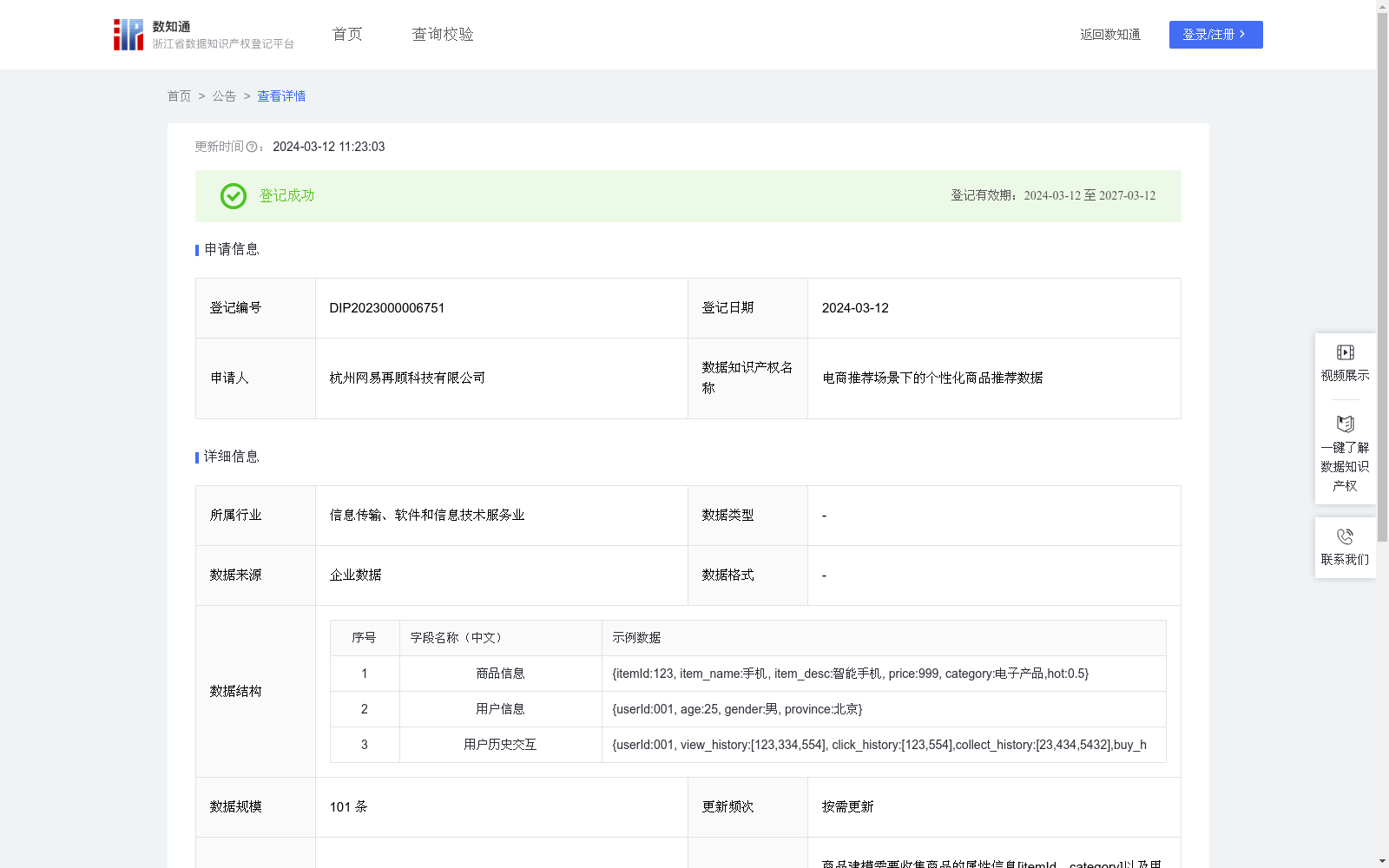
电商推荐场景下的个性化商品推荐数据
收藏浙江省数据知识产权登记平台2024-03-12 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/30825
下载链接
链接失效反馈官方服务:
资源简介:
该数据的适用条件包括平台拥有大规模的商品信息和用户数据,并且能够追踪和记录用户的详尽历史交互信息。这类数据的应用能够解决电商平台的重要问题,包括但不限于提高个性化用户体验、增加用户的平台黏性、促进销售额的增长以及提高用户转化率。通过个性化推荐系统,用户可以更加高效地发现符合其喜好和需求的商品,从而提升购买满意度和用户忠诚度。商品建模需要收集商品的属性信息[itemId、category]以及用户的点击行为序列[click_history]以及购买行为序列[buy_history],建模过程先基于用户的行为序列构建商品之间的关联图(相邻的两个交互商品之间构建关联),然后在图上游走获取商品关联路径,在路径上基于窗口滑动获取关联的训练数据集合[center、contexts、gloabl],然后基于右图的 loss 函数进行模型训练,训练后获取得到商品id以及属性(category)的Embedding向量(模型中id对应的可学习参数即是Embedding 向量),将商品id向量和商品属性向量拼接输出最终的商品向量。
用户向量基于用户的view_history、click_history、collect_history、buy_history 各种行为序列加上用户行为的时效信息在商品向量的基础上聚合得到。UserVector = Agg(ItemVectorCollection , *_history)
利用商品向量表示,计算用户兴趣和商品的相似度,基于LSH模型进行快速的向量召回,以获取与用户兴趣相匹配的商品
The applicable conditions of this dataset require that the platform possesses large-scale product information and user data, and is capable of tracking and recording users' detailed historical interaction records. The application of this dataset can address core issues faced by e-commerce platforms, including but not limited to enhancing personalized user experience, improving user platform stickiness, boosting sales growth, and increasing user conversion rate. Through personalized recommendation systems, users can more efficiently discover products that align with their preferences and needs, thereby elevating purchase satisfaction and user loyalty.
Product modeling requires collecting product attribute information [itemId, category], as well as users' click behavior sequences [click_history] and purchase behavior sequences [buy_history]. The modeling workflow first constructs an association graph between products based on users' behavior sequences, where associations are established between two adjacent interacting products. Next, random walks are performed on the graph to obtain product association paths, and sliding windows are applied on these paths to generate the associated training dataset [center, contexts, global]. The model is then trained using the loss function shown in the right-hand figure. After training, the Embedding vectors of product IDs and their attributes (category) are obtained, where the learnable parameters corresponding to the IDs in the model are exactly the Embedding vectors. The final product vector is output by concatenating the product ID vector and the product attribute vector.
User vectors are derived by aggregating product vectors, leveraging various user behavior sequences including view_history, click_history, collect_history, and buy_history, along with the temporal information of user behaviors. The formula is: UserVector = Agg(ItemVectorCollection, *_history)
By utilizing the product vector representations, the similarity between user interests and products is calculated, and fast vector recall is conducted via the LSH model to retrieve products that match user interests.
提供机构:
杭州网易再顾科技有限公司
创建时间:
2023-12-04
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


