BAAI/COIG-PC-core
收藏Hugging Face2024-06-14 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BAAI/COIG-PC-core
下载链接
链接失效反馈官方服务:
资源简介:
---
extra_gated_heading: "Acknowledge license to accept the repository"
extra_gated_prompt: |
北京智源人工智能研究院(以下简称“我们”或“研究院”)通过BAAI DataHub(data.baai.ac.cn)和COIG-PC HuggingFace仓库(https://huggingface.co/datasets/BAAI/COIG-PC)向您提供开源数据集(以下或称“数据集”),您可通过下载的方式获取您所需的开源数据集,并在遵守各原始数据集使用规则前提下,基于学习、研究、商业等目的使用相关数据集。
在您获取(包括但不限于访问、下载、复制、传播、使用等处理数据集的行为)开源数据集前,您应认真阅读并理解本《COIG-PC开源数据集使用须知与免责声明》(以下简称“本声明”)。一旦您获取开源数据集,无论您的获取方式为何,您的获取行为均将被视为对本声明全部内容的认可。
1. 平台的所有权与运营权
您应充分了解并知悉,BAAI DataHub和COIG-PC HuggingFace仓库(包括当前版本及全部历史版本)的所有权与运营权归智源人工智能研究院所有,智源人工智能研究院对本平台/本工具及开源数据集开放计划拥有最终解释权和决定权。
您知悉并理解,基于相关法律法规更新和完善以及我们需履行法律合规义务的客观变化,我们保留对本平台/本工具进行不定时更新、维护,或者中止乃至永久终止提供本平台/本工具服务的权利。我们将在合理时间内将可能发生前述情形通过公告或邮件等合理方式告知您,您应当及时做好相应的调整和安排,但我们不因发生前述任何情形对您造成的任何损失承担任何责任。
2. 开源数据集的权利主张
为了便于您基于学习、研究、商业的目的开展数据集获取、使用等活动,我们对第三方原始数据集进行了必要的格式整合、数据清洗、标注、分类、注释等相关处理环节,形成可供本平台/本工具用户使用的开源数据集。
您知悉并理解,我们不对开源数据集主张知识产权中的相关财产性权利,因此我们亦无相应义务对开源数据集可能存在的知识产权进行主动识别和保护,但这不意味着我们放弃开源数据集主张署名权、发表权、修改权和保护作品完整权(如有)等人身性权利。而原始数据集可能存在的知识产权及相应合法权益由原权利人享有。
此外,向您开放和使用经合理编排、加工和处理后的开源数据集,并不意味着我们对原始数据集知识产权、信息内容等真实、准确或无争议的认可,您应当自行筛选、仔细甄别,使用经您选择的开源数据集。您知悉并同意,研究院对您自行选择使用的原始数据集不负有任何无缺陷或无瑕疵的承诺义务或担保责任。
3. 开源数据集的使用限制
您使用数据集不得侵害我们或任何第三方的合法权益(包括但不限于著作权、专利权、商标权等知识产权与其他权益)。
获取开源数据集后,您应确保对开源数据集的使用不超过原始数据集的权利人以公示或协议等形式明确规定的使用规则,包括原始数据的使用范围、目的和合法用途等。我们在此善意地提请您留意,如您对开源数据集的使用超出原始数据集的原定使用范围及用途,您可能面临侵犯原始数据集权利人的合法权益例如知识产权的风险,并可能承担相应的法律责任。
4. 个人信息保护
基于技术限制及开源数据集的公益性质等客观原因,我们无法保证开源数据集中不包含任何个人信息,我们不对开源数据集中可能涉及的个人信息承担任何法律责任。
如开源数据集涉及个人信息,我们不对您使用开源数据集可能涉及的任何个人信息处理行为承担法律责任。我们在此善意地提请您留意,您应依据《个人信息保护法》等相关法律法规的规定处理个人信息。
为了维护信息主体的合法权益、履行可能适用的法律、行政法规的规定,如您在使用开源数据集的过程中发现涉及或者可能涉及个人信息的内容,应立即停止对数据集中涉及个人信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
5. 信息内容管理
我们不对开源数据集可能涉及的违法与不良信息承担任何法律责任。
如您在使用开源数据集的过程中发现开源数据集涉及或者可能涉及任何违法与不良信息,您应立即停止对数据集中涉及违法与不良信息部分的使用,并及时通过“6. 投诉与通知”中载明的联系我们。
6. 投诉与通知
如您认为开源数据集侵犯了您的合法权益,您可通过010-50955974联系我们,我们会及时依法处理您的主张与投诉。
为了处理您的主张和投诉,我们可能需要您提供联系方式、侵权证明材料以及身份证明等材料。请注意,如果您恶意投诉或陈述失实,您将承担由此造成的全部法律责任(包括但不限于合理的费用赔偿等)。
7. 责任声明
您理解并同意,基于开源数据集的性质,数据集中可能包含来自不同来源和贡献者的数据,其真实性、准确性、客观性等可能会有所差异,我们无法对任何数据集的可用性、可靠性等做出任何承诺。
在任何情况下,我们不对开源数据集可能存在的个人信息侵权、违法与不良信息传播、知识产权侵权等任何风险承担任何法律责任。
在任何情况下,我们不对您因开源数据集遭受的或与之相关的任何损失(包括但不限于直接损失、间接损失以及可得利益损失等)承担任何法律责任。
8. 其他
开源数据集处于不断发展、变化的阶段,我们可能因业务发展、第三方合作、法律法规变动等原因更新、调整所提供的开源数据集范围,或中止、暂停、终止开源数据集提供业务。
extra_gated_fields:
Name: text
Affiliation: text
Country: text
I agree to use this model for non-commercial use ONLY: checkbox
extra_gated_button_content: "Acknowledge license"
license: unknown
language:
- zh
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: task_type
struct:
- name: major
sequence: string
- name: minor
sequence: string
- name: domain
sequence: string
- name: other
dtype: string
- name: task_name_in_eng
dtype: string
- name: index
dtype: string
splits:
- name: train
num_bytes: 1053129000
num_examples: 744592
download_size: 416315627
dataset_size: 1053129000
---
# COIG Prompt Collection
## License
**Default Licensing for Sub-Datasets Without Specific License Declaration**: In instances where sub-datasets within the COIG-PC Dataset do not have a specific license declaration, the Apache License 2.0 (Apache-2.0) will be the applicable licensing terms by default.
**Precedence of Declared Licensing for Sub-Datasets**: For any sub-dataset within the COIG-PC Dataset that has an explicitly declared license, the terms and conditions of the declared license shall take precedence and govern the usage of that particular sub-dataset.
Users and developers utilizing the COIG-PC Dataset must ensure compliance with the licensing terms as outlined above. It is imperative to review and adhere to the specified licensing conditions of each sub-dataset, as they may vary.
## What is COIG-PC?
The COIG-PC Dataset is a meticulously curated and comprehensive collection of Chinese tasks and data, designed to facilitate the fine-tuning and optimization of language models for Chinese natural language processing (NLP). The dataset aims to provide researchers and developers with a rich set of resources to improve the capabilities of language models in handling Chinese text, which can be utilized in various fields such as text generation, information extraction, sentiment analysis, machine translation, among others.
If you think COIG-PC is too huge, please refer to [COIG-PC-Lite](https://huggingface.co/datasets/BAAI/COIG-PC-Lite) which is a subset of COIG-PC with only 200 samples from each task file.
## Why COIG-PC?
The COIG-PC Dataset is an invaluable resource for the domain of natural language processing (NLP) for various compelling reasons:
**Addressing Language Complexity**: Chinese is known for its intricacy, with a vast array of characters and diverse grammatical structures. A specialized dataset like COIG-PC, which is tailored for the Chinese language, is essential to adequately address these complexities during model training.
**Comprehensive Data Aggregation**: The COIG-PC Dataset is a result of an extensive effort in integrating almost all available Chinese datasets in the market. This comprehensive aggregation makes it one of the most exhaustive collections for Chinese NLP.
**Data Deduplication and Normalization**: The COIG-PC Dataset underwent rigorous manual processing to eliminate duplicate data and perform normalization. This ensures that the dataset is free from redundancy, and the data is consistent and well-structured, making it more user-friendly and efficient for model training.
**Fine-tuning and Optimization**: The dataset’s instruction-based phrasing facilitates better fine-tuning and optimization of language models. This structure allows models to better understand and execute tasks, which is particularly beneficial in improving performance on unseen or novel tasks.
The COIG-PC Dataset, with its comprehensive aggregation, meticulous selection, deduplication, and normalization of data, stands as an unmatched resource for training and optimizing language models tailored for the Chinese language and culture. It addresses the unique challenges of Chinese language processing and serves as a catalyst for advancements in Chinese NLP.
## Who builds COIG-PC?
The bedrock of COIG-PC is anchored in the dataset furnished by stardust.ai, which comprises an aggregation of data collected from the Internet.
And COIG-PC is the result of a collaborative effort involving engineers and experts from over twenty distinguished universities both domestically and internationally. Due to space constraints, it is not feasible to list all of them; however, the following are a few notable institutions among the collaborators:
- Beijing Academy of Artificial Intelligence, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/baai.png" alt= “BAAI” height="100" width="150">
- Peking University, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/pku.png" alt= “PKU” height="100" width="200">
- The Hong Kong University of Science and Technology (HKUST), China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/hkust.png" alt= “HKUST” height="100" width="200">
- The University of Waterloo, Canada
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/waterloo.png" alt= “Waterloo” height="100" width="150">
- The University of Sheffield, United Kingdom
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/sheffield.png" alt= “Sheffield” height="100" width="200">
- Beijing University of Posts and Telecommunications, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/bupt.png" alt= “BUPT” height="100" width="200">
- [Multimodal Art Projection](https://huggingface.co/m-a-p)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/map.png" alt= “M.A.P” height="100" width="200">
- stardust.ai, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/stardust.png" alt= “stardust.ai” height="100" width="200">
- LinkSoul.AI, China
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/linksoul.png" alt= “linksoul.ai” height="100" width="200">
For the detailed list of engineers involved in the creation and refinement of COIG-PC, please refer to the paper that will be published subsequently. This paper will provide in-depth information regarding the contributions and the specifics of the dataset’s development process.
## How to use COIG-PC?
COIG-PC is structured in a **.jsonl** file format. Each line in the file represents a single data record and is structured in JSON (JavaScript Object Notation) format. Below is a breakdown of the elements within each line:
**instruction**: This is a text string that provides the instruction for the task. For example, it might tell the model what to do with the input data.
**input**: This is the input data that the model needs to process. In the context of translation, it would be the text that needs to be translated.
**output**: This contains the expected output data after processing the input. In the context of translation, it would be the translated text.
**split**: Indicates the official split of the original dataset, which is used to categorize data for different phases of model training and evaluation. It can be 'train', 'test', 'valid', etc.
**task_type**: Contains major and minor categories for the dataset. Major categories are broader, while minor categories can be more specific subcategories.
**domain**: Indicates the domain or field to which the data belongs.
**other**: This field can contain additional information or metadata regarding the data record. If there is no additional information, it may be set to null.
### Example
Here is an example of how a line in the COIG-PC dataset might be structured:
```
{
"instruction": "请把下面的中文句子翻译成英文",
"input": "我爱你。",
"output": "I love you.",
"split": "train",
"task_type": {
"major": ["翻译"],
"minor": ["翻译", "中译英"]
},
"domain": ["通用"],
"other": null
}
```
In this example:
**instruction** tells the model to translate the following Chinese sentence into English.
**input** contains the Chinese text "我爱你" which means "I love you".
**output** contains the expected translation in English: "I love you".
**split** indicates that this data record is part of the training set.
**task_type** specifies that the major category is "Translation" and the minor categories are "Translation" and "Chinese to English".
**domain** specifies that this data record belongs to the general domain.
**other** is set to null as there is no additional information for this data record.
## Update: Aug. 30, 2023
- v1.0: First version of COIG-PC-core.
## COIG-PC Citation
If you want to cite COIG-PC-core dataset, you could use this:
```
@misc{zhang2023chinese,
title={Chinese Open Instruction Generalist: A Preliminary Release},
author={Ge Zhang and Yemin Shi and Ruibo Liu and Ruibin Yuan and Yizhi Li and Siwei Dong and Yu Shu and Zhaoqun Li and Zekun Wang and Chenghua Lin and Wenhao Huang and Jie Fu},
year={2023},
eprint={2304.07987},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Contact Us
To contact us feel free to create an Issue in this repository.
### 确认许可协议以接收本仓库
**额外许可提示**:
北京智源人工智能研究院(以下简称“我们”或“研究院”)通过BAAI DataHub(data.baai.ac.cn)和COIG-PC HuggingFace仓库(https://huggingface.co/datasets/BAAI/COIG-PC)向您提供开源数据集(以下或称“数据集”),您可通过下载的方式获取您所需的开源数据集,并在遵守各原始数据集使用规则前提下,基于学习、研究、商业等目的使用相关数据集。
在您获取(包括但不限于访问、下载、复制、传播、使用等处理数据集的行为)开源数据集前,您应认真阅读并理解本《COIG-PC开源数据集使用须知与免责声明》(以下简称“本声明”)。一旦您获取开源数据集,无论您的获取方式为何,您的获取行为均将被视为对本声明全部内容的认可。
1. **平台的所有权与运营权**
您应充分了解并知悉,BAAI DataHub和COIG-PC HuggingFace仓库(包括当前版本及全部历史版本)的所有权与运营权归智源人工智能研究院所有,智源人工智能研究院对本平台/本工具及开源数据集开放计划拥有最终解释权和决定权。
您知悉并理解,基于相关法律法规更新和完善以及我们需履行法律合规义务的客观变化,我们保留对本平台/本工具进行不定时更新、维护,或者中止乃至永久终止提供本平台/本工具服务的权利。我们将在合理时间内将可能发生前述情形通过公告或邮件等合理方式告知您,您应当及时做好相应的调整和安排,但我们不因发生前述任何情形对您造成的任何损失承担任何责任。
2. **开源数据集的权利主张**
为了便于您基于学习、研究、商业的目的开展数据集获取、使用等活动,我们对第三方原始数据集进行了必要的格式整合、数据清洗、标注、分类、注释等相关处理环节,形成可供本平台/本工具用户使用的开源数据集。
您知悉并理解,我们不对开源数据集主张知识产权中的相关财产性权利,因此我们亦无相应义务对开源数据集可能存在的知识产权进行主动识别和保护,但这不意味着我们放弃开源数据集主张署名权、发表权、修改权和保护作品完整权(如有)等人身性权利。而原始数据集可能存在的知识产权及相应合法权益由原权利人享有。
此外,向您开放和使用经合理编排、加工和处理后的开源数据集,并不意味着我们对原始数据集知识产权、信息内容等真实、准确或无争议的认可,您应当自行筛选、仔细甄别,使用经您选择的开源数据集。您知悉并同意,研究院对您自行选择使用的原始数据集不负有任何无缺陷或无瑕疵的承诺义务或担保责任。
3. **开源数据集的使用限制**
您使用数据集不得侵害我们或任何第三方的合法权益(包括但不限于著作权、专利权、商标权等知识产权与其他权益)。
获取开源数据集后,您应确保对开源数据集的使用不超过原始数据集的权利人以公示或协议等形式明确规定的使用规则,包括原始数据的使用范围、目的和合法用途等。我们在此善意地提请您留意,如您对开源数据集的使用超出原始数据集的原定使用范围及用途,您可能面临侵犯原始数据集权利人的合法权益例如知识产权的风险,并可能承担相应的法律责任。
4. **个人信息保护**
基于技术限制及开源数据集的公益性质等客观原因,我们无法保证开源数据集中不包含任何个人信息,我们不对开源数据集中可能涉及的个人信息承担任何法律责任。
如开源数据集涉及个人信息,我们不对您使用开源数据集可能涉及的任何个人信息处理行为承担法律责任。我们在此善意地提请您留意,您应依据《个人信息保护法》等相关法律法规的规定处理个人信息。
为了维护信息主体的合法权益、履行可能适用的法律、行政法规的规定,如您在使用开源数据集的过程中发现涉及或者可能涉及个人信息的内容,应立即停止对数据集中涉及个人信息部分的使用,并及时通过“6. 投诉与通知”中载明的方式联系我们。
5. **信息内容管理**
我们不对开源数据集可能涉及的违法与不良信息承担任何法律责任。
如您在使用开源数据集的过程中发现开源数据集涉及或者可能涉及任何违法与不良信息,您应立即停止对数据集中涉及违法与不良信息部分的使用,并及时通过“6. 投诉与通知”中载明的方式联系我们。
6. **投诉与通知**
如您认为开源数据集侵犯了您的合法权益,您可通过010-50955974联系我们,我们会及时依法处理您的主张与投诉。
为了处理您的主张和投诉,我们可能需要您提供联系方式、侵权证明材料以及身份证明等材料。请注意,如果您恶意投诉或陈述失实,您将承担由此造成的全部法律责任(包括但不限于合理的费用赔偿等)。
7. **责任声明**
您理解并同意,基于开源数据集的性质,数据集中可能包含来自不同来源和贡献者的数据,其真实性、准确性、客观性等可能会有所差异,我们无法对任何数据集的可用性、可靠性等做出任何承诺。
在任何情况下,我们不对开源数据集可能存在的个人信息侵权、违法与不良信息传播、知识产权侵权等任何风险承担任何法律责任。
在任何情况下,我们不对您因开源数据集遭受的或与之相关的任何损失(包括但不限于直接损失、间接损失以及可得利益损失等)承担任何法律责任。
8. **其他**
开源数据集处于不断发展、变化的阶段,我们可能因业务发展、第三方合作、法律法规变动等原因更新、调整所提供的开源数据集范围,或中止、暂停、终止开源数据集提供业务。
**表单字段**:
- 姓名(Name):文本框
- 所属机构(Affiliation):文本框
- 国家/地区(Country):文本框
- 我仅同意将本模型用于非商业用途(I agree to use this model for non-commercial use ONLY):复选框
**确认按钮**:确认许可
---
# COIG 提示词集
## 许可协议
**无特定许可声明的子数据集默认许可规则**:若COIG-PC数据集内的子数据集未明确声明许可,则默认适用Apache许可2.0版(Apache License 2.0,Apache-2.0)的许可条款。
**子数据集声明许可的优先级**:若COIG-PC数据集内的子数据集已明确声明许可,则该声明的许可条款将优先适用,管辖该子数据集的使用。
使用COIG-PC数据集的用户与开发者必须确保遵守上述许可条款。由于各子数据集的许可条件可能存在差异,因此务必查阅并遵守每个子数据集对应的具体许可规则。
## 什么是COIG-PC?
COIG-PC数据集是一套经过精心整理的综合性中文任务与数据集合,旨在助力面向中文自然语言处理(Natural Language Processing,NLP)的语言模型的微调与优化。本数据集旨在为研究者与开发者提供丰富的资源,以提升语言模型处理中文文本的能力,可应用于文本生成、信息抽取、情感分析、机器翻译等多个领域。
若您认为COIG-PC数据集规模过大,可参考[COIG-PC-Lite](https://huggingface.co/datasets/BAAI/COIG-PC-Lite),该数据集是COIG-PC的子集,每个任务文件仅包含200条样本。
## 为何选择COIG-PC?
COIG-PC数据集之所以成为自然语言处理(NLP)领域的宝贵资源,原因如下:
**适配语言复杂度**:中文以其复杂性著称,拥有海量字符与多样的语法结构。类似COIG-PC这样专为中文打造的专用数据集,对于在模型训练过程中充分应对这些语言复杂度至关重要。
**全面的数据聚合**:COIG-PC数据集通过大量工作整合了市面上几乎所有可用的中文数据集,这种全面的聚合使其成为中文NLP领域最完备的数据集集合之一。
**数据去重与标准化**:COIG-PC数据集经过严格的人工处理,以消除重复数据并完成标准化工作。这确保了数据集无冗余,数据一致且结构良好,从而更便于用户使用,提升模型训练的效率。
**适配微调与优化**:本数据集采用基于指令的表述方式,可更好地助力语言模型的微调与优化。这种结构使模型能够更好地理解并执行任务,尤其有助于提升模型在未知或新任务上的表现。
COIG-PC数据集凭借其全面的数据聚合、精心的筛选、去重与标准化处理,成为专为中文语言与文化打造的语言模型训练与优化的无与伦比的资源。它应对了中文语言处理的独特挑战,是推动中文NLP领域发展的重要助力。
## COIG-PC由谁打造?
COIG-PC的核心基础源自stardust.ai提供的数据集,该数据集整合了从互联网收集的各类数据。
COIG-PC是来自国内外二十余所顶尖高校的工程师与专家共同协作的成果。受篇幅所限,无法一一列出所有参与机构,以下为部分知名合作单位:
- 中国北京智源人工智能研究院(BAAI)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/baai.png" alt="BAAI" height="100" width="150">
- 中国北京大学(PKU)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/pku.png" alt="PKU" height="100" width="200">
- 中国香港科技大学(HKUST)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/hkust.png" alt="HKUST" height="100" width="200">
- 加拿大滑铁卢大学
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/waterloo.png" alt="Waterloo" height="100" width="150">
- 英国谢菲尔德大学
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/sheffield.png" alt="Sheffield" height="100" width="200">
- 中国北京邮电大学(BUPT)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/bupt.png" alt="BUPT" height="100" width="200">
- [多模态艺术投影团队(Multimodal Art Projection,M.A.P)](https://huggingface.co/m-a-p)
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/map.png" alt="M.A.P" height="100" width="200">
- 中国stardust.ai
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/stardust.png" alt="stardust.ai" height="100" width="200">
- 中国LinkSoul.AI
<img src="https://huggingface.co/datasets/BAAI/COIG-PC-core/resolve/main/assets/linksoul.png" alt="linksoul.ai" height="100" width="200">
如需获取参与COIG-PC创建与优化的工程师完整名单,请参阅后续将发表的学术论文,该论文将详细介绍各参与方的贡献以及数据集开发过程的具体细节。
## 如何使用COIG-PC?
COIG-PC采用**JSONL(JSON Lines)**文件格式,文件中的每一行代表一条数据记录,且采用JSON(JavaScript对象表示法,JavaScript Object Notation)格式进行组织。以下为每行数据各元素的详细说明:
**instruction(指令)**:该字段为文本字符串,用于提供任务相关的指令,例如告知模型如何处理输入数据。
**input(输入)**:该字段为模型需要处理的输入数据。以机器翻译任务为例,该字段即为需要被翻译的文本。
**output(输出)**:该字段包含处理输入数据后得到的预期输出结果。以机器翻译任务为例,该字段即为翻译后的文本。
**split(数据集划分)**:该字段用于标识原始数据集的官方划分方式,用于将数据划分为模型训练与评估的不同阶段,可选值包括'train'(训练集)、'test'(测试集)、'valid'(验证集)等。
**task_type(任务类型)**:该字段包含数据集的大类与小类分类信息,大类为更宽泛的分类,小类则为更具体的子分类。
**domain(所属领域)**:该字段用于标识数据所属的领域或行业。
**other(其他信息)**:该字段可包含数据记录的额外信息或元数据,若无额外信息,则可设为null。
### 示例
以下为COIG-PC数据集中单条数据行的结构示例:
{
"instruction": "请把下面的中文句子翻译成英文",
"input": "我爱你。",
"output": "I love you.",
"split": "train",
"task_type": {
"major": ["翻译"],
"minor": ["翻译", "中译英"]
},
"domain": ["通用"],
"other": null
}
在该示例中:
**instruction(指令)**指示模型将下述中文句子翻译为英文。
**input(输入)**包含中文文本“我爱你”,其含义为“I love you”。
**output(输出)**包含预期的英文翻译结果:“I love you”。
**split(数据集划分)**表明该数据记录属于训练集。
**task_type(任务类型)**指明大类为“翻译”,小类为“翻译”与“中译英”。
**domain(所属领域)**指明该数据记录属于通用领域。
**other(其他信息)**设为null,因为该数据记录无额外信息。
## 更新日志:2023年8月30日
- v1.0:COIG-PC-core的首个正式版本。
## COIG-PC引用格式
若需引用COIG-PC-core数据集,可使用如下格式:
@misc{zhang2023chinese,
title={Chinese Open Instruction Generalist: A Preliminary Release},
author={Ge Zhang and Yemin Shi and Ruibo Liu and Ruibin Yuan and Yizhi Li and Siwei Dong and Yu Shu and Zhaoqun Li and Zekun Wang and Chenghua Lin and Wenhao Huang and Jie Fu},
year={2023},
eprint={2304.07987},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
## 联系我们
如需联系我们,可直接在本仓库中创建Issue。
提供机构:
BAAI
原始信息汇总
COIG Prompt Collection
数据集概述
COIG-PC数据集是一个精心策划和全面的中文任务和数据集合,旨在促进语言模型在中文自然语言处理(NLP)中的微调和优化。该数据集旨在为研究人员和开发者提供丰富的资源,以提高语言模型处理中文文本的能力,可应用于文本生成、信息提取、情感分析、机器翻译等多个领域。
数据集结构
数据集以.jsonl文件格式存储,每行代表一个数据记录,结构如下:
- instruction: 提供任务指令的文本字符串。
- input: 模型需要处理的数据。
- output: 处理输入数据后的预期输出。
- task_type: 包含数据集的主要和次要分类。
- domain: 数据所属的领域或领域。
- other: 包含关于数据记录的额外信息或元数据,如果没有额外信息,则设置为null。
示例
json { "instruction": "请把下面的中文句子翻译成英文", "input": "我爱你。", "output": "I love you.", "split": "train", "task_type": { "major": ["翻译"], "minor": ["翻译", "中译英"] }, "domain": ["通用"], "other": null }
数据集版本
- v1.0: COIG-PC-core的第一个版本。
数据集许可
- 默认许可: 对于没有特定许可声明的子数据集,默认适用Apache License 2.0(Apache-2.0)。
- 声明许可优先: 对于有明确声明许可的子数据集,声明的许可条款优先适用。
数据集贡献者
COIG-PC数据集是由来自全球二十多所知名大学的工程师和专家共同构建的,包括但不限于以下机构:
- 北京智源人工智能研究院
- 北京大学
- 香港科技大学
- 滑铁卢大学
- 谢菲尔德大学
- 北京邮电大学
数据集下载与使用
数据集可通过BAAI DataHub(data.baai.ac.cn)和COIG-PC HuggingFace仓库(https://huggingface.co/datasets/BAAI/COIG-PC)获取。用户在使用数据集时应遵守各原始数据集的使用规则,并确保不侵犯任何第三方的合法权益。
搜集汇总
数据集介绍
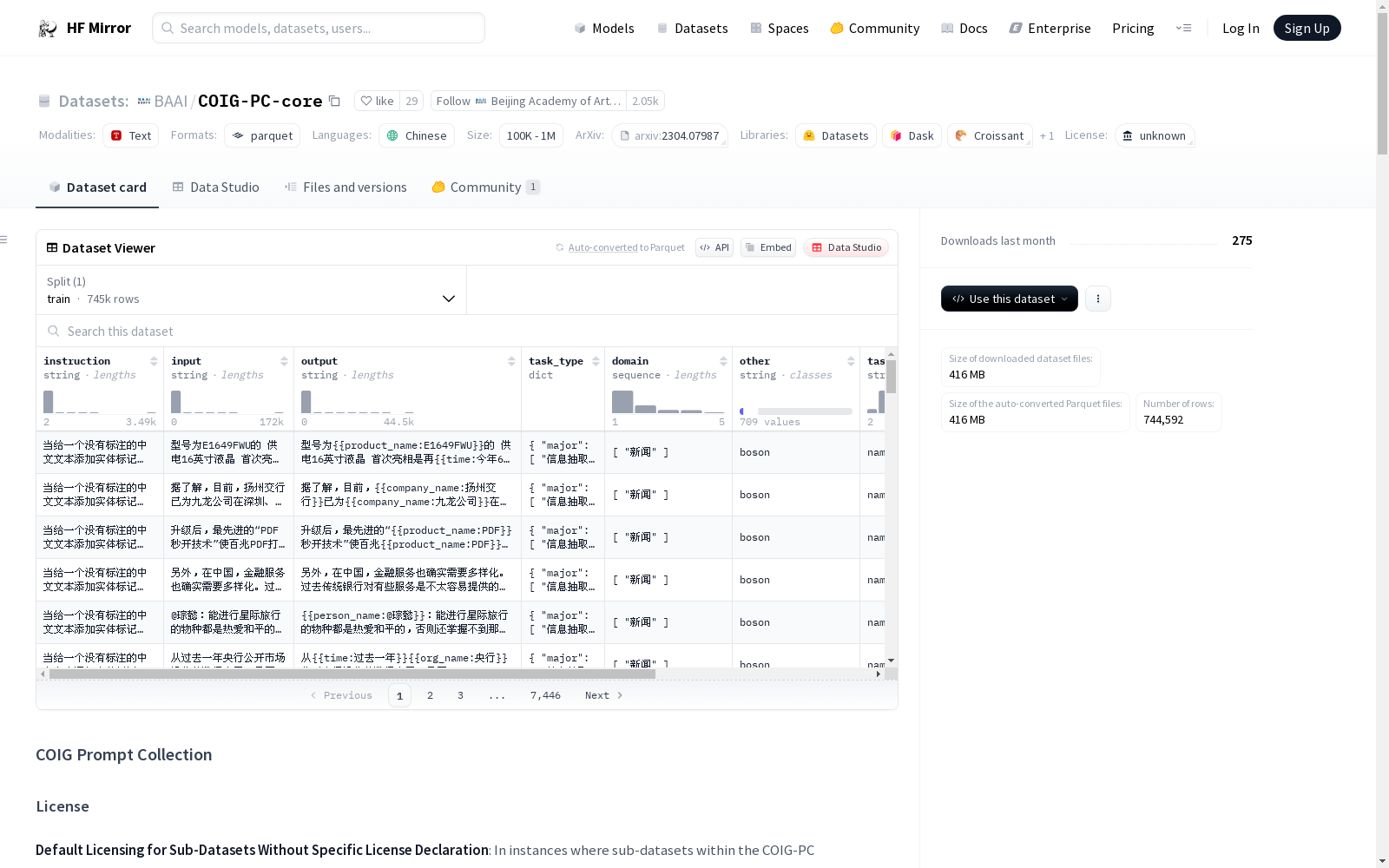
构建方式
COIG-PC-core数据集由北京智源人工智能研究院与国内外二十余所知名大学及机构的专家和工程师合作构建。该数据集以stardust.ai提供的数据为基础,通过整合市场中的几乎所有可用中文数据集,并进行数据清洗、标注、分类、注释等处理,形成了一个全面且专业的中文自然语言处理数据集。构建过程中,团队对数据进行了严格的去重和规范化处理,以确保数据的一致性和结构性,方便模型训练。
使用方法
COIG-PC-core数据集以.jsonl文件格式组织,每个数据记录都采用JSON格式。数据记录包含指令、输入数据、输出数据、数据集分割、任务类型、领域和其他信息等字段。用户可以使用Hugging Face提供的工具和库来加载和使用数据集。例如,可以使用以下代码加载训练集数据:from datasets import load_datasetdataset = load_dataset('BAAI/COIG-PC-core', 'train')print(dataset[0])
背景与挑战
背景概述
自然语言处理(NLP)领域在近年来取得了显著的进展,尤其是在中文处理方面。为了应对中文语言的复杂性和多样性,北京智源人工智能研究院联合国内外二十多所高校的工程师和专家,共同构建了COIG-PC数据集。该数据集旨在为中文NLP任务提供丰富的资源和数据,以促进语言模型在处理中文文本时的能力和性能的提升。COIG-PC数据集通过对市场上几乎所有可用中文数据集的集成,以及对数据的清洗、去重和规范化处理,为研究人员和开发者提供了一个全面、高效且易于使用的中文NLP数据集。该数据集的构建不仅推动了中文NLP领域的发展,也为其他语言的处理提供了重要的参考和借鉴。
当前挑战
尽管COIG-PC数据集在中文NLP领域具有显著的优势,但在实际应用中仍然面临着一些挑战。首先,中文语言的复杂性和多样性使得模型训练和优化过程更为困难。其次,数据集中可能包含来自不同来源和贡献者的数据,其真实性和准确性可能存在差异,这给模型训练带来了不确定性。此外,数据集中可能包含个人信息,如何在保护个人信息的前提下有效利用数据,也是需要解决的问题。最后,随着NLP技术的不断发展,如何保持数据集的更新和与时俱进,以适应新的研究需求,也是需要考虑的问题。
常用场景
经典使用场景
在自然语言处理(NLP)领域,COIG-PC-core数据集被广泛用于训练和优化针对中文的语言模型。该数据集涵盖了各种中文任务,包括文本生成、信息提取、情感分析、机器翻译等,使得语言模型能够更好地理解和处理中文文本。COIG-PC-core数据集的规模庞大,数据清洗和标注质量高,有助于提升模型的泛化能力和鲁棒性。
解决学术问题
COIG-PC-core数据集解决了中文NLP领域的一个关键问题,即缺乏大规模、高质量的中文数据集。通过整合和清洗现有数据,COIG-PC-core为研究人员和开发者提供了一个丰富的资源,促进了中文NLP技术的发展。此外,该数据集的规范化和标准化处理,也降低了数据集的使用门槛,使得更多研究者能够参与中文NLP的研究。
实际应用
COIG-PC-core数据集在多个实际应用场景中发挥着重要作用。例如,在机器翻译领域,使用COIG-PC-core训练的模型可以显著提高翻译质量,减少错误率。在文本生成领域,COIG-PC-core可以用于训练生成自然、流畅的中文文本的模型。此外,COIG-PC-core还可以用于构建智能客服系统、情感分析工具等,为中文信息处理提供有力支持。
数据集最近研究
最新研究方向
COIG-PC数据集的最新研究方向集中在利用其丰富的中文任务和数据,以促进自然语言处理(NLP)领域的发展。特别是,研究者们致力于利用COIG-PC进行语言模型的微调和优化,以提高模型在处理中文文本时的能力。此外,COIG-PC的数据去重和规范化处理为模型训练提供了高质量的数据基础,有助于提升模型在文本生成、信息提取、情感分析、机器翻译等任务上的性能。随着自然语言处理技术的不断进步,COIG-PC数据集有望成为推动中文NLP领域研究的重要力量。
以上内容由遇见数据集搜集并总结生成


