MotionPrefer
收藏github2024-12-02 更新2024-12-06 收录
下载链接:
https://github.com/VincentHancoder/AToM
下载链接
链接失效反馈官方服务:
资源简介:
MotionPrefer数据集用于配对三种类型的事件级别文本提示和生成的动作,涵盖动作的完整性、时间关系和频率。该数据集旨在提高文本到动作生成模型的事件级别对齐质量。
The MotionPrefer Dataset is designed to pair three types of event-level textual prompts with generated motions, covering motion completeness, temporal relationships and frequency. This dataset aims to improve the event-level alignment quality of text-to-motion generation models.
创建时间:
2024-11-27
原始信息汇总
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
数据集概述
- 数据集名称: MotionPrefer
- 数据集内容: 包含80K个偏好对,配对三种类型的事件级文本提示与生成的动作,涵盖动作的完整性、时间关系和频率。
- 数据集用途: 用于增强文本到动作生成模型的事件级对齐质量。
数据集构建
- 文本提示类型: 事件级文本提示
- 动作生成: 生成的动作
- 数据集特点: 覆盖动作的完整性、时间关系和频率
数据集发布计划
- [ ] 发布细粒度动作偏好数据集 MotionPrefer,包含80K个偏好对。
- [ ] 发布提示构建和不同子任务对齐分数标注的说明。
- [ ] 发布基于不同类型偏好数据的微调模型检查点。
- [ ] 发布更多定性实验结果。
引用
@misc{han2024atomaligningtexttomotionmodel, title={AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward}, author={Haonan Han and Xiangzuo Wu and Huan Liao and Zunnan Xu and Zhongyuan Hu and Ronghui Li and Yachao Zhang and Xiu Li}, year={2024}, eprint={2411.18654}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2411.18654}, }
搜集汇总
数据集介绍
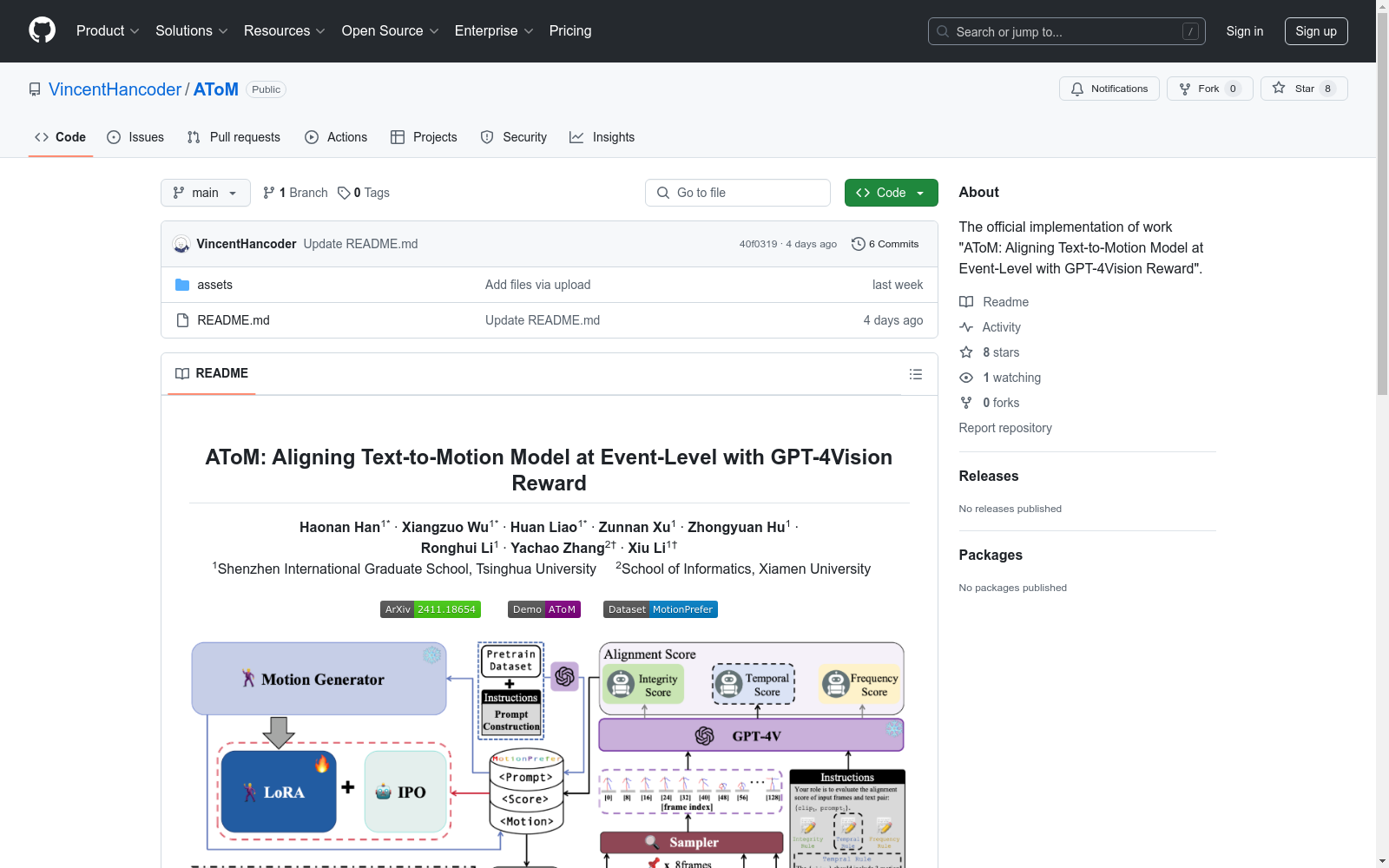
构建方式
在文本到动作生成模型的研究领域,为了解决文本描述与生成的动作之间的复杂对齐问题,我们构建了MotionPrefer数据集。该数据集通过将三种类型的事件级文本提示与生成的动作进行配对,涵盖了动作的完整性、时间关系和频率。具体而言,MotionPrefer数据集的构建过程包括收集和标注大量的文本提示,随后使用GPT-4Vision进行详细的动作注释,确保每个动作与文本提示之间的精确对齐。
特点
MotionPrefer数据集的显著特点在于其精细化的标注和对齐机制。通过GPT-4Vision的辅助,数据集不仅提供了高质量的动作注释,还确保了文本提示与生成动作之间的事件级对齐。此外,数据集的多样性体现在其覆盖了多种动作类型和复杂度,为研究者提供了丰富的资源以探索和优化文本到动作生成模型。
使用方法
使用MotionPrefer数据集时,研究者可以利用其精细化的标注和对齐信息,进行文本到动作生成模型的训练和评估。具体步骤包括加载数据集,根据任务需求选择合适的文本提示和对应的动作数据,然后利用这些数据进行模型训练或验证。此外,数据集还提供了详细的注释指南和评分规则,帮助研究者更好地理解和利用数据集中的信息。
背景与挑战
背景概述
近年来,文本到动作(text-to-motion)模型在生成逼真人体动作方面展现出新的可能性,提高了效率和灵活性。然而,将动作生成与事件级文本描述对齐面临独特挑战,因文本提示与期望动作结果之间存在复杂关系。为解决此问题,清华大学深圳国际研究生院与厦门大学信息学院的研究团队联合开发了AToM框架,通过利用GPT-4Vision的奖励机制,增强生成动作与文本提示的对齐。该框架包括构建MotionPrefer数据集,该数据集将三种类型的事件级文本提示与生成的动作配对,涵盖动作的完整性、时间关系和频率。
当前挑战
构建MotionPrefer数据集的主要挑战在于如何准确地将事件级文本提示与生成的动作对齐。这需要解决文本与动作之间复杂关系的映射问题,确保生成的动作能够准确反映文本描述的意图。此外,数据集的构建过程中还需设计详细的动作注释范式,利用GPT-4Vision进行视觉数据格式化、任务特定指令和评分规则的制定,以确保注释的准确性和一致性。最后,通过强化学习对现有文本到动作模型进行微调,以提高事件级对齐质量,这也是一个技术上的挑战。
常用场景
经典使用场景
在文本到动作生成领域,MotionPrefer数据集的经典应用场景主要体现在其用于训练和评估文本与动作之间的对齐模型。该数据集通过将事件级别的文本描述与生成的动作序列配对,涵盖了动作的完整性、时间关系和频率等多个维度,从而为模型提供了丰富的训练数据。通过使用MotionPrefer数据集,研究者能够更精确地调整和优化文本到动作生成模型,使其在生成符合文本描述的动作序列时表现出更高的准确性和自然度。
解决学术问题
MotionPrefer数据集解决了文本到动作生成领域中的一个关键学术问题,即如何有效地将文本描述与生成的动作序列进行对齐。传统的文本到动作模型往往难以处理复杂的事件级别描述,导致生成的动作与文本描述之间存在较大的偏差。MotionPrefer通过提供精细化的文本与动作对齐数据,帮助研究者开发出更精确的对齐算法,从而显著提升了文本到动作生成模型的性能和实用性。
衍生相关工作
基于MotionPrefer数据集,研究者们开发了一系列相关的经典工作。例如,AToM框架通过利用GPT-4Vision的奖励机制,进一步提升了文本到动作生成模型的对齐质量。此外,MotionGPT和InstructMotion等项目也从该数据集中汲取灵感,开发了更为先进的文本到动作生成技术。这些工作不仅推动了文本到动作生成领域的发展,也为其他相关领域的研究提供了宝贵的参考和借鉴。
以上内容由遇见数据集搜集并总结生成


