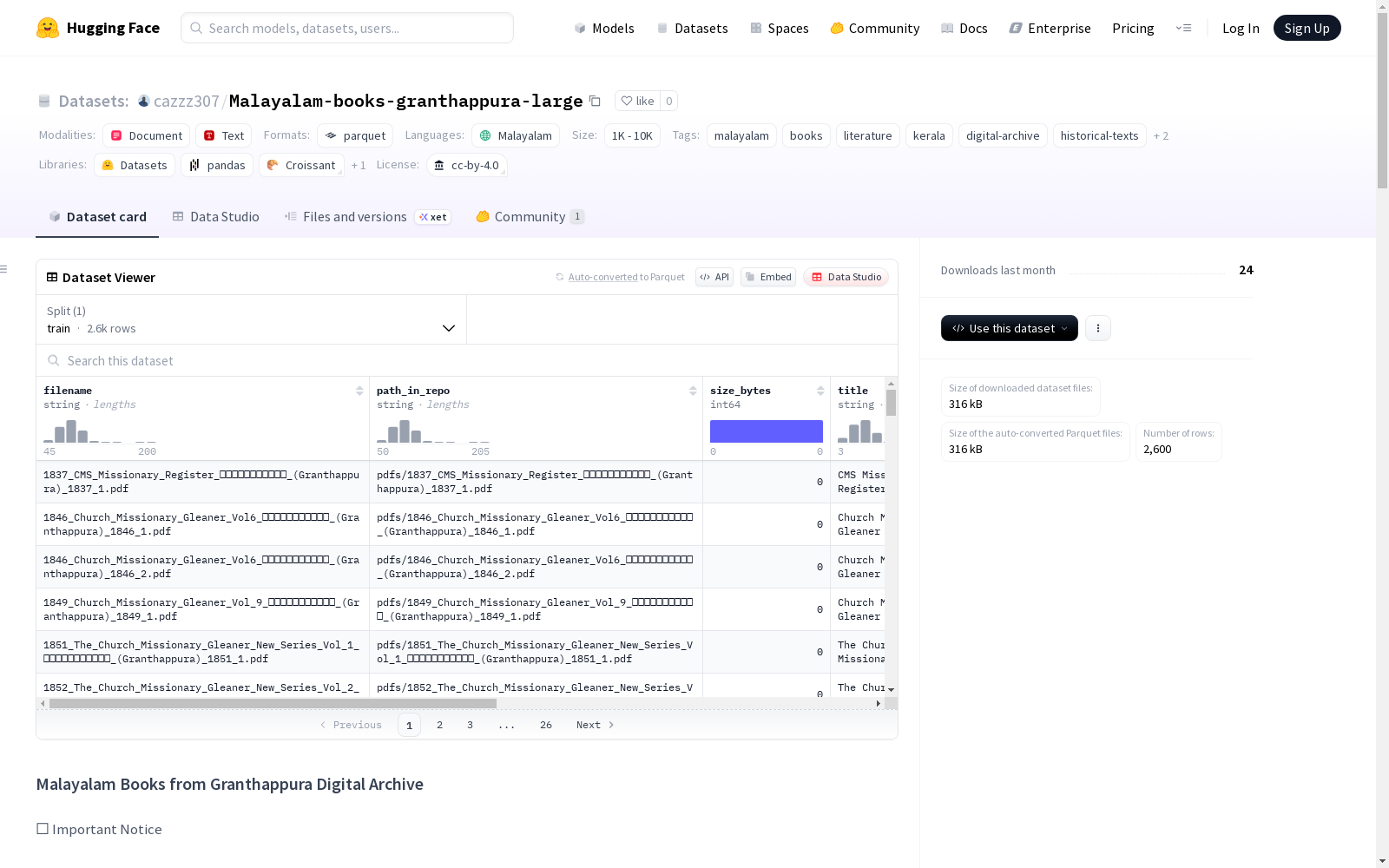
Malayalam-books-granthappura-new
收藏Malayalam Books from Granthappura (File Dataset) 概述
基本信息
- 名称: Malayalam Books from Granthappura (File Dataset)
- 语言: 马拉雅拉姆语 (ml)
- 标签: malayalam, books, literature, kerala, digital-archive, historical-texts, pdf, scanned
- 许可证: CC BY 4.0
- 规模: 1K<n<10K
数据集来源
- 原始来源: Granthappura Digital Archive (https://gpura.org)
- 内容: 历史马拉雅拉姆语书籍和文档,涵盖19世纪末至20世纪的古典文学、宗教作品、电影歌曲书籍等。
数据集结构
- PDF文件: 存储在
pdfs/目录下 (Git LFS) - 索引文件:
index/index.csv(CSV格式)index/index.parquet(Parquet格式)
索引模式
每行对应一个PDF文件,包含以下字段:
filename: PDF文件名path_in_repo: 文件在仓库中的相对路径size_bytes: 文件大小(字节)title: 从文件名解析的标题year: 出版年份author: 作者(如可解析)publisher: 通常为 "Granthappura"language: 马拉雅拉姆语 (ml)type: 类型(如book)
使用方式
选项A: 本地下载索引和PDF
python from pathlib import Path from huggingface_hub import snapshot_download import pandas as pd
repo_id = "cazzz307/Malayalam-books-granthappura-new" local_dir = snapshot_download( repo_id=repo_id, repo_type="dataset", allow_patterns=["index/", "pdfs/.pdf"], )
index_path = Path(local_dir) / "index/index.parquet" df = pd.read_parquet(index_path) print(len(df), "rows")
pdf_path = Path(local_dir) / df.loc[0, "path_in_repo"] print(pdf_path.exists())
选项B: 仅远程读取索引
python import pandas as pd repo_id = "cazzz307/Malayalam-books-granthappura-new" base = f"https://huggingface.co/datasets/{repo_id}/resolve/main/index" index_url = f"{base}/index.csv"
df = pd.read_csv(index_url) print(df.head())
import requests pdf_url = f"https://huggingface.co/datasets/{repo_id}/resolve/main/" + df.loc[0, "path_in_repo"] r = requests.get(pdf_url) open("sample.pdf", "wb").write(r.content)
使用场景
- OCR基准测试和训练(马拉雅拉姆语)
- 历史文本分析 / 数字人文
- 扫描材料的文档布局/视觉任务
- PDF检索和索引研究
伦理与权利
- 归属: 请引用并注明原始来源 — Granthappura Digital Archive (https://gpura.org)
- 权利: PDF为历史扫描件,权利归Granthappura和/或原始出版商所有
- 许可证: 数据集索引和卡片使用CC BY 4.0,但不适用于PDF内容
- 移除: 通过数据集页面联系以请求立即删除
引用
主要归属
Original Source: Granthappura Digital Archive (https://gpura.org) Kerala Digital Heritage Collection
数据集引用
Malayalam Historical Books (File Dataset) Aggregated from: Granthappura Digital Archive (https://gpura.org) Accessed: August 2025 Note: All rights remain with original source and rightsholders.
限制
- 元数据为最佳效果,可能不完整
- PDF文件较大,下载整个集合需要大量带宽和存储空间
- 未提供OCR文本,PDF为扫描件
变更日志
- 2025-08: 初始发布为文件数据集,包含紧凑索引(未在Parquet中嵌入PDF)