FinanceRAG
收藏魔搭社区2025-11-26 更新2025-02-15 收录
下载链接:
https://modelscope.cn/datasets/Linq-AI-Research/FinanceRAG
下载链接
链接失效反馈官方服务:
资源简介:
# Dataset Card for FinanceRAG
## Dataset Summary
The detailed description of dataset and reference will be added after the competition in [Kaggle/FinanceRAG Challenge](https://www.kaggle.com/competitions/icaif-24-finance-rag-challenge)
## Datasets
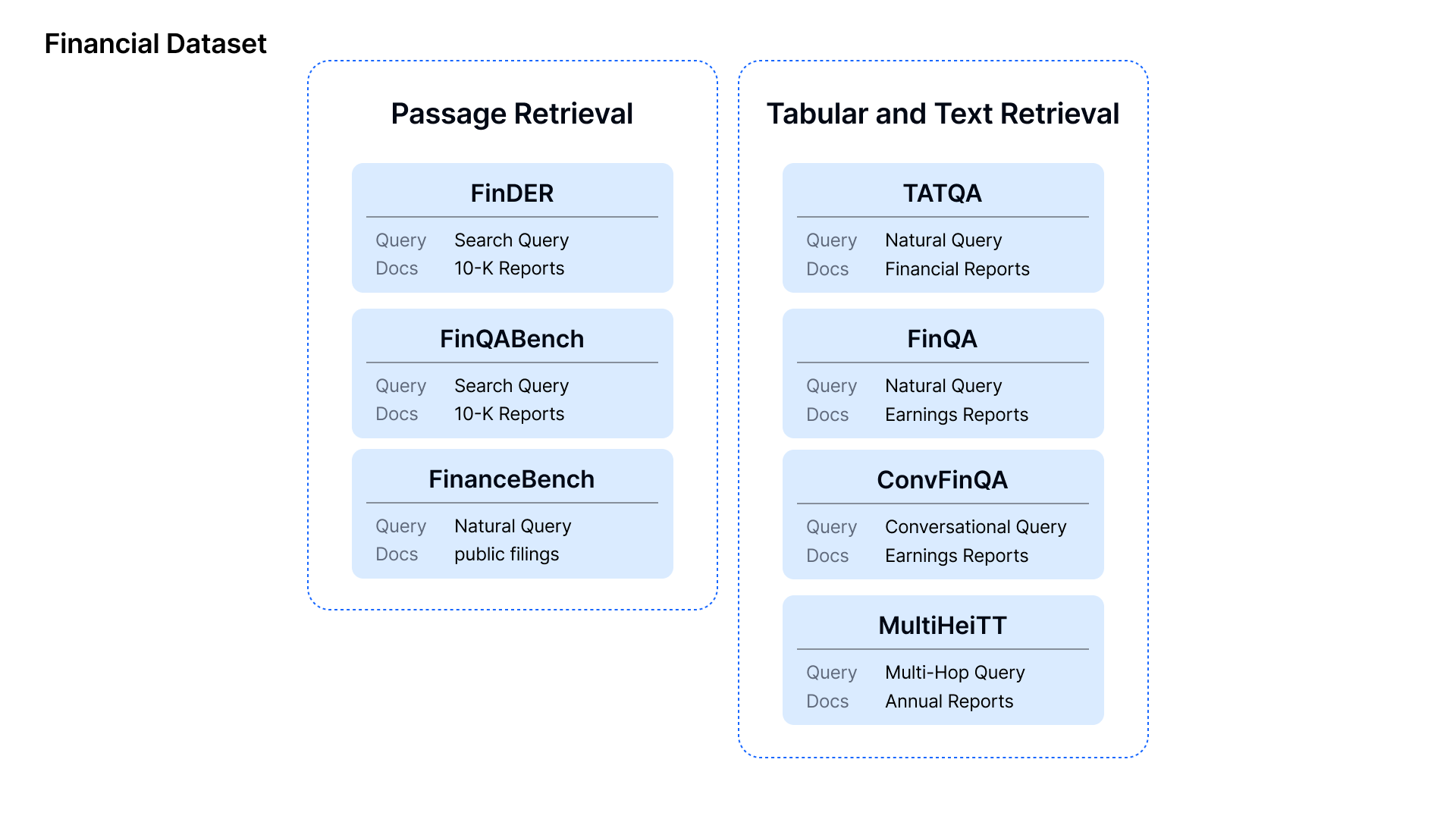
1. **Passage Retrieval**:
- **FinDER**: Involves retrieving relevant sections from **10-K Reports** and financial disclosures based on **Search Queries** that simulate real-world questions asked by financial professionals, using domain-specific jargon and abbreviations.
- **FinQABench**: Focuses on testing AI models' ability to answer **Search Queries** over **10-K Reports** with accuracy, evaluating the system's ability to detect hallucinations and ensure factual correctness in generated answers.
- **FinanceBench**: Uses **Natural Queries** to retrieve relevant information from public filings like **10-K** and **Annual Reports**. The aim is to evaluate how well systems handle straightforward, real-world financial questions.
2. **Tabular and Text Retrieval**:
- **TATQA**: Requires participants to answer **Natural Queries** that involve numerical reasoning over hybrid data, which combines tables and text from **Financial Reports**. Tasks include basic arithmetic, comparisons, and logical reasoning.
- **FinQA**: Demands answering complex **Natural Queries** over **Earnings Reports** using multi-step numerical reasoning. Participants must accurately extract and calculate data from both textual and tabular sources.
- **ConvFinQA**: Involves handling **Conversational Queries** where participants answer multi-turn questions based on **Earnings Reports**, maintaining context and accuracy across multiple interactions.
- **MultiHiertt**: Focuses on **Multi-Hop Queries**, requiring participants to retrieve and reason over hierarchical tables and unstructured text from **Annual Reports**, making this one of the more complex reasoning tasks involving multiple steps across various document sections.
## Files
For each dataset, you are provided with two files:
* **corpus.jsonl** - This is a `JSONLines` file containing the context corpus. Each line in the file represents a single document in `JSON` format.
* **queries.jsonl** - This is a `JSONLines` file containing the queries. Each line in this file represents one query in `JSON` format.
Both files follow the jsonlines format, where each line corresponds to a separate data instance in `JSON` format.
Here’s an expanded description including explanations for each line:
- **_id**: A unique identifier for the context/query.
- **title**: The title or headline of the context/query.
- **text**: The full body of the document/query, containing the main content.
### How to Use
The following code demonstrates how to load a specific subset (in this case, **FinDER**) from the **FinanceRAG** dataset on Hugging Face. In this example, we are loading the `corpus` split, which contains the document data relevant for financial analysis.
The `load_dataset` function is used to retrieve the dataset, and a loop is set up to print the first document entry from the dataset, which includes fields like `_id`, `title`, and `text`.
Each document provides detailed descriptions from financial reports, which participants can use for tasks such as retrieval and answering financial queries.
``` python
from datasets import load_dataset
# Loading a specific subset (i.e. FinDER) and a split (corpus, queries)
dataset = load_dataset("Linq-AI-Research/FinanceRAG", "FinDER", split="corpus")
for example in dataset:
print(example)
break
```
Here is an example result of `python` output of **FinDER** from the `corpus` split:
```json
{
'_id' : 'ADBE20230004',
'title': 'ADBE OVERVIEW',
'text': 'Adobe is a global technology company with a mission to change the world through personalized digital experiences...'
}
```
# 数据集卡片:FinanceRAG
## 数据集概述
数据集详情与参考文献将在本次[Kaggle/FinanceRAG挑战赛](https://www.kaggle.com/competitions/icaif-24-finance-rag-challenge)结束后补充。
## 数据集组成

1. **篇章检索(Passage Retrieval)**
- **FinDER**:基于模拟金融从业者真实业务问题的**搜索查询(Search Queries)**,从**10-K报告(10-K Reports)**与金融披露文件中检索相关段落,查询内容包含领域专属术语与缩写。
- **FinQABench**:聚焦测试AI模型基于**10-K报告(10-K Reports)**回答**搜索查询(Search Queries)**的准确性,评估系统检测幻觉(hallucination)并确保生成答案事实正确性的能力。
- **FinanceBench**:使用**自然查询(Natural Queries)**从**10-K(10-K)**与**年度报告(Annual Reports)**等公开备案文件中检索相关信息,旨在评估系统处理真实世界基础金融问题的性能。
2. **表格与文本检索(Tabular and Text Retrieval)**
- **TATQA**:要求参与者针对混合数据(结合财务报告中的表格与文本)完成数值推理类**自然查询(Natural Queries)**的作答,任务涵盖基础算术、比较与逻辑推理。
- **FinQA**:要求参与者基于**财报(Earnings Reports)**,通过多步数值推理完成复杂**自然查询(Natural Queries)**的作答,需准确从文本与表格数据源中提取并计算数据。
- **ConvFinQA**:处理**会话查询(Conversational Queries)**任务,参与者需基于**财报(Earnings Reports)**回答多轮问题,并在多轮交互中保持上下文一致性与作答准确性。
- **MultiHiertt**:聚焦**多跳查询(Multi-Hop Queries)**,要求参与者从**年度报告(Annual Reports)**的层级化表格与非结构化文本中进行信息检索与推理,该任务属于涉及多文档段落多步骤推理的复杂任务之一。
## 数据集文件
针对每个数据集,均提供两类文件:
* **corpus.jsonl**:该文件为JSONLines格式,包含上下文语料库。文件中每一行均为一条JSON格式的独立文档。
* **queries.jsonl**:该文件为JSONLines格式,包含查询语句。文件中每一行均为一条JSON格式的独立查询。
两类文件均遵循jsonlines格式规范,每一行对应一个独立的JSON格式数据实例。
以下为每一行数据的详细说明:
- **_id**:上下文/查询的唯一标识符。
- **title**:上下文/查询的标题或主题行。
- **text**:文档/查询的完整正文,包含核心内容。
### 使用方法
以下代码演示了如何从Hugging Face平台的FinanceRAG数据集中加载指定子集(此处以FinDER为例)。本示例加载的是`corpus`划分,该划分包含用于金融分析的文档数据。
我们将使用`load_dataset`函数获取数据集,并通过循环打印数据集中的首个文档条目,该条目包含`_id`、`title`与`text`等字段。
每个文档均提供了财务报告的详细描述,参与者可将其用于检索与回答金融查询等任务。
python
from datasets import load_dataset
# 加载指定子集(即FinDER)与划分(corpus、queries)
dataset = load_dataset("Linq-AI-Research/FinanceRAG", "FinDER", split="corpus")
for example in dataset:
print(example)
break
以下为从`corpus`划分中加载的FinDER数据集的Python输出示例:
json
{
'_id' : 'ADBE20230004',
'title': 'ADBE OVERVIEW',
'text': 'Adobe is a global technology company with a mission to change the world through personalized digital experiences...'
}
提供机构:
maas
创建时间:
2025-02-12
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


