CODEELO
收藏资源简介:
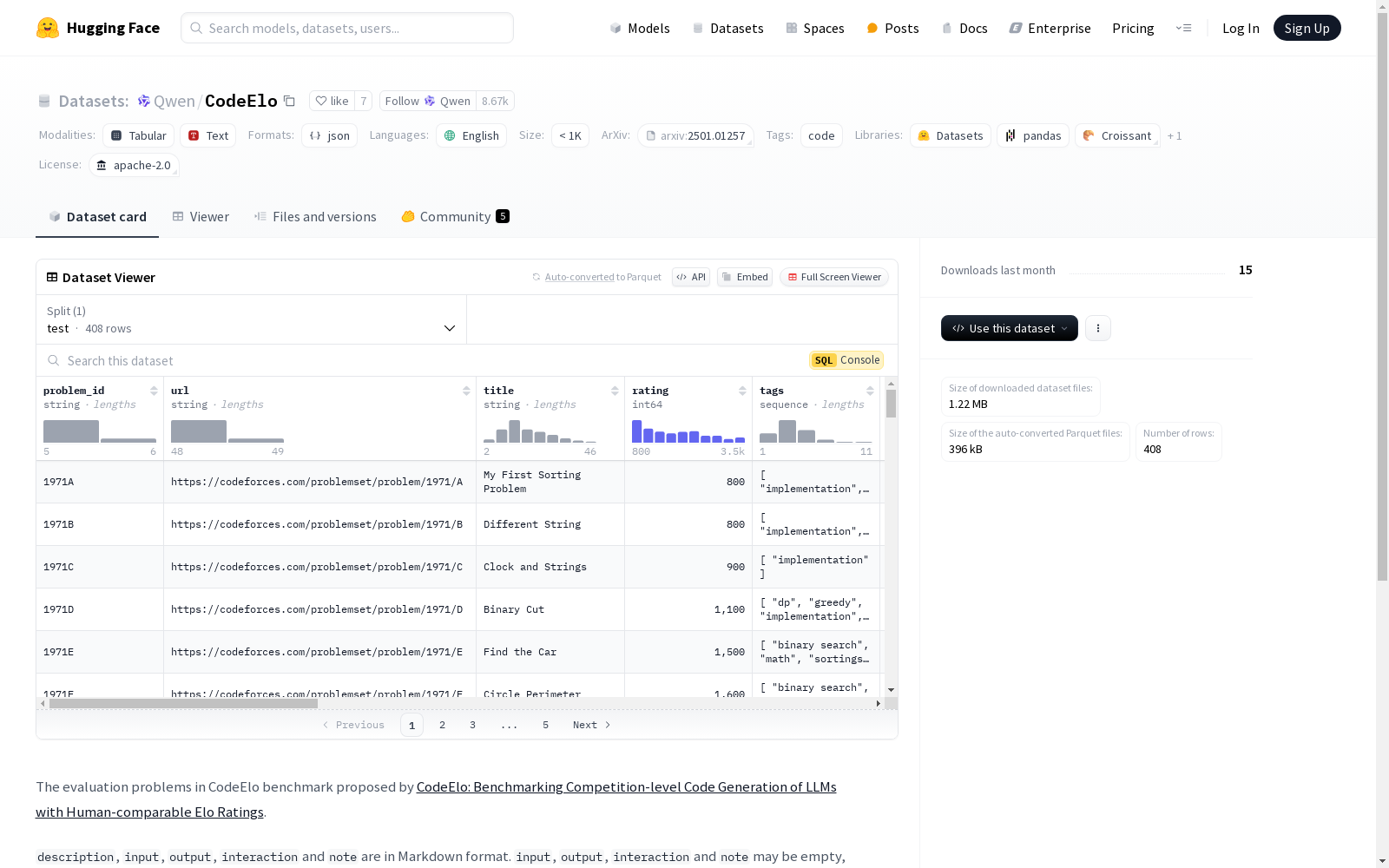
CODEELO是由阿里巴巴集团开发的一个标准化竞赛级代码生成基准数据集,基于CodeForces平台的近期比赛问题构建。数据集包含详细的比赛分区、问题难度评级和算法标签信息,旨在评估大型语言模型在复杂代码生成任务中的表现。通过自动提交代码到CodeForces平台进行评测,CODEELO实现了零误判率,并支持特殊评测代码,确保了评测环境的完全一致性。数据集的应用领域主要集中在评估和改进大型语言模型的代码推理能力,特别是在竞赛级编程任务中的表现。
CODEELO is a standardized competitive-level code generation benchmark dataset developed by Alibaba Group, constructed using recent contest problems from the CodeForces platform. This dataset provides detailed contest divisions, problem difficulty ratings, and algorithmic tag information, aiming to evaluate the performance of large language models (LLMs) on complex code generation tasks. By automatically submitting generated code to the CodeForces platform for official evaluation, CODEELO achieves a zero misjudgment rate and supports special evaluation code, ensuring full consistency of the evaluation environment. The primary application scope of this dataset focuses on evaluating and improving the code reasoning capabilities of large language models, especially their performance on competitive-level programming tasks.