ys-zong/VL-ICL
收藏Hugging Face2024-05-04 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/ys-zong/VL-ICL
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- image-to-text
- text-to-image
tags:
- In-context learning
- ICL
- Multimodal
- Vision-Language
- VLLMs
size_categories:
- 1K<n<10K
---
# VL-ICL Bench
VL-ICL Bench: The Devil in the Details of Benchmarking Multimodal In-Context Learning
[[Webpage]](https://ys-zong.github.io/VL-ICL/) [[Paper]](https://arxiv.org/abs/2403.13164) [[Code]](https://github.com/ys-zong/VL-ICL)
## Image-to-Text Tasks
In all image-to-text tasks `image` is a list of image paths (typically one item - for interleaved cases there are two items).
### Fast Open-Ended MiniImageNet
Frozen introduces the task of fast concept binding for MiniImageNet. The benchmark has a fixed structure so only the given support examples can be used for a given query example. We store all support images in the `support` directory and all query images in the `query` directory. We provide a `support.json` file with information about the support images, but these do not need to be used. Because of the fixed structure of the benchmark, all needed information is stored inside `query.json` file. This file includes information about the query image, the list of artificial `classes` that can be used for constructing the task with the given query image, as well as five examples for each class (we store the image paths and the caption that refers to all these examples). We used the 5-way 5-shot setting, but we are free to take only the query example class and between one and four other classes. For our experiments we use a 2-way setting. For each class we can take up to 5 support examples. We have 200 query examples and total of 5000 support examples, but we can extend it for up to 2500 query examples with the corresponding number of support examples.
Source of data: https://fh295.github.io/frozen.html
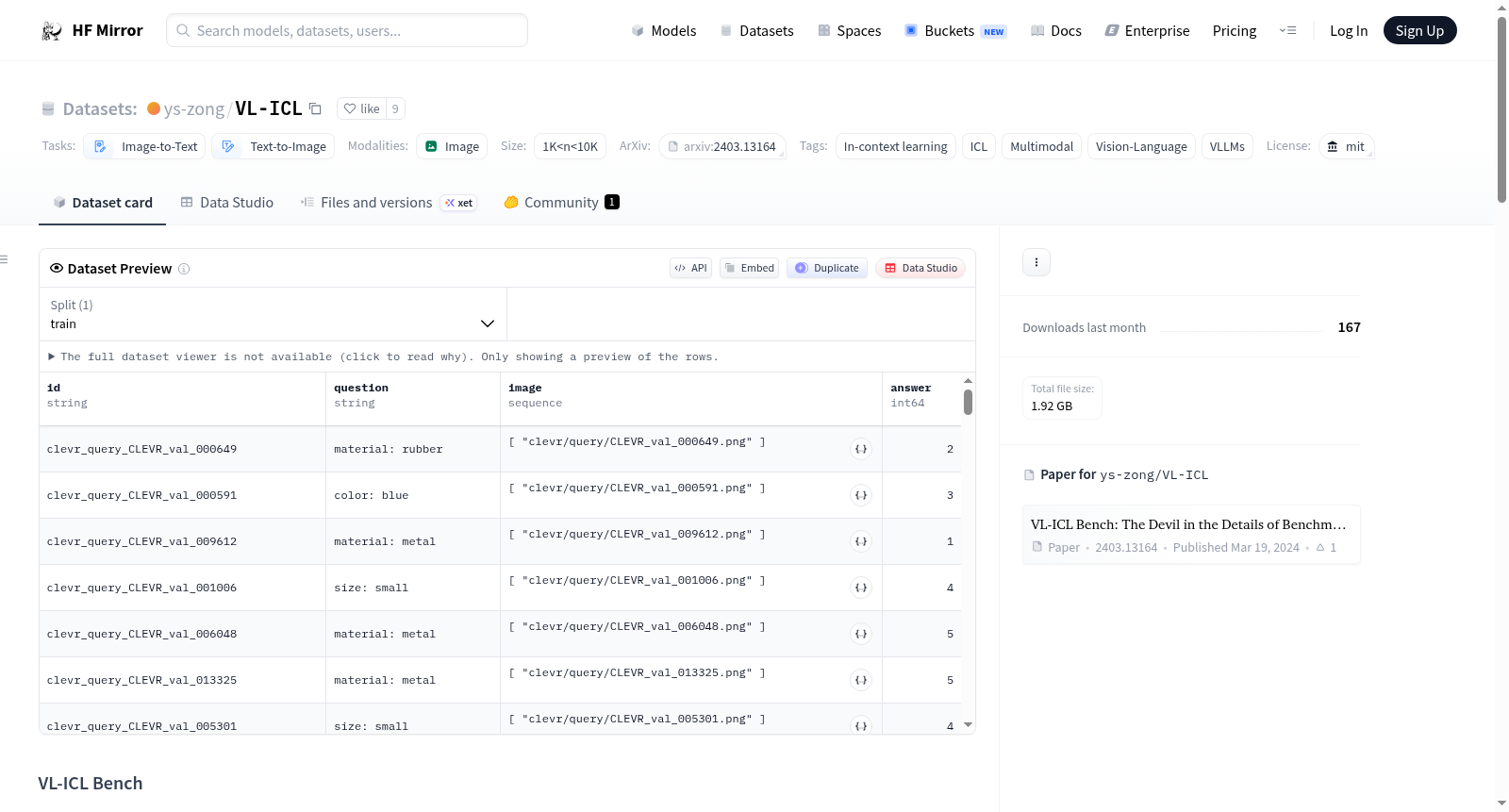
### CLEVR Count Induction
We repurpose the CLEVR dataset to construct tasks where we try to count the number of objects with a given characteristic, for example all large objects. The available attributes are shape, size, material and colour. The specified criterion is included within the `question`, for example `shape: large`, and the count itself is in the `answer`. We have 800 images in the support set and 200 in the query set.
Source of data: https://cs.stanford.edu/people/jcjohns/clevr/
### Operator Induction
The goal of this task is to predict what is the result. There is text in the image saying `A ? B`, where A and B are digits between 0 and 9. We randomly split all available options into 80 support and 60 query examples. For constructing the tasks we sample the images completely randomly, we sample the operation which `?` represents, and then take the corresponding answer. We store 3 answers for each example in a list for the support examples: `[A+B, A-B, AxB]`, and the result can be accessed with the appropriate index. The `question` that we ask is always `What is the result of the following mathematical expression?`. We generated the images using PIL library, using Arial font with size 100 on images of size 256x256. We store the `operator` for each query example, and we have 20 examples for each operator.
### Interleaved Operator Induction
We also include an alternative interleaved version of operator induction where we input the two digits as separate images. The `question` that we ask is `What is the result of the following mathematical expression?`.
### TextOCR
In TextOCR the goal is to recognize the text that is shown in the red rectangle. In our version of TextOCR there is always only one red rectangle in an image. We take the original training set for setting aside 800 support examples and the validation set for 200 query examples. We use the largest text in the image to simplify the task, and we make sure to filter out all cases that are not valid (marked as `.` in the annotation). We also filter out the rotated images. The `question` asked is `What text is shown in the red box?` and the answer is the text itself. We maintain various metadata, including the image and annotation id, width, height, box coordinates, points for the text, overall area.
Source of data: https://textvqa.org/textocr/
### MiniImageNet Matching
In this variation of MiniImageNet we try to predict if two examples are from the same class. We have 400 query pairs and 1600 support pairs, evenly distributed between same and different classes. Each support pair includes a pair of examples from the same class and a pair of examples from different classes. The `question` is always `Do the two images satisfy the induced relationship?` and the `answer` is either `Yes` or `No`. We used our earlier Fast Open-Ended MiniImageNet to create this matching dataset.
Source of data: https://fh295.github.io/frozen.html
## Text-to-Image Tasks
### Fast Open-Ended T2I MiniImageNet
We introduce a variation of Fast Open-Ended MiniImageNet where the goal is to generate an image of the imaginary class as given by the support examples. The details are similar to our other version of Fast Open-Ended MiniImageNet, but the question is instead `Generate a ` followed by the name of the imaginary class. We store the imaginary class in `task_label` field, and the real-world label in `answer` for the query examples (the support set examples have there the imaginary class). The labels were obtained from the real-world version of the benchmark. These labels can be used to assess if the generated image represents the desired imaginary class.
Source of data: https://fh295.github.io/frozen.html
### CoBSAT
We reuse the CoBSAT benchmark for few-shot image generation tasks. We have 800 support and 200 query examples, and these are organized in such a way that for each of the 100 scenarios (defined by the task -- e.g. colour, and the choice of the latent variable -- e.g. object value), we have 8 support and 2 query examples. When sampling the support examples, we need to ensure that these share the same `task` and value of the latent variable `latent`, which can be either the value of `attribute` or `object`. The `question` has the value of the latent variable and defines what image should be generated. The `image` is the generated image. The `answer` is a list [value of the latent variable, value of the non-latent variable]. For each image we also store the values of the `object`, `attribute`.
Source of data: https://github.com/UW-Madison-Lee-Lab/CoBSAT
## Text ICL Variations
We have also released the text variations of CLEVR, Operator Induction, and interleaved Operator Induction datasets to reproduce the comparison of multimodal and text ICL (Figure 7). You can either use the `query.json` in `{dataset}_text/` folder for "text support set + text query", or use the `query.json` in `{dataset}/` folder for "text support set + multimodal query".
提供机构:
ys-zong
原始信息汇总
VL-ICL Bench 数据集概述
数据集基本信息
- 许可证:MIT
- 任务类别:
- 图像到文本
- 文本到图像
- 标签:
- 情境学习(In-context learning, ICL)
- 多模态(Multimodal)
- 视觉语言(Vision-Language, VLLMs)
- 数据集大小:1K<n<10K
图像到文本任务
Fast Open-Ended MiniImageNet
- 任务描述:快速概念绑定任务,固定结构,仅使用给定的支持示例。
- 数据结构:支持图像存储在
support目录,查询图像存储在query目录。query.json文件包含查询图像信息、人工类别列表及每个类别的五个示例。 - 设置:5-way 5-shot,实验使用 2-way 设置。
- 数据量:200 查询示例,5000 支持示例,可扩展至 2500 查询示例。
CLEVR Count Induction
- 任务描述:重新利用 CLEVR 数据集,构造计数任务,例如计算具有特定特征(形状、大小、材质、颜色)的对象数量。
- 数据结构:支持集 800 图像,查询集 200 图像。
question包含特定特征,answer包含计数结果。
Operator Induction
- 任务描述:预测图像中数学表达式的结果,图像显示
A ? B,A 和 B 是 0 到 9 之间的数字。 - 数据结构:80 支持示例,60 查询示例。支持示例存储 3 个答案列表
[A+B, A-B, AxB],查询示例存储操作符。
Interleaved Operator Induction
- 任务描述:与 Operator Induction 类似,但两个数字作为单独的图像输入。
TextOCR
- 任务描述:识别红色矩形框内的文本。
- 数据结构:800 支持示例,200 查询示例。使用图像中最大的文本,过滤无效和旋转的图像。
MiniImageNet Matching
- 任务描述:预测两个示例是否来自同一类别。
- 数据结构:400 查询对,1600 支持对,均匀分布在相同和不同类别之间。
文本到图像任务
Fast Open-Ended T2I MiniImageNet
- 任务描述:生成给定支持示例的虚构类别的图像。
- 数据结构:与 Fast Open-Ended MiniImageNet 类似,但问题变为
Generate a加上虚构类别的名称。
CoBSAT
- 任务描述:用于少样本图像生成任务。
- 数据结构:800 支持示例,200 查询示例,100 个场景,每个场景 8 个支持示例和 2 个查询示例。
文本 ICL 变体
- 数据集:CLEVR、Operator Induction、Interleaved Operator Induction 的文本变体,用于多模态和文本 ICL 的比较。
搜集汇总
数据集介绍
构建方式
在视觉语言多模态学习领域,VL-ICL数据集的构建体现了对上下文学习范式的精细探索。该数据集通过整合多个经典视觉与文本资源,如MiniImageNet、CLEVR及TextOCR,并依据特定任务需求进行结构化重组。构建过程中,采用固定划分策略,将样本明确分为支持集与查询集,确保任务结构的稳定性;同时,通过人工生成或筛选方式,为数学表达式识别、文本检测等任务注入合成图像与标注,辅以严格的过滤机制排除无效或旋转样本,从而形成涵盖图像到文本与文本到图像双向任务的基准体系。
特点
VL-ICL数据集的核心特征在于其多模态与上下文学习的深度融合。数据集覆盖了从开放概念绑定到对象计数、数学运算及文本识别等多种任务类型,任务设计强调对视觉细节与语言指令的协同理解。其支持集与查询集的明确分离,以及样本间类别的灵活组合,为少样本学习提供了可控的实验环境;同时,数据集中包含交错版本任务与纯文本变体,便于研究多模态与纯文本上下文学习的性能差异,增强了基准的对比性与扩展性。
使用方法
使用VL-ICL数据集时,研究者可依据任务类型访问对应的JSON文件,其中详细定义了图像路径、问题描述及参考答案。对于图像到文本任务,需加载支持集图像与标注以构建上下文示例,随后将查询图像与问题输入模型进行预测;文本到图像任务则需依据支持集中的类别描述生成符合要求的图像。数据集支持灵活的任务配置,如调整支持样本数量与类别组合,并提供了纯文本版本用于消融实验,确保在多模态大语言模型评估中实现标准化与可复现性。
背景与挑战
背景概述
随着多模态大语言模型(VLLMs)的兴起,情境学习(ICL)已成为提升模型泛化能力的关键范式。在此背景下,由研究人员ys-zong于2024年创建的VL-ICL基准测试应运而生,旨在系统评估多模态情境学习的性能。该数据集由多个精心设计的子任务构成,涵盖图像到文本与文本到图像的双向转换,其核心研究问题聚焦于探索模型在少量示例引导下处理跨模态任务的潜力。通过整合MiniImageNet、CLEVR等经典资源,VL-ICL不仅推动了多模态学习领域的标准化评估,还为理解模型的情境适应机制提供了实证基础,对促进人工智能的通用能力发展具有显著影响力。
当前挑战
VL-ICL数据集致力于解决多模态情境学习中的核心挑战,即模型如何在有限示例中有效融合视觉与语言信息以完成复杂推理任务。具体而言,其构建过程面临多重困难:在数据整合阶段,需协调不同来源数据集(如MiniImageNet、CLEVR)的异构格式与标注标准,确保任务结构的一致性;在任务设计上,必须平衡任务的多样性与评估的公平性,例如在Fast Open-Ended MiniImageNet中模拟快速概念绑定,或在TextOCR中处理文本检测的噪声干扰。此外,数据集的扩展性亦受限于跨模态对齐的精度,如何在不引入偏差的前提下生成高质量的文本到图像示例,成为持续优化的关键难点。
常用场景
经典使用场景
在视觉-语言多模态学习领域,VL-ICL数据集为上下文学习(In-Context Learning)提供了系统化的评估基准。该数据集通过整合图像到文本与文本到图像的双向任务,如Fast Open-Ended MiniImageNet和CLEVR Count Induction,模拟了模型在少量示例下快速适应新概念的场景。研究者利用其结构化支持集与查询集,能够精准测试模型在跨模态信息融合与推理中的泛化能力,尤其适用于评估视觉-语言大模型(VLLMs)在动态上下文中的表现。
实际应用
在实际应用中,VL-ICL数据集的能力评估直接关联到智能系统的部署效果。例如,在自动化文档处理中,其TextOCR任务可优化光学字符识别系统对复杂布局的适应性;在机器人视觉交互中,MiniImageNet Matching任务能提升物体分类与匹配的准确性。此外,CoBSAT任务支持创意设计领域的图像生成,帮助系统根据文本描述合成符合特定属性的视觉内容,增强了人机协作的流畅性与实用性。
衍生相关工作
围绕VL-ICL数据集,学术界衍生了一系列经典研究工作。例如,基于其Fast Open-Ended MiniImageNet任务,研究者开发了更高效的少样本学习算法,以提升模型在新类别识别中的速度与精度。同时,对CLEVR Count Induction任务的深入分析催生了针对视觉推理的神经符号融合方法。这些工作不仅扩展了多模态上下文学习的理论框架,还为后续基准如VL-ICL Bench的构建提供了灵感,持续推动着视觉-语言模型的创新与优化。
以上内容由遇见数据集搜集并总结生成


