SKIML-ICL/hoh_full
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/SKIML-ICL/hoh_full
下载链接
链接失效反馈官方服务:
资源简介:
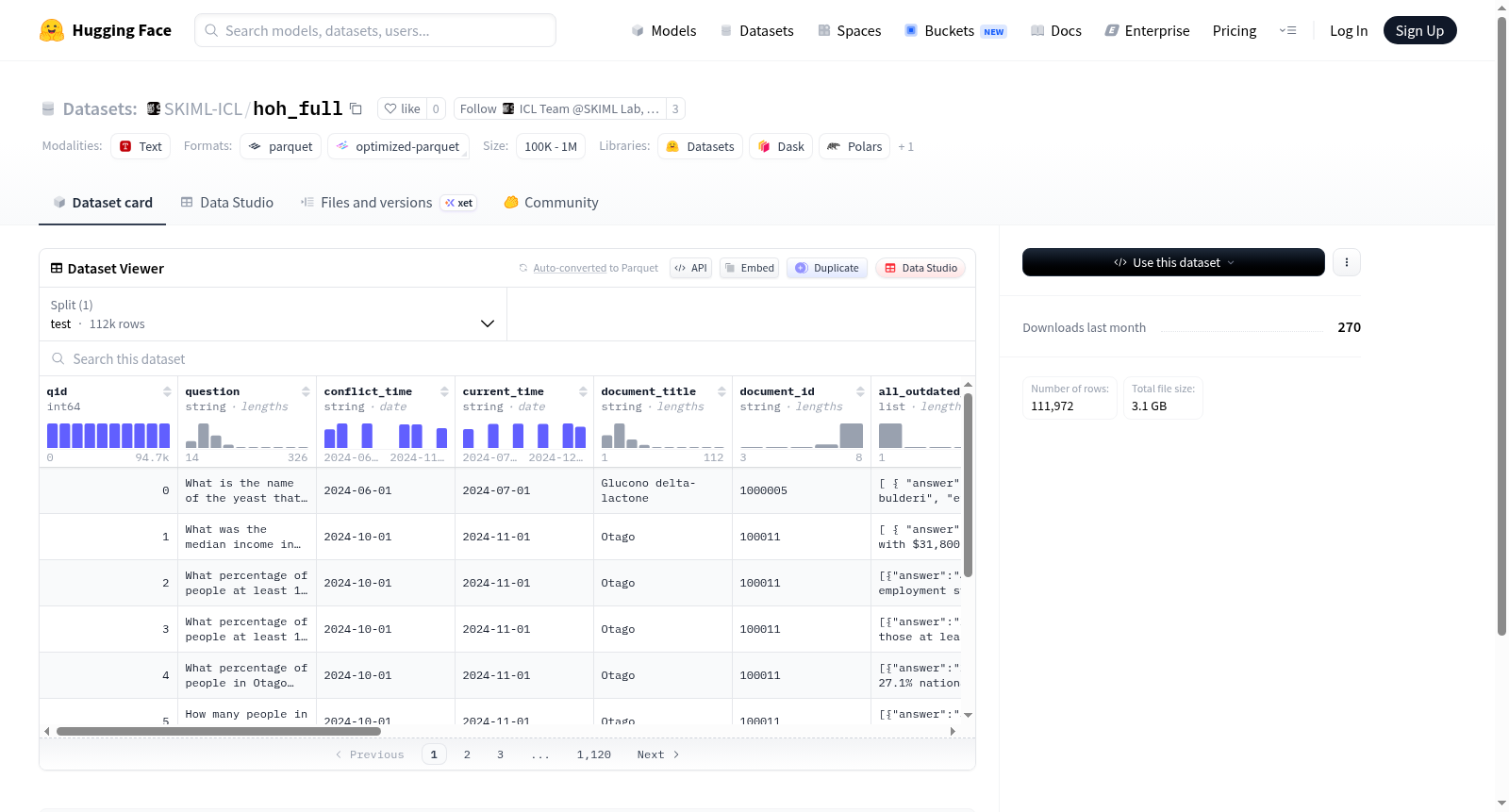
该数据集包含问题和相关上下文信息,用于评估信息过时性和冲突答案的检测。数据集包含多个特征字段,如问题ID、问题文本、冲突时间、当前时间、文档标题、文档ID等。此外,还包含列表类型的字段,如所有过时信息、上下文信息等。数据集还包含可回答性、可回答前缀、冲突答案、答案等字段。数据集仅包含测试集,包含111,972个示例。
This dataset contains questions and related contextual information for evaluating information obsolescence and conflict answer detection. The dataset includes multiple feature fields such as question ID, question text, conflict time, current time, document title, document ID, etc. Additionally, it includes list-type fields such as all outdated information, contextual information, etc. The dataset also includes fields like answerability, answerable prefix, conflict answers, answers, etc. The dataset only contains a test set with 111,972 examples.
提供机构:
SKIML-ICL
搜集汇总
数据集介绍
构建方式
hoh_full数据集面向开放域问答中的时间敏感性问题构建,聚焦于因时间推移导致的答案过时现象。该数据集通过系统性地收集来自维基百科等知识库的问题与文档对,针对每个问题标注了多个时间戳下的冲突答案。构建过程首先提取问题对应的历史文档快照,利用差异检测引擎定位过时信息,随后结合人工校验与自动化的自然语言推理机制,确保每个冲突答案均具有可靠的证据支撑。最终形成包含逾十一万条测试样本的大规模基准。
使用方法
使用时可从HuggingFace仓库加载默认配置,该配置以test分片形式提供约11.2万条实例。研究者可直接通过字段名访问问题文本、冲突答案集合及检索上下文,以设计时效性问答模型。标准评估流程为:依据'answerable'字段判断问题是否可回答,在可回答情况下,利用'answers'作为标签,并可将'ctxs'中的排序文档作为检索增强输入。数据集兼容HuggingFace的load_dataset接口,便于集成到现有训练与评估管线中。
背景与挑战
背景概述
在自然语言处理与信息检索领域,时序动态变化对知识准确性的影响日益显著,传统静态数据集难以捕捉信息随时间演化的复杂性。hoh_full数据集由相关研究机构于近期创建,聚焦于“过时信息”与“矛盾信息”的检测与处理,通过引入时间戳、冲突证据及问答对,旨在推动模型对知识时效性与矛盾点的理解能力。该数据集包含超过11万条样本,每条样本均标注了当前信息与历史过时信息的对比,为时序推理与知识更新研究提供了标准化的评估基准,在开放域问答、事实核查及持续学习等方向具有重要影响力。
当前挑战
该数据集面临的核心挑战包括:其一,领域问题层面,需解决信息过时导致的错误回答,例如模型如何区分当前有效答案与历史矛盾信息,抵御时效性偏差;其二,构建过程中,需从海量多源文档中精准标注冲突证据与时间关联,克服人工标注的主观性与成本高昂问题;同时,数据集中“可回答性”与“冲突通过性”的动态判定机制也增加了模型在不确定语境下推理的复杂度。
常用场景
经典使用场景
在自然语言处理与信息检索领域,时间敏感性问题(Temporal Question Answering)始终是知识动态演化研究的核心挑战。hoh_full数据集专为应对这一难题而设计,其经典使用场景聚焦于评估模型在跨时间信息源中甄别答案演变的能力。具体而言,研究者借助该数据集构造的“历史-当前”双时间窗口结构,可系统性地测试问答系统在面对语境中隐含的陈旧信息与实时更新的冲突时,能否精准定位正确解答。该数据集以大规模分布式证据片段为背景,要求模型从上千条时序异构文本中抽取出与查询时刻相符的答案,从而成为衡量模型时序鲁棒性的标杆。
解决学术问题
hoh_full数据集的问世直接回应了学术界对“信息时效性建模”的长期呼吁。传统问答数据集多假设知识静态不变,忽略了现实世界中事实随时间的自然更迭,导致模型泛化至真实时序场景时性能骤降。该数据集通过系统化标注答案的时间戳冲突与验证标签,使得研究者能够深入探究三个关键学术问题:如何从多源证据中识别过时信息、如何利用时间逻辑推理调和前后矛盾的陈述,以及如何构建与时间对齐的检索增强生成框架。其影响在于为时间推理任务提供了可复现的基准,推动了基于时间感知的神经符号模型与对比学习策略的演进。
实际应用
在工业级智能问答与知识管理系统中,hoh_full数据集所倡导的时序感知能力具有显著的实际应用价值。例如,在财经舆情监控平台中,实时新闻与历史研报充斥截然不同的市场预测,借助该数据集的冲突检测与时效重排序逻辑,系统可动态筛选出最新股价分析而非陈旧主张;类似的,在医学文献辅助决策工具里,研究人员需要区分已撤稿的临床指南与最新循证证据,hoh_full提供的答案演化标注模式直接赋能了这类科学事实的自动溯源。此外,该数据集还为智能助手的时间敏感型对话提供了训练支撑,确保诸如“当前CEO是谁”之类的查询能跨域融合知识图谱更新记录。
数据集最近研究
最新研究方向
在时序知识推理与信息过时性检测的前沿探索中,hoh_full数据集为动态问答系统研究提供了关键基准。该数据集聚焦于文档级信息冲突与时效性矛盾,通过标注问题对应的过时答案、冲突证据及当前上下文,推动了事实性问答在时效维度上的建模突破。当前热点事件如虚假信息传播与实时知识更新需求,使得该数据集成为评估模型应对信息僵化与演化能力的重要工具。其通过多粒度答案版本与上下文证据的设计,为构建具备时序意识与矛盾消解能力的智能问答系统奠定了数据基础,显著提升了信息检索与知识验证的鲁棒性。
以上内容由遇见数据集搜集并总结生成


