MLLM-CL
收藏Hugging Face2025-05-29 更新2025-05-30 收录
下载链接:
https://huggingface.co/datasets/Impression2805/MLLM-CL
下载链接
链接失效反馈官方服务:
资源简介:
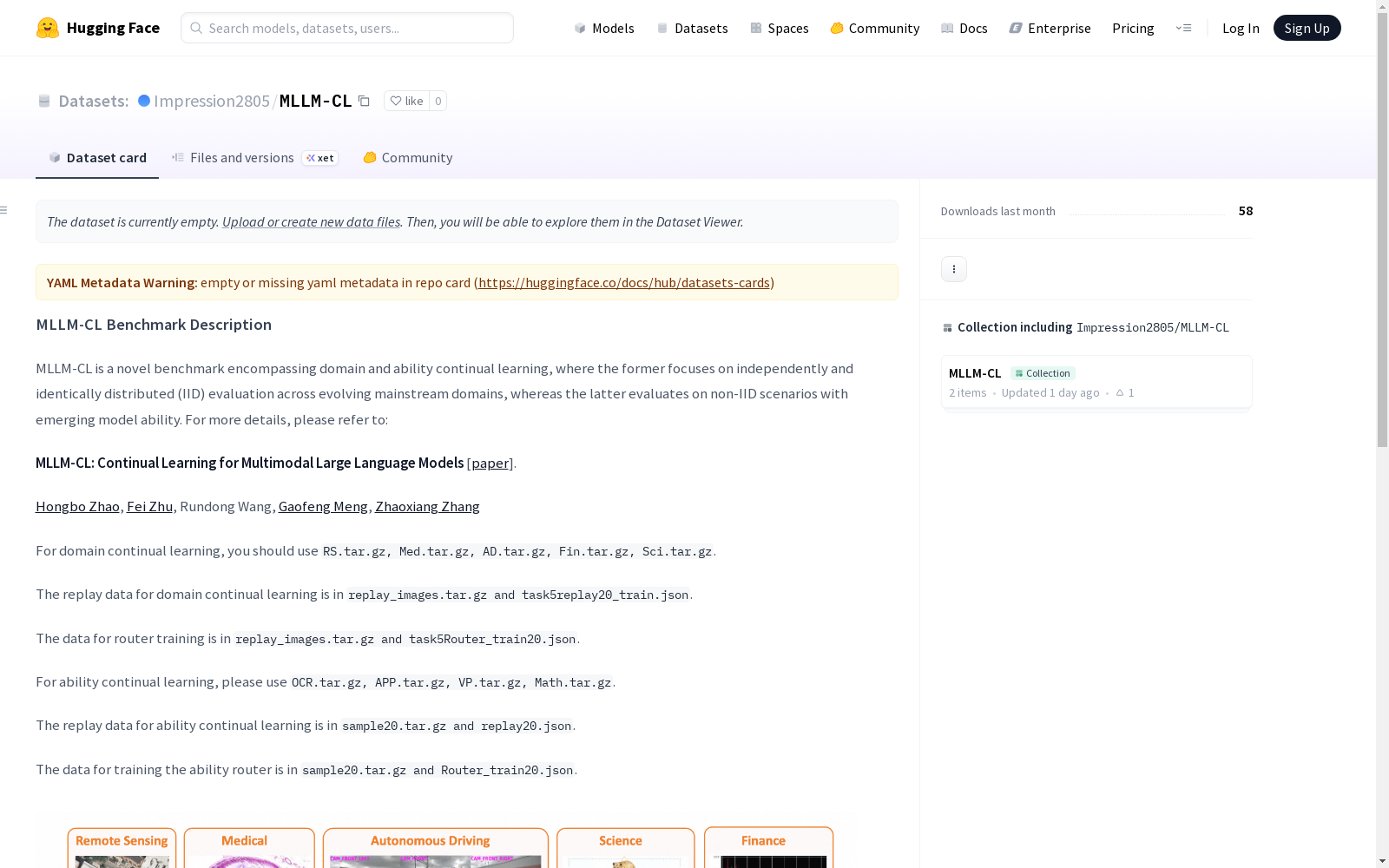
MLLM-CL是一个针对多模态大型语言模型的连续学习基准,包括领域连续学习和能力连续学习两个部分。领域连续学习涉及在演变的主流领域中独立同分布(IID)的评估,而能力连续学习关注在非独立同分布(non-IID)场景下新兴模型能力的评估。数据集包含了不同任务所需的数据文件,所有数据用于支持MLLM的SFT阶段,且数据格式遵循LLaVA SFT格式。
MLLM-CL is a continual learning benchmark for multimodal large language models, comprising two components: domain continual learning and capability continual learning. Domain continual learning covers independent and identically distributed (IID) evaluations across evolving mainstream domains, whereas capability continual learning focuses on evaluating emergent model capabilities in non-independent and identically distributed (non-IID) scenarios. The benchmark contains data files required for diverse tasks, all of which are designed to support the supervised fine-tuning (SFT) phase of multimodal large language models, with the data format adhering to the LLaVA SFT format.
创建时间:
2025-05-27
原始信息汇总
MLLM-CL 数据集概述
数据集简介
MLLM-CL是一个新颖的基准测试,涵盖领域和能力持续学习:
- 领域持续学习:关注主流领域演变中的独立同分布(IID)评估
- 能力持续学习:评估具有新兴模型能力的非IID场景
数据组成
领域持续学习数据
- 主数据集文件:
RS.tar.gzMed.tar.gzAD.tar.gzFin.tar.gzSci.tar.gz
- 回放数据:
replay_images.tar.gztask5replay20_train.json
- 路由器训练数据:
replay_images.tar.gztask5Router_train20.json
能力持续学习数据
- 主数据集文件:
OCR.tar.gzAPP.tar.gzVP.tar.gzMath.tar.gz
- 回放数据:
sample20.tar.gzreplay20.json
- 路由器训练数据:
sample20.tar.gzRouter_train20.json
数据格式
- 所有数据用于MLLM的SFT阶段
- JSON文件采用LLaVA SFT格式
相关论文
MLLM-CL: Continual Learning for Multimodal Large Language Models
作者信息
- Hongbo Zhao
- Fei Zhu
- Rundong Wang
- Gaofeng Meng
- Zhaoxiang Zhang
联系方式
可通过Github提交issue联系
搜集汇总
数据集介绍
构建方式
在跨模态大模型持续学习研究领域,MLLM-CL基准通过精心设计的双轨评估体系构建而成。该数据集采用模块化架构,将领域持续学习与能力持续学习分离处理:领域评估部分包含RS、Med、AD、Fin、Sci五个独立压缩包,模拟主流领域的IID演化过程;能力评估部分则整合OCR、APP、VP、Math四大模块,构建非IID场景下的新兴能力测试环境。研究人员特别设计了重放数据机制,分别通过replay_images.tar.gz与sample20.tar.gz文件包实现知识保留,并配套json格式的任务描述文件确保评估流程的完整性。
特点
作为多模态大模型持续学习的专业评估基准,MLLM-CL最显著的特征在于其双轨并行评估体系。领域持续学习轨迹覆盖遥感、医疗、广告、金融、科研等五大现实场景,每个领域均保持数据分布的独立性;能力持续学习轨迹则聚焦光学字符识别、应用程序理解、视觉推理和数学计算四大核心能力,通过非对称数据分布模拟真实世界的渐进式学习需求。数据集严格遵循LLaVA指令微调格式,所有任务描述文件均采用标准化json结构,既确保与主流多模态框架的兼容性,又维持了评估过程的严谨度。
使用方法
使用该基准需根据研究目标选择相应模块:领域评估需加载RS/Med/AD/Fin/Sci压缩包及配套重放数据,能力评估则调用OCR/APP/VP/Math组件配合样本包。路由训练需额外加载task5Router_train20.json或Router_train20.json配置文件。所有数据文件需解压后按照LLaVA指令微调框架的输入规范进行处理,json文件中的结构化字段包含完整的任务描述和评估指标。建议研究者通过官方提供的示意图理解各模块关联关系,并参照原始论文所述协议进行实验设计以确保结果可比性。
背景与挑战
背景概述
MLLM-CL数据集由Hongbo Zhao、Fei Zhu等学者联合推出,专注于多模态大语言模型(MLLM)的持续学习问题。该数据集旨在解决领域持续学习与能力持续学习两大核心问题,前者关注主流领域在独立同分布条件下的演化评估,后者则针对非独立同分布场景下模型能力的动态扩展。其研究背景源于人工智能领域对模型长期适应性和泛化能力的迫切需求,为多模态大语言模型的持续优化提供了重要基准。
当前挑战
MLLM-CL数据集面临的主要挑战体现在两方面:领域持续学习需克服数据分布动态变化导致的模型遗忘问题,能力持续学习则需解决新兴能力与既有知识体系的非平稳性冲突。数据构建过程中,研究者需精确设计领域与能力的演化路径,确保评估场景既反映现实复杂性,又保持实验可复现性。多模态数据的对齐与标注一致性亦对数据质量提出了较高要求。
常用场景
经典使用场景
在人工智能领域,多模态大语言模型的持续学习能力是当前研究热点。MLLM-CL数据集通过构建领域和能力两个维度的持续学习基准,为研究者提供了系统评估模型在动态环境中适应性的标准框架。其经典使用场景体现在对模型在主流领域演变过程中的独立同分布评估,以及在新兴能力出现时的非独立同分布场景测试,这种双轨设计极大丰富了持续学习研究的评估维度。
衍生相关工作
基于MLLM-CL基准已催生系列创新研究,包括动态架构扩展算法、基于神经突触可塑性的参数优化方法等。其中最具代表性的是结合任务路由器的混合专家系统,通过该数据集验证了其在多模态持续学习中的优越性。这些衍生工作共同推动了持续学习从理论到实践的转化,形成了一套完整的评估-改进-验证研究闭环。
数据集最近研究
最新研究方向
在人工智能领域,多模态大语言模型(MLLM)的持续学习能力正成为研究热点。MLLM-CL基准通过领域持续学习和能力持续学习两个维度,为模型在动态环境中的适应性提供了系统评估框架。领域持续学习关注主流领域的独立同分布评估,而能力持续学习则针对非独立同分布场景下的新兴能力进行测试。这一基准的提出,为解决大语言模型在复杂多模态数据流中的灾难性遗忘问题提供了新的研究路径。当前,研究者们正基于该数据集探索更高效的持续学习策略,包括动态路由机制和记忆回放技术,以提升模型在开放环境中的长期适应性和泛化能力。
以上内容由遇见数据集搜集并总结生成


