openai/webgpt_comparisons
收藏Hugging Face2022-12-19 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/openai/webgpt_comparisons
下载链接
链接失效反馈资源简介:
---
pretty_name: WebGPT Comparisons
---
# Dataset Card for WebGPT Comparisons
## Dataset Description
In the [WebGPT paper](https://arxiv.org/abs/2112.09332), the authors trained a reward model from human feedback.
They used the reward model to train a long form question answering model to align with human preferences.
This is the dataset of all comparisons that were marked as suitable for reward modeling by the end of the WebGPT project.
There are 19,578 comparisons in total.
Each example in the dataset contains a pair of model answers for a question, and the associated metadata.
Each answer has a preference score from humans that can be used to determine which of the two answers are better.
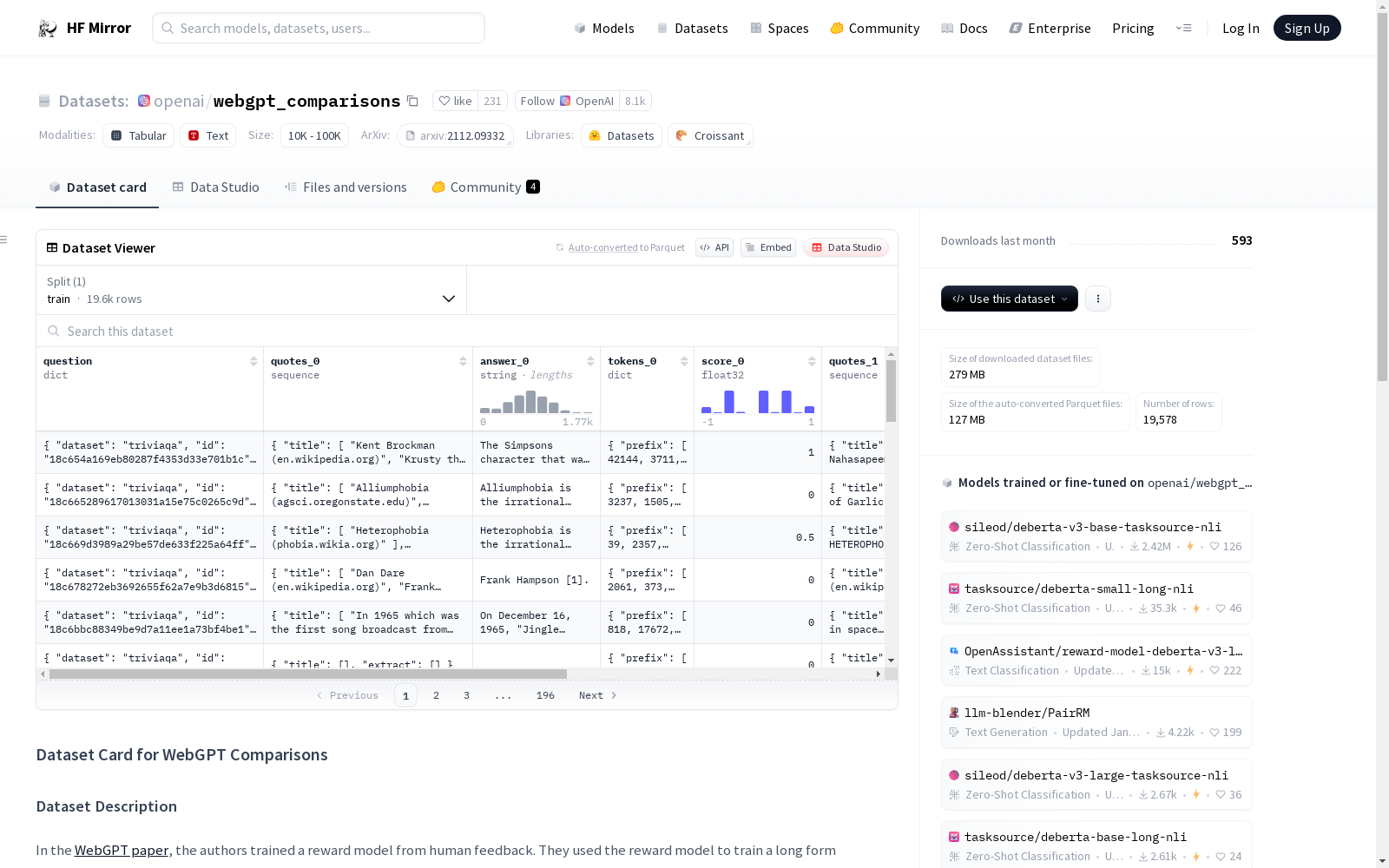
Overall, an example has the following fields:
* `question`: The text of the question, together with the name of the dataset from which it was taken and a unique ID.
* `quotes_0`: The extracts that the model found while browsing for `answer_0`, together with the title of the page on which the extract was found, constructed from the HTML title and domain name of the page.
* `answer_0`: The final answer that the model composed using `quotes_0`.
* `tokens_0`: The prefix that would have been given to the model in the final step of the episode to create `answer_0`, and the completion given by the model or human. The prefix is made up of the question and the quotes, with some truncation, and the completion is simply the answer. Both are tokenized using the GPT-2 tokenizer. The concatenation of the prefix and completion is the input used for reward modeling.
* `score_0`: The strength of the preference for `answer_0` over `answer_1` as a number from −1 to 1. It sums to 0 with `score_1`, and an answer is preferred if and only if its score is positive. For reward modeling, we treat scores of 0 as soft 50% labels, and all other scores as hard labels (using only their sign).
* `quotes_1`: The counterpart to `quotes_0`.
* `answer_1`: The counterpart to `answer_0`.
* `tokens_1`: The counterpart to `tokens_0`.
* `score_1`: The counterpart to `score_0`.
This information was found in Appendix K of the WebGPT paper.
## Citation Information
[https://arxiv.org/abs/2112.09332](https://arxiv.org/abs/2112.09332)
```
@inproceedings{nakano2021webgpt,
author = {Reiichiro Nakano and Jacob Hilton and Suchir Balaji and Jeff Wu and Long Ouyang and Christina Kim and Christopher Hesse and Shantanu Jain and Vineet Kosaraju and William Saunders and Xu Jiang and Karl Cobbe and Tyna Eloundou and Gretchen Krueger and Kevin Button and Matthew Knight and Benjamin Chess and John Schulman},
title = {WebGPT: Browser-assisted question-answering with human feedback},
booktitle = {arXiv},
year = 2021,
}
```
Dataset added to the Hugging Face Hub by [@Tristan](https://huggingface.co/Tristan) and [@natolambert](https://huggingface.co/natolambert)
---
pretty_name: WebGPT 对比数据集
---
# WebGPT 对比数据集 数据集卡片
## 数据集说明
在《WebGPT》论文(https://arxiv.org/abs/2112.09332)中,研究者通过人类反馈训练了奖励模型(reward model),并借助该奖励模型对长文本问答模型进行微调,使其对齐人类偏好。本数据集即为WebGPT项目收尾阶段标记为适用于奖励模型训练的全部对比样本集合,总计包含19578条对比数据。
数据集中的每条样本均对应某一问题的两组模型生成答案,以及相关元数据。每条答案均附带人类标注的偏好评分,用于判定两组答案的优劣。单条样本整体包含以下字段:
* `question`:问题文本,附带其来源数据集名称及唯一标识符。
* `quotes_0`:模型在检索生成`answer_0`时抓取的文本片段,以及该片段所在网页的标题(由网页HTML标题与域名组合生成)。
* `answer_0`:模型基于`quotes_0`生成的最终答案。
* `tokens_0`:对应生成`answer_0`的最终步骤中输入给模型的前缀文本,以及模型或人类生成的补全内容。其中前缀由问题与抓取片段组合后经截断处理得到,补全内容即为答案本身;二者均使用GPT-2分词器(GPT-2 tokenizer)完成分词,前缀与补全内容的拼接结果即为奖励模型训练所用的输入数据。
* `score_0`:表示`answer_0`相较于`answer_1`的偏好强度,取值范围为[-1, 1]。该评分与`score_1`之和恒为0,当且仅当某一答案的评分为正时,该答案更受人类偏好。在奖励模型训练中,评分为0的样本被视为软标签(对应50%的选择概率),其余评分则根据符号直接作为硬标签。
* `quotes_1`:`quotes_0`的对应字段。
* `answer_1`:`answer_0`的对应字段。
* `tokens_1`:`tokens_0`的对应字段。
* `score_1`:`score_0`的对应字段。
上述字段说明来自《WebGPT》论文的附录K。
## 引用信息
[https://arxiv.org/abs/2112.09332](https://arxiv.org/abs/2112.09332)
@inproceedings{nakano2021webgpt,
author = {Reiichiro Nakano and Jacob Hilton and Suchir Balaji and Jeff Wu and Long Ouyang and Christina Kim and Christopher Hesse and Shantanu Jain and Vineet Kosaraju and William Saunders and Xu Jiang and Karl Cobbe and Tyna Eloundou and Gretchen Krueger and Kevin Button and Matthew Knight and Benjamin Chess and John Schulman},
title = {WebGPT: Browser-assisted question-answering with human feedback},
booktitle = {arXiv},
year = 2021,
}
本数据集由[@Tristan](https://huggingface.co/Tristan)与[@natolambert](https://huggingface.co/natolambert)上传至Hugging Face Hub。
提供机构:
openai
原始信息汇总
数据集卡片 for WebGPT Comparisons
数据集描述
该数据集包含WebGPT项目中所有被标记为适合奖励建模的比较。总共有19,578个比较。每个示例包含一对针对某个问题的模型答案及其相关元数据。每个答案都有一个来自人类的偏好分数,用于确定两个答案中哪个更好。
每个示例包含以下字段:
question:问题的文本,以及问题来源的数据集名称和唯一ID。quotes_0:模型在浏览以生成answer_0时找到的摘录,以及摘录所在页面的标题(由页面的HTML标题和域名构成)。answer_0:模型使用quotes_0编写的最终答案。tokens_0:在生成answer_0的最后一步中会提供给模型的前缀,以及模型或人类给出的完成。前缀由问题和引用组成,并进行了一些截断,完成部分就是答案。两者都使用GPT-2分词器进行分词。前缀和完成的连接是用于奖励建模的输入。score_0:answer_0相对于answer_1的偏好强度,取值范围为-1到1。它与score_1之和为0,当且仅当其分数为正时,答案被偏好。对于奖励建模,我们将分数为0视为软50%标签,所有其他分数视为硬标签(仅使用其符号)。quotes_1:与quotes_0对应。answer_1:与answer_0对应。tokens_1:与tokens_0对应。score_1:与score_0对应。
这些信息来自WebGPT论文的附录K。
搜集汇总
数据集介绍
构建方式
WebGPT Comparisons数据集的构建基于对WebGPT论文中人类反馈训练的奖励模型的应用。该数据集收集了在WebGPT项目结束时被标记为适合奖励模型的所有比较,总计包含19,578个比较实例。每个实例由一对针对同一问题的模型答案及其相关元数据组成,其中每个答案都有一个来自人类的偏好分数,用于确定两个答案中哪一个更佳。
特点
该数据集的特点在于其包含了详细的元数据,每个实例都包括问题文本、答案来源的摘录、最终答案、用于生成答案的输入令牌以及偏好分数。偏好分数是一个介于-1到1之间的数值,表示对两个答案的偏好强度。特别地,分数为0被视为软50%标签,其他分数则根据符号作为硬标签处理,这一特性使得数据集在奖励模型训练中具有独特优势。
使用方法
使用WebGPT Comparisons数据集时,研究者可以依据提供的偏好分数进行奖励模型的训练。数据集中的实例格式允许模型直接从问题、摘录和偏好分数中学习,为模型提供了一种与人类偏好对齐的有效途径。此外,该数据集的元数据结构为研究提供了丰富的上下文信息,有助于深入理解模型答案的生成过程。
背景与挑战
背景概述
WebGPT Comparisons数据集源于对WebGPT模型训练过程中的奖励模型进行研究的背景下构建。该数据集由Reiichiro Nakano等研究人员于2021年在openai的框架下创建,旨在通过人类反馈训练出的奖励模型来训练一种长篇问答模型,以符合人类偏好。数据集包含了在WebGPT项目结束时被认为适合用于奖励模型的所有比较,总计19,578个比较实例。此数据集为研究人机交互、自然语言处理和机器学习领域提供了宝贵的资源,对于推动相关技术的发展具有重要意义。
当前挑战
WebGPT Comparisons数据集构建过程中面临的挑战主要包括:1) 如何准确捕捉并量化人类偏好,将其转化为机器可理解的奖励信号;2) 在处理大量文本数据时,如何保证数据的质量和一致性,以及处理可能存在的偏差和噪音;3) 构建能够适应长篇问答场景的模型,并确保模型输出的答案能够与人类偏好相一致。这些挑战对于提升模型在实际应用中的性能至关重要。
常用场景
经典使用场景
在深度学习领域,尤其是自然语言处理任务中,WebGPT Comparisons数据集的运用至关重要。该数据集通过人类反馈训练奖励模型,进而优化长篇问答模型的输出,以符合人类偏好。其经典的使用场景在于为模型提供一对问题的答案,并通过人类给出的偏好分数来评判哪一个答案更佳,从而进行模型的奖励建模训练。
衍生相关工作
基于WebGPT Comparisons数据集的研究衍生出了众多相关的工作,如进一步探索模型奖励机制、人类反馈的整合方式以及模型输出的多样性和准确性。这些研究推动了自然语言处理领域的发展,并为构建更加智能、高效的AI系统提供了新的思路和方法。
数据集最近研究
最新研究方向
在自然语言处理领域,OpenAI的WebGPT Comparisons数据集正引领着模型训练与人类偏好对齐的前沿研究方向。该数据集源自WebGPT项目,包含19,578个经人工标注,适用于奖励模型训练的比较案例。每个案例包含一对问题答案及其元数据,并伴有来自人类的偏好评分,以判断两个答案中哪个更佳。这一研究方向的突破在于,通过奖励模型,研究者能够训练出更符合人类期望的长篇问答模型,从而推动人机交互向更深层次的智能化发展。
以上内容由遇见数据集搜集并总结生成


