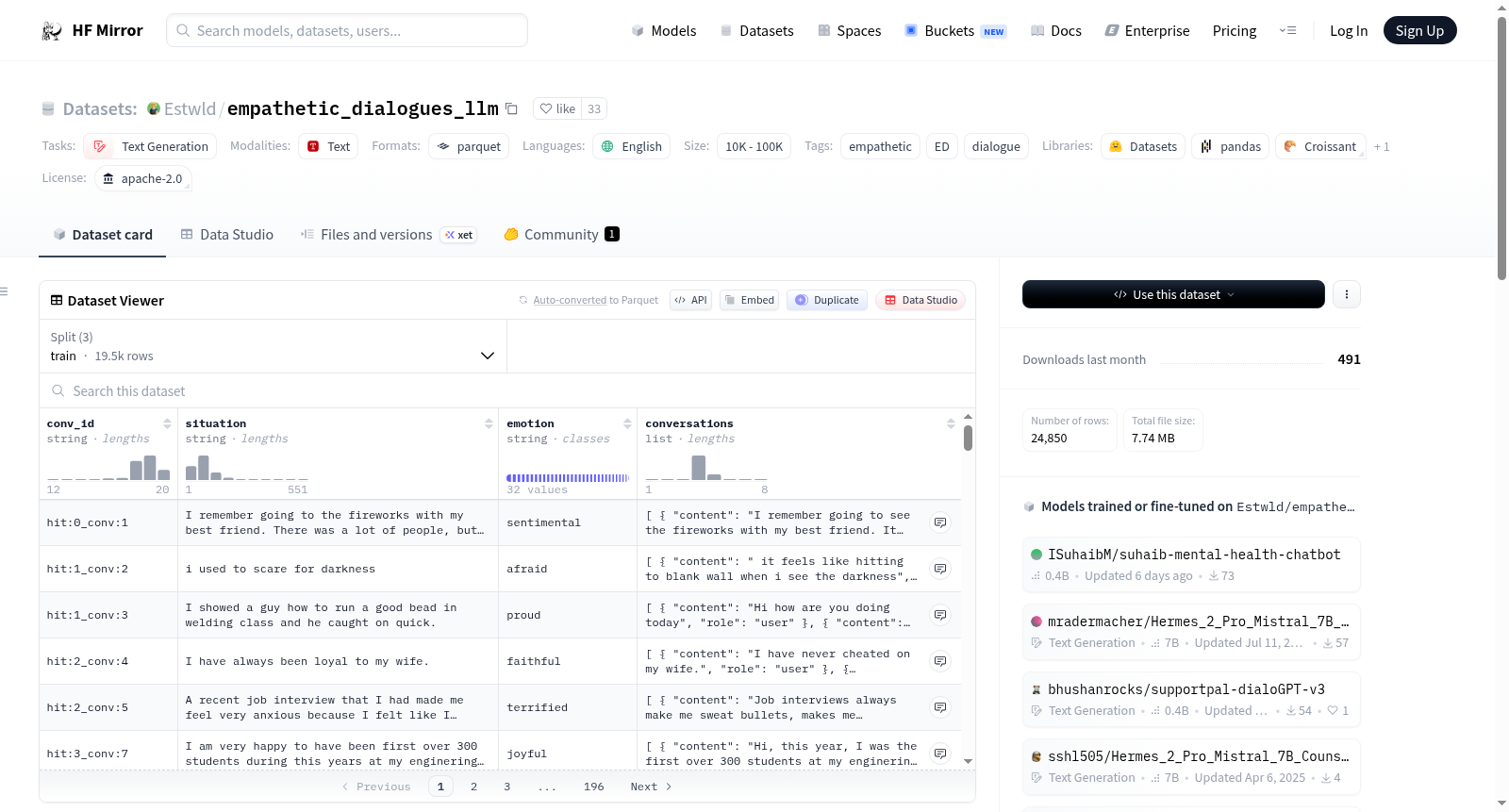
构建方式
在情感计算与人机交互领域,Empathetic Dialogues for LLM 数据集基于原始共情对话资源进行了重构。构建过程首先依据对话标识符(conv_id)合并同一会话的多个轮次,形成独立对话单元。随后,通过角色分配机制,将对话发起者标记为“用户”,后续轮次交替赋予“助手”角色,从而模拟真实交互序列。原始数据中的无关字段如话语标识符、自我评估标签等被移除,同时修正了文本中的特殊字符替换问题,例如将“_comma_”恢复为逗号,以提升语料的自然度与可读性。这一重构旨在优化数据结构,使其更适配大语言模型的训练与推理流程。
特点
该数据集的核心特征在于其情感标注的丰富性与对话结构的真实性。每条记录均包含情感标签(emotion)与情境描述(situation),为模型提供了明确的情感上下文指引。对话轮次以角色交替的列表形式组织,直观呈现用户与助手之间的互动序列。值得注意的是,数据保留了原始对话中轮次数量非均匀分布的特性,这虽可能引入训练挑战,却真实反映了人类对话的不对称性。统计显示,训练、验证与测试集的平均对话轮次约4.3轮,平均语句长度介于13至16词之间,体现了对话的简洁性与情感表达的集中性。
使用方法
使用本数据集时,可将其直接应用于大语言模型的监督微调或指令遵循训练。得益于其清晰的角色划分与内容字段,开发者能够便捷地构建输入-输出配对,例如将情境与情感标签作为指令前缀,引导模型生成共情回应。由于对话轮次可能存在奇数情况,建议在数据加载阶段实施轮次对齐检查或填充处理,以避免序列错误。数据集已按标准划分为训练、验证与测试子集,支持跨分割的评估与模型泛化能力分析,适用于情感对话生成、共情能力评估等研究任务。
背景与挑战
背景概述
Empathetic Dialogues 数据集由 Facebook AI Research 于 2019 年推出,旨在推动对话系统中情感理解与生成能力的发展。该数据集聚焦于构建能够识别并回应人类情感的对话模型,其核心研究问题在于如何使人工智能在交互过程中展现出共情能力。通过精心设计的情境与情感标签,该数据集为自然语言处理领域提供了重要的基准资源,显著促进了情感对话生成、情感识别及个性化交互等多个研究方向的前沿探索。
当前挑战
该数据集致力于解决情感对话生成领域的核心挑战,即如何使模型在多样化的情境中产生恰当且富有共情的回应。构建过程中的挑战包括对话轮次的不均衡性,部分会话的对话轮数为奇数,这可能导致在序列到序列建模或角色交替训练中出现结构不一致的问题。此外,原始数据格式与当代大语言模型训练框架的兼容性不足,需进行大量的清洗与重构工作,例如统一角色标注、移除冗余字段以及处理特殊字符,以确保数据能够高效适配于先进的生成式模型训练流程。
常用场景
经典使用场景
在情感计算与对话系统领域,Empathetic Dialogues数据集为构建具备共情能力的语言模型提供了关键训练资源。该数据集经过专门重构,以适配大语言模型的输入格式,其经典应用场景在于训练模型生成具有情感共鸣的对话回复。通过模拟真实人际互动中的情感表达,模型能够学习识别并响应多样化的情绪状态,从而在开放域对话任务中展现出更自然、更具人文关怀的交互能力。
实际应用
在实际应用层面,基于该数据集训练的模型可广泛应用于心理健康支持、智能客服、社交陪伴机器人以及交互式娱乐系统。例如,在客户服务场景中,系统能够识别用户的沮丧或焦虑情绪,并给出更具安抚性和支持性的回应,从而提升用户体验与服务满意度。这类技术正逐步融入各类需要高情商交互的数字化产品中。
衍生相关工作
该数据集催生了一系列关于情感对话生成的经典研究工作。许多研究以此为基础,探索了结合情感分类、情境理解与生成模型的混合架构。后续工作进一步拓展了其在多模态情感识别、个性化对话生成以及长程情感状态建模等方向的应用,持续推动着共情人工智能子领域的理论创新与技术演进。
以上内容由遇见数据集搜集并总结生成


