RoadText-1K
收藏arXiv2020-05-19 更新2024-06-21 收录
下载链接:
http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtext-1k
下载链接
链接失效反馈官方服务:
资源简介:
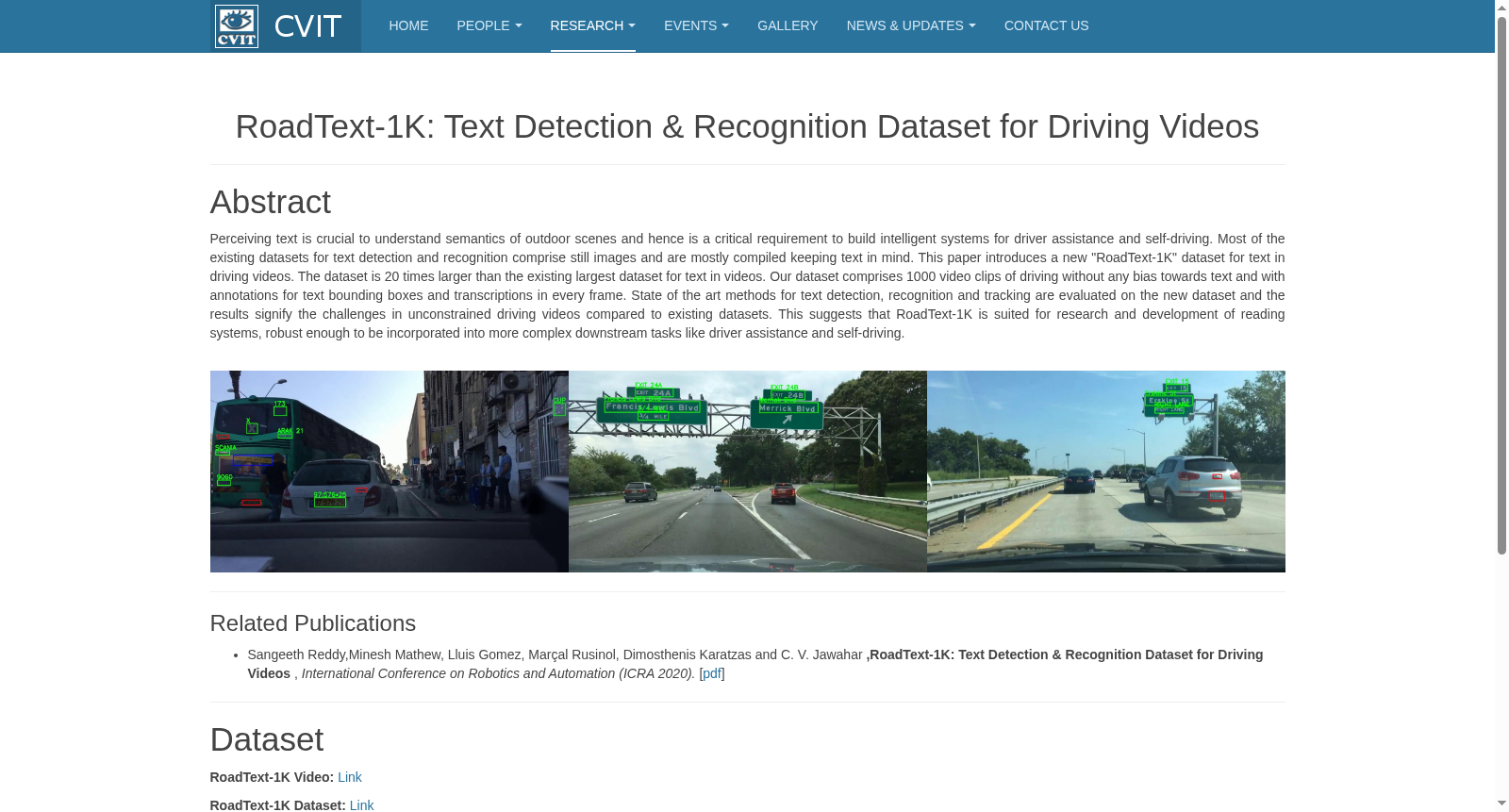
RoadText-1K是由印度海得拉巴国际信息技术研究所视觉信息中心创建的一个大规模文本检测与识别数据集,专注于驾驶视频中的文本信息。该数据集包含1000个视频片段,每个片段10秒,总计超过300,000帧,每帧都标注了文本边界框和转录。数据集的创建过程涉及从BDD100K数据集中筛选视频,手动选择视频片段,并通过两阶段标注过程进行文本实例的标注。RoadText-1K的应用领域包括自动驾驶和驾驶员辅助系统,旨在通过精确检测和识别道路上的文本,提高这些系统的智能化水平。
RoadText-1K is a large-scale text detection and recognition dataset created by the Visual Information Center at the International Institute of Information Technology, Hyderabad, India, focusing on text information in driving videos. This dataset includes 1000 video clips, each 10 seconds long, totaling over 300,000 frames. Every frame is annotated with text bounding boxes and their transcriptions. The dataset creation process involves filtering videos from the BDD100K dataset, manually selecting video clips, and annotating text instances via a two-stage annotation process. RoadText-1K has applications in autonomous driving and driver assistance systems, aiming to enhance the intelligence level of these systems by accurately detecting and recognizing text on roads.
提供机构:
印度海得拉巴国际信息技术研究所视觉信息中心(CVIT)
创建时间:
2020-05-19
搜集汇总
数据集介绍
构建方式
在自动驾驶与高级驾驶辅助系统日益成为研究热点的背景下,RoadText-1K数据集的构建旨在填补驾驶视频中文本感知研究的空白。该数据集从BDD100K驾驶视频库中精心筛选,通过预训练文本检测器初步识别包含文本的视频片段,并人工选取1000段10秒长的视频剪辑,确保场景多样性与文本丰富度。标注过程采用两阶段策略:首先使用Scalabel工具进行文本边界框标注与跨帧追踪,区分英文、非英文及难以辨识的文本类别,并对车牌进行单独标记;随后针对可读英文及车牌文本进行转录标注,利用时序冗余性提升标注效率。整个数据集包含30万帧图像,标注了超过128万个文本实例,为驾驶场景下的文本检测与识别提供了大规模、无偏且密集标注的研究资源。
特点
RoadText-1K数据集在驾驶场景文本理解领域展现出显著特点。其规模达到现有最大视频文本数据集的20倍,涵盖不同天气、光照及地理位置条件,体现了高度的多样性与真实性。数据集中文本实例广泛分布于视频帧的各区域,而非集中于画面中心,更贴合实际驾驶中摄像头非文本中心化的采集特点。此外,数据集专门区分了车牌文本与其他场景文本,并提供了文本行级别的标注而非单词级别,这既避免了分割歧义,也符合现代序列识别模型的需求。数据集中文本常面临运动模糊、低对比度、失焦等真实挑战,使得该数据集成为评估文本感知系统在复杂动态环境中鲁棒性的理想基准。
使用方法
RoadText-1K数据集主要用于推动驾驶视频中文本检测、识别与追踪算法的研究与开发。研究者可将数据集按既定划分(700段训练、300段测试)用于模型训练与评估,利用其帧级边界框与文本转录标注进行图像级文本检测与识别任务的性能验证。对于视频级任务,数据提供的跨帧追踪ID支持多目标跟踪与时空文本分析方法的探索,例如通过时序冗余性提升识别准确率。此外,数据集还可服务于下游高级驾驶辅助功能,如路标理解、临时交通提示解读等。使用中需注意其标注为文本行级别,与部分基于单词检测的预训练模型可能存在差异,建议进行适应性微调以充分发挥数据效用。
背景与挑战
背景概述
随着自动驾驶与高级驾驶辅助系统的快速发展,场景文本感知成为理解道路语义信息的关键环节。现有文本检测与识别数据集多基于静态图像,且采集过程存在文本中心化偏差,难以满足真实驾驶场景中动态、非中心化文本理解的需求。为此,印度国际信息技术学院视觉信息技术中心与西班牙计算机视觉中心的研究团队于近年联合推出了RoadText-1K数据集。该数据集源自BDD100K驾驶视频库,包含1000段未经文本偏向性筛选的10秒视频片段,共计30万帧,标注了每帧中文本的边界框与转录内容,规模达现有最大视频文本数据集的20倍。其核心研究目标是推动驾驶场景下鲁棒文本阅读系统的研发,填补真实驾驶环境中文本理解的数据空白,为自动驾驶系统的语义感知与决策提供关键支持。
当前挑战
RoadText-1K所应对的领域挑战在于驾驶视频中文本的检测与识别。真实驾驶场景中的文本常面临运动模糊、低对比度、失焦、眩光等复杂退化现象,且文本在画面中分布广泛、非中心化,与现有数据集中文本居中、清晰的特点形成显著差异。构建过程中的挑战主要体现在数据标注的复杂性上:需对每帧视频进行密集的文本边界框与转录标注,并处理文本在时序中的出现、消失、遮挡及清晰度变化;同时,为保持标注效率与一致性,需借助跟踪工具跨帧关联同一文本实例,并设计标注规范以区分英文、非英文、难以辨识及车牌文本等类别,确保标注质量与时效性。
常用场景
经典使用场景
在自动驾驶与高级驾驶辅助系统领域,RoadText-1K数据集为视频场景下的文本检测与识别研究提供了关键基准。该数据集源自真实驾驶环境,包含1000段未经文本偏置筛选的视频片段,每帧均标注了文本边界框与转录内容,其规模超越现有最大视频文本数据集20倍。经典使用场景聚焦于评估与开发鲁棒的文本阅读系统,这些系统需应对运动模糊、低对比度等驾驶视频中常见的视觉伪影,从而为复杂下游任务如实时导航决策提供可靠支持。
解决学术问题
RoadText-1K主要解决了自动驾驶研究中文本信息感知的学术空白。传统文本数据集多基于静态图像或刻意聚焦文本的视频,难以反映真实驾驶场景中文本分布广泛、非中心化且受运动干扰的特点。该数据集通过密集标注与无偏采样,推动了针对视频时序冗余的文本检测与识别方法创新,例如利用多帧跟踪与融合策略提升识别鲁棒性。其意义在于为社区提供了首个大规模、无约束的驾驶视频文本基准,显著降低了现有方法在真实场景中的性能落差,促进了端到端视频文本理解技术的发展。
衍生相关工作
RoadText-1K的发布催生了一系列围绕视频文本理解的研究工作。例如,基于多帧跟踪的端到端文本识别方法(如Wang等人工作)在该数据集上得到验证与优化,推动了时空冗余利用策略的发展。同时,数据集启发了针对驾驶场景的文本检测与跟踪融合框架(如Cheng等人的研究),这些工作通过结合时空检测器与判别性跟踪器提升视频文本定位效率。此外,数据集的评估协议促进了目标跟踪领域新指标(如IDF1、MT/ML)在文本跟踪任务中的迁移应用,为视频文本分析建立了更全面的性能评估体系。
以上内容由遇见数据集搜集并总结生成


