---
license: apache-2.0
---
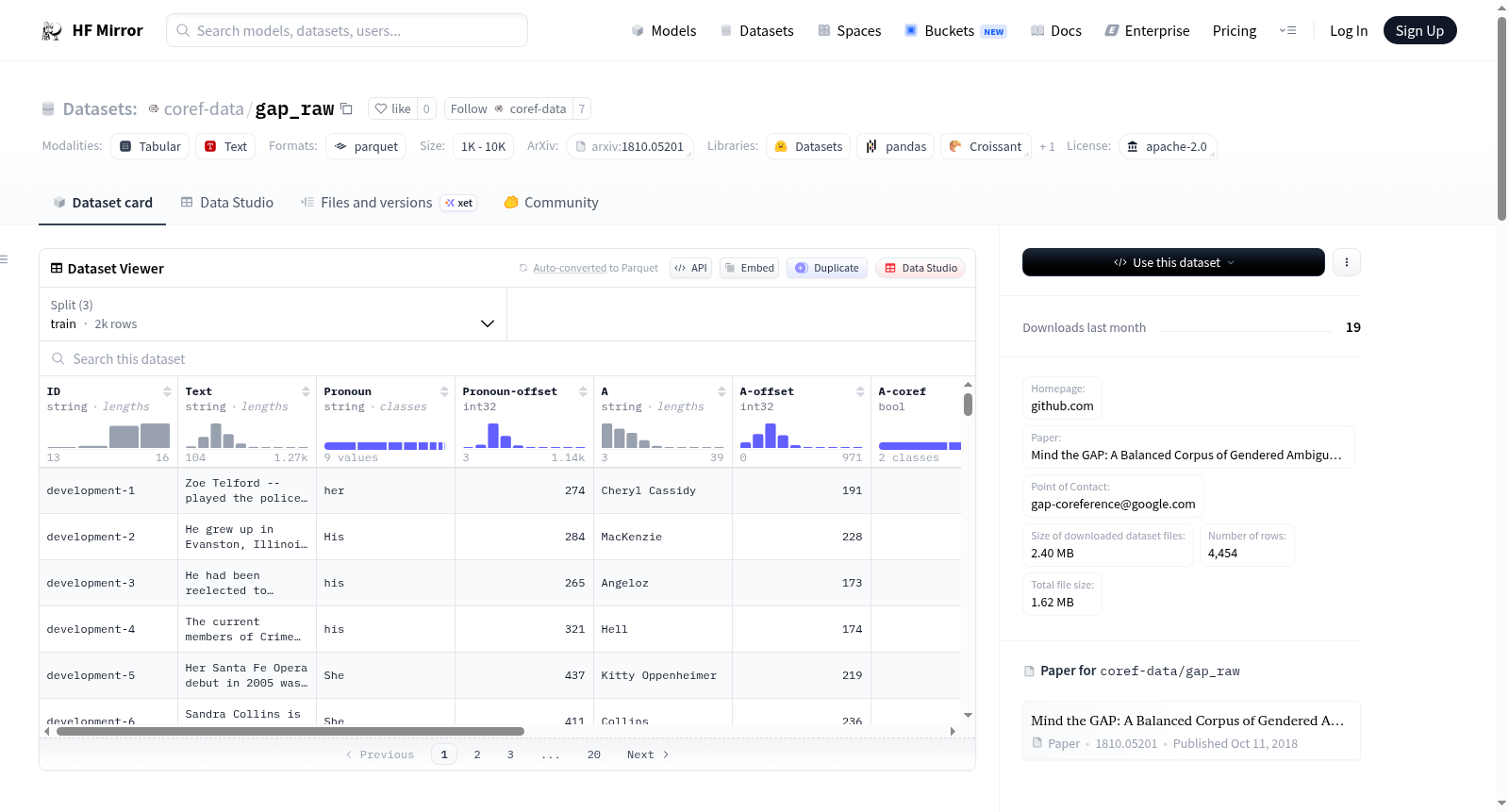
# Dataset Card for "gap"
## Dataset Description
- **Homepage:** [https://github.com/google-research-datasets/gap-coreference](https://github.com/google-research-datasets/gap-coreference)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [Mind the GAP: A Balanced Corpus of Gendered Ambiguous Pronouns](https://arxiv.org/abs/1810.05201)
- **Point of Contact:** [gap-coreference@google.com](mailto:gap-coreference@google.com)
- **Size of downloaded dataset files:** 2.40 MB
- **Size of the generated dataset:** 2.43 MB
- **Total amount of disk used:** 4.83 MB
### Dataset Summary
GAP is a gender-balanced dataset containing 8,908 coreference-labeled pairs of
(ambiguous pronoun, antecedent name), sampled from Wikipedia and released by
Google AI Language for the evaluation of coreference resolution in practical
applications.
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 2.40 MB
- **Size of the generated dataset:** 2.43 MB
- **Total amount of disk used:** 4.83 MB
An example of 'validation' looks as follows.
```
{
"A": "aliquam ultrices sagittis",
"A-coref": false,
"A-offset": 208,
"B": "elementum curabitur vitae",
"B-coref": false,
"B-offset": 435,
"ID": "validation-1",
"Pronoun": "condimentum mattis pellentesque",
"Pronoun-offset": 948,
"Text": "Lorem ipsum dolor",
"URL": "sem fringilla ut"
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `ID`: a `string` feature.
- `Text`: a `string` feature.
- `Pronoun`: a `string` feature.
- `Pronoun-offset`: a `int32` feature.
- `A`: a `string` feature.
- `A-offset`: a `int32` feature.
- `A-coref`: a `bool` feature.
- `B`: a `string` feature.
- `B-offset`: a `int32` feature.
- `B-coref`: a `bool` feature.
- `URL`: a `string` feature.
### Data Splits
| name |train|validation|test|
|-------|----:|---------:|---:|
|default| 2000| 454|2000|
### Citation Information
```
@article{webster-etal-2018-mind,
title = "Mind the {GAP}: A Balanced Corpus of Gendered Ambiguous Pronouns",
author = "Webster, Kellie and
Recasens, Marta and
Axelrod, Vera and
Baldridge, Jason",
journal = "Transactions of the Association for Computational Linguistics",
volume = "6",
year = "2018",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q18-1042",
doi = "10.1162/tacl_a_00240",
pages = "605--617",
}
```
### Contributions
Modified from dataset added by [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@otakumesi](https://github.com/otakumesi), [@lewtun](https://github.com/lewtun)
---
许可证:Apache-2.0
---
# 「GAP(Gendered Ambiguous Pronouns)」数据集卡片
## 数据集描述
- **主页**:[https://github.com/google-research-datasets/gap-coreference](https://github.com/google-research-datasets/gap-coreference)
- **仓库**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **相关论文**:[Mind the GAP: A Balanced Corpus of Gendered Ambiguous Pronouns](https://arxiv.org/abs/1810.05201)
- **联系人**:[gap-coreference@google.com](mailto:gap-coreference@google.com)
- **下载数据集文件大小**:2.40 MB
- **生成数据集大小**:2.43 MB
- **总磁盘占用量**:4.83 MB
### 数据集概述
GAP是一个性别平衡的数据集,包含8908组经过共指标注的(歧义代词,先行词名称)对,样本取自维基百科,由Google AI Language发布,用于实际应用场景下的共指消解模型评估。
## 数据集结构
### 数据实例
#### 默认拆分
- **下载数据集文件大小**:2.40 MB
- **生成数据集大小**:2.43 MB
- **总磁盘占用量**:4.83 MB
`validation` 拆分的示例如下:
{
"A": "aliquam ultrices sagittis",
"A-coref": false,
"A-offset": 208,
"B": "elementum curabitur vitae",
"B-coref": false,
"B-offset": 435,
"ID": "validation-1",
"Pronoun": "condimentum mattis pellentesque",
"Pronoun-offset": 948,
"Text": "Lorem ipsum dolor",
"URL": "sem fringilla ut"
}
### 数据字段
所有拆分下的数据字段均保持一致。
#### 默认拆分
- `ID`:字符串(string)类型特征
- `Text`:字符串类型特征
- `Pronoun`:字符串类型特征
- `Pronoun-offset`:int32 整型特征
- `A`:字符串类型特征
- `A-offset`:int32 整型特征
- `A-coref`:布尔(bool)类型特征
- `B`:字符串类型特征
- `B-offset`:int32 整型特征
- `B-coref`:布尔类型特征
- `URL`:字符串类型特征
### 数据拆分
| 拆分名称 | 训练集 | 验证集 | 测试集 |
|---------|-------:|-------:|------:|
| default | 2000 | 454 | 2000 |
### 引用信息
bibtex
@article{webster-etal-2018-mind,
title = "Mind the {GAP}: A Balanced Corpus of Gendered Ambiguous Pronouns",
author = "Webster, Kellie and
Recasens, Marta and
Axelrod, Vera and
Baldridge, Jason",
journal = "Transactions of the Association for Computational Linguistics",
volume = "6",
year = "2018",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q18-1042",
doi = "10.1162/tacl_a_00240",
pages = "605--617",
}
### 贡献说明
本数据集卡片修改自由[@thomwolf](https://github.com/thomwolf)、[@patrickvonplaten](https://github.com/patrickvonplaten)、[@otakumesi](https://github.com/otakumesi)、[@lewtun](https://github.com/lewtun) 贡献的原始数据集卡片。