daven3/geosignal
收藏Hugging Face2023-08-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/daven3/geosignal
下载链接
链接失效反馈资源简介:
---
license: apache-2.0
task_categories:
- question-answering
---
## Instruction Tuning: GeoSignal
Scientific domain adaptation has two main steps during instruction tuning.
- Instruction tuning with general instruction-tuning data. Here we use Alpaca-GPT4.
- Instruction tuning with restructured domain knowledge, which we call expertise instruction tuning. For K2, we use knowledge-intensive instruction data, GeoSignal.
***The following is the illustration of the training domain-specific language model recipe:***

- **Adapter Model on [Huggingface](https://huggingface.co/): [daven3/k2_it_adapter](https://huggingface.co/daven3/k2_it_adapter)**
For the design of the GeoSignal, we collect knowledge from various data sources, like:

GeoSignal is designed for knowledge-intensive instruction tuning and used for aligning with experts.
The full-version will be upload soon, or email [daven](mailto:davendw@sjtu.edu.cn) for potential research cooperation.
提供机构:
daven3
原始信息汇总
数据集概述
数据集名称
GeoSignal
许可证
Apache-2.0
任务类别
- 问答
数据集设计
GeoSignal 是为知识密集型指令调优设计的,用于与专家对齐。数据集的知识来源包括多种数据源。
使用场景
- 指令调优的一般阶段使用 Alpaca-GPT4 数据。
- 知识密集型指令调优阶段使用 GeoSignal 数据。
模型适配
- 适配器模型可在 Huggingface 上获取,地址为 daven3/k2_it_adapter。
联系方式
- 全版本即将上传,或通过电子邮件 daven 联系以探讨潜在的研究合作。
搜集汇总
数据集介绍
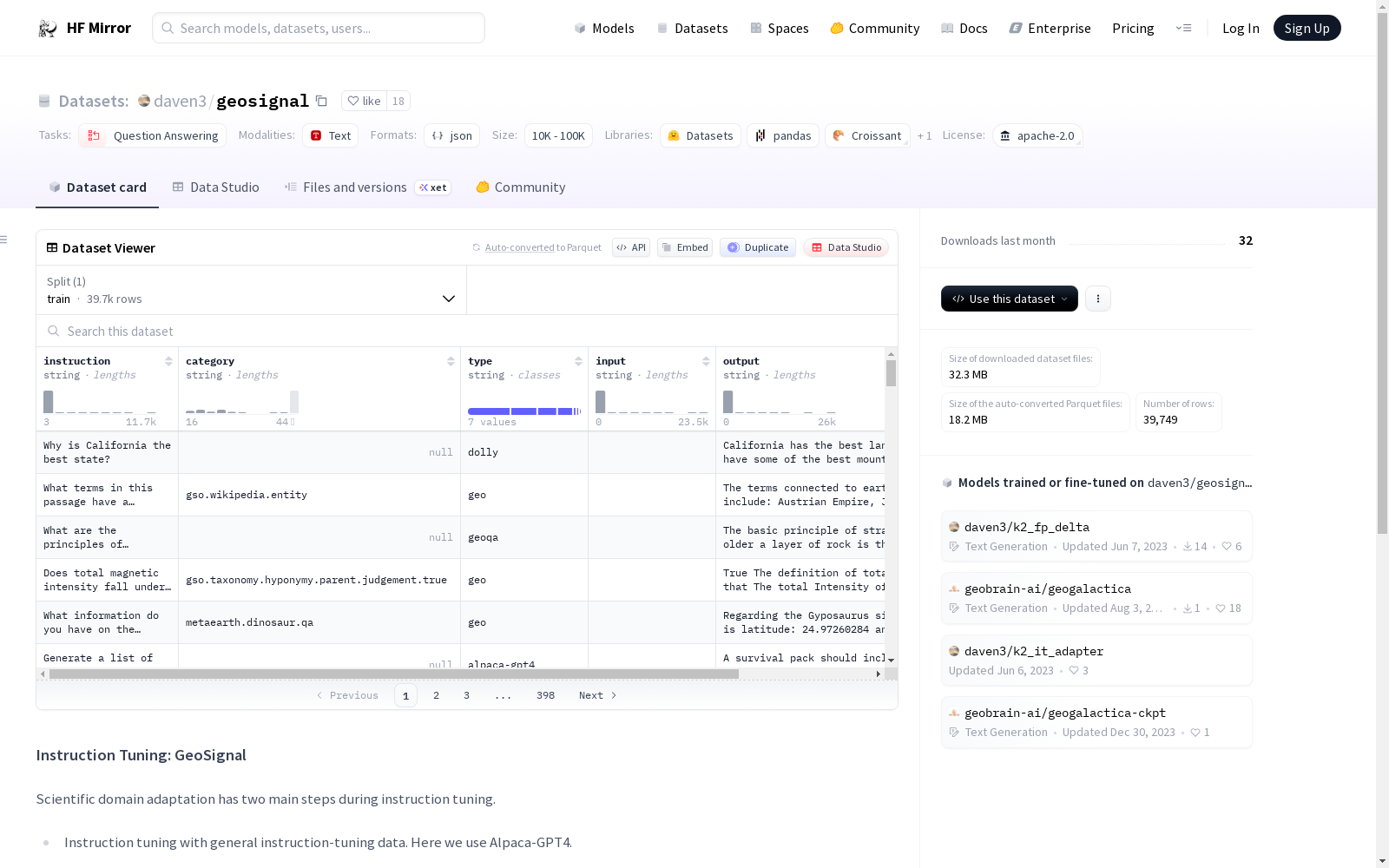
构建方式
在科学领域适应性的研究背景下,GeoSignal数据集的构建采用了知识密集型指令调优的策略。该数据集通过整合多元化的知识源,如学术文献与专业数据库,精心重构了领域知识,形成了专家对齐的指令数据。其构建过程分为两个阶段:首先利用通用指令调优数据(如Alpaca-GPT4)进行初步训练,随后引入经过结构化处理的领域知识,即专业知识指令调优,以增强模型在特定科学领域的适应能力。
特点
GeoSignal数据集的核心特点在于其专注于地理科学领域的知识密集性,旨在通过指令调优促进语言模型与专家知识的对齐。该数据集以高质量、结构化的知识为基础,涵盖了多样化的数据来源,确保了内容的深度与广度。其设计强调领域适应性,能够有效支持科学任务中的复杂问答需求,为模型提供了从通用到专业的知识过渡桥梁,从而提升了在专业场景下的性能表现。
使用方法
在应用GeoSignal数据集时,研究人员可将其用于专业知识指令调优阶段,以增强语言模型在地理科学领域的适应性。使用方法包括将数据集与通用指令数据结合,通过多阶段训练流程,先进行通用指令调优,再引入GeoSignal进行领域对齐。该数据集适用于问答任务,可帮助模型学习专家级的知识响应模式,促进科学领域的高效知识迁移与模型优化。
背景与挑战
背景概述
GeoSignal数据集由上海交通大学的研究团队于近期构建,旨在推动科学领域自适应中专家知识对齐的研究。该数据集聚焦于地理科学领域,通过整合多源知识数据,为指令微调提供知识密集型训练资源。其核心研究问题在于如何将结构化领域知识有效融入语言模型,以提升模型在专业任务中的准确性和可靠性,对地理信息处理及领域自适应自然语言处理具有重要影响力。
当前挑战
GeoSignal数据集致力于解决地理科学领域知识问答中的复杂语义理解与精确信息检索挑战,要求模型在专业术语和空间关系推理方面具备高精度。在构建过程中,面临多源异构数据的整合与标准化困难,包括数据格式不统一、知识一致性校验以及专家知识的结构化转换等问题,这些因素增加了数据集的质量控制与泛化能力保障的难度。
常用场景
经典使用场景
在自然语言处理领域,GeoSignal数据集专为知识密集型指令调优而设计,其经典使用场景体现在科学领域适应过程中。通过将地理科学领域的专业知识转化为结构化指令数据,该数据集能够训练语言模型深入理解并响应复杂的地理知识查询。这种指令调优方法使模型能够处理诸如地理空间分析、环境科学推理等专业任务,为领域特定语言模型的开发提供了关键支持。
实际应用
在实际应用中,GeoSignal数据集能够赋能地理信息系统、环境监测和城市规划等领域的智能问答系统。通过基于该数据集的指令调优,语言模型可以协助专业人员快速获取地理空间数据解读、气候模式分析等专业知识,提升决策效率。例如,在灾害响应或资源管理场景中,模型能够提供准确的地理知识支持,增强实际应用的智能化水平。
衍生相关工作
围绕GeoSignal数据集,已衍生出如K2适配器模型等相关经典工作。这些工作探索了通用指令调优与专业知识指令调优的结合方法,形成了领域特定语言模型的训练框架。后续研究进一步扩展了该数据集的适用领域,推动了知识密集型指令调优技术在更多科学领域的应用,为跨学科人工智能研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


