---
language:
- zh
task_categories:
- text-generation
size_categories:
- n>1T
configs:
- config_name: default
data_files:
- split: train
path: "*.parquet"
---
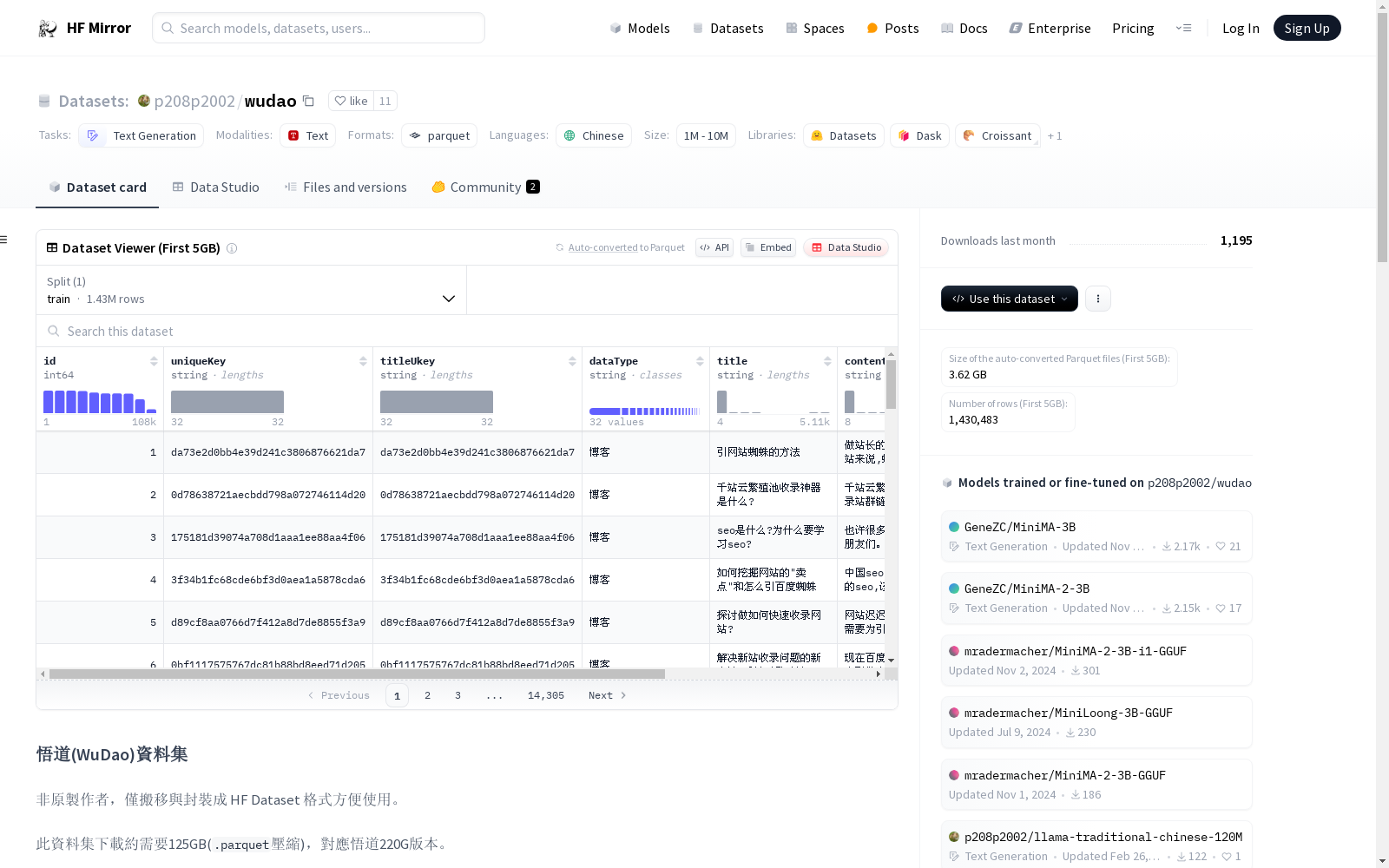
# 悟道(WuDao)資料集
非原製作者,僅搬移與封裝成 HF Dataset 格式方便使用。
此資料集下載約需要125GB(`.parquet`壓縮),對應悟道220G版本。
如果使用此資料集,請引用原作者:
```
@misc{ c6a3fe684227415a9db8e21bac4a15ab,
author = {Zhao Xue and Hanyu Zhao and Sha Yuan and Yequan Wang},
title = {{WuDaoCorpora Text}},
year = 2022,
month = dec,
publisher = {Science Data Bank},
version = {V1},
doi = {10.57760/sciencedb.o00126.00004},
url = https://doi.org/10.57760/sciencedb.o00126.00004
}
```
## 出處連結
[Science Data Bank](https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab)
## 使用
```python
from datasets import load_dataset
load_dataset("p208p2002/wudao",streaming=True,split="train")
```
## 資料類別統計
```json
{
"_total": 59100001,
"豆瓣话题": 209027,
"科技": 1278068,
"经济": 1096215,
"汽车": 1368193,
"娱乐": 1581947,
"农业": 1129758,
"军事": 420949,
"社会": 446228,
"游戏": 754703,
"教育": 1133453,
"体育": 660858,
"旅行": 821573,
"国际": 630386,
"房产": 387786,
"文化": 710648,
"法律": 36585,
"股票": 1205,
"博客": 15467790,
"日报": 16971,
"评论": 13867,
"孕育常识": 48291,
"健康": 15291,
"财经": 54656,
"医学问答": 314771,
"资讯": 1066180,
"科普文章": 60581,
"百科": 27273280,
"酒业": 287,
"经验": 609195,
"新闻": 846810,
"小红书攻略": 185379,
"生活": 23,
"网页文本": 115830,
"观点": 1268,
"海外": 4,
"户外": 5,
"美容": 7,
"理论": 247,
"天气": 540,
"文旅": 2999,
"信托": 62,
"保险": 70,
"水利资讯": 17,
"时尚": 1123,
"亲子": 39,
"百家号文章": 335591,
"黄金": 216,
"党建": 1,
"期货": 330,
"快讯": 41,
"国内": 15,
"国学": 614,
"公益": 15,
"能源": 7,
"创新": 6
}
```
---
language:
- zh
task_categories:
- 文本生成
size_categories:
- 样本数大于1万亿
configs:
- config_name: default
data_files:
- split: train
path: "*.parquet"
---
# 悟道(WuDao)数据集
本数据集并非原作者制作,仅为迁移并封装为Hugging Face数据集(Hugging Face Dataset,简称HF Dataset)格式以方便使用。
该数据集下载体积约为125GB(.parquet压缩格式),对应悟道220GB版本。
若使用本数据集,请引用原作者的文献:
@misc{ c6a3fe684227415a9db8e21bac4a15ab,
author = {Zhao Xue and Hanyu Zhao and Sha Yuan and Yequan Wang},
title = {{WuDaoCorpora Text}},
year = 2022,
month = dec,
publisher = {Science Data Bank},
version = {V1},
doi = {10.57760/sciencedb.o00126.00004},
url = https://doi.org/10.57760/sciencedb.o00126.00004
}
## 来源链接
[Science Data Bank](https://www.scidb.cn/en/detail?dataSetId=c6a3fe684227415a9db8e21bac4a15ab)
## 使用方法
python
from datasets import load_dataset
load_dataset("p208p2002/wudao",streaming=True,split="train")
## 数据类别统计
json
{
"_total": 59100001,
"豆瓣话题": 209027,
"科技": 1278068,
"经济": 1096215,
"汽车": 1368193,
"娱乐": 1581947,
"农业": 1129758,
"军事": 420949,
"社会": 446228,
"游戏": 754703,
"教育": 1133453,
"体育": 660858,
"旅行": 821573,
"国际": 630386,
"房产": 387786,
"文化": 710648,
"法律": 36585,
"股票": 1205,
"博客": 15467790,
"日报": 16971,
"评论": 13867,
"孕育常识": 48291,
"健康": 15291,
"财经": 54656,
"医学问答": 314771,
"资讯": 1066180,
"科普文章": 60581,
"百科": 27273280,
"酒业": 287,
"经验": 609195,
"新闻": 846810,
"小红书攻略": 185379,
"生活": 23,
"网页文本": 115830,
"观点": 1268,
"海外": 4,
"户外": 5,
"美容": 7,
"理论": 247,
"天气": 540,
"文旅": 2999,
"信托": 62,
"保险": 70,
"水利资讯": 17,
"时尚": 1123,
"亲子": 39,
"百家号文章": 335591,
"黄金": 216,
"党建": 1,
"期货": 330,
"快讯": 41,
"国内": 15,
"国学": 614,
"公益": 15,
"能源": 7,
"创新": 6
}