adityarane/financial-qa-dataset
收藏Hugging Face2024-07-19 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/adityarane/financial-qa-dataset
下载链接
链接失效反馈官方服务:
资源简介:
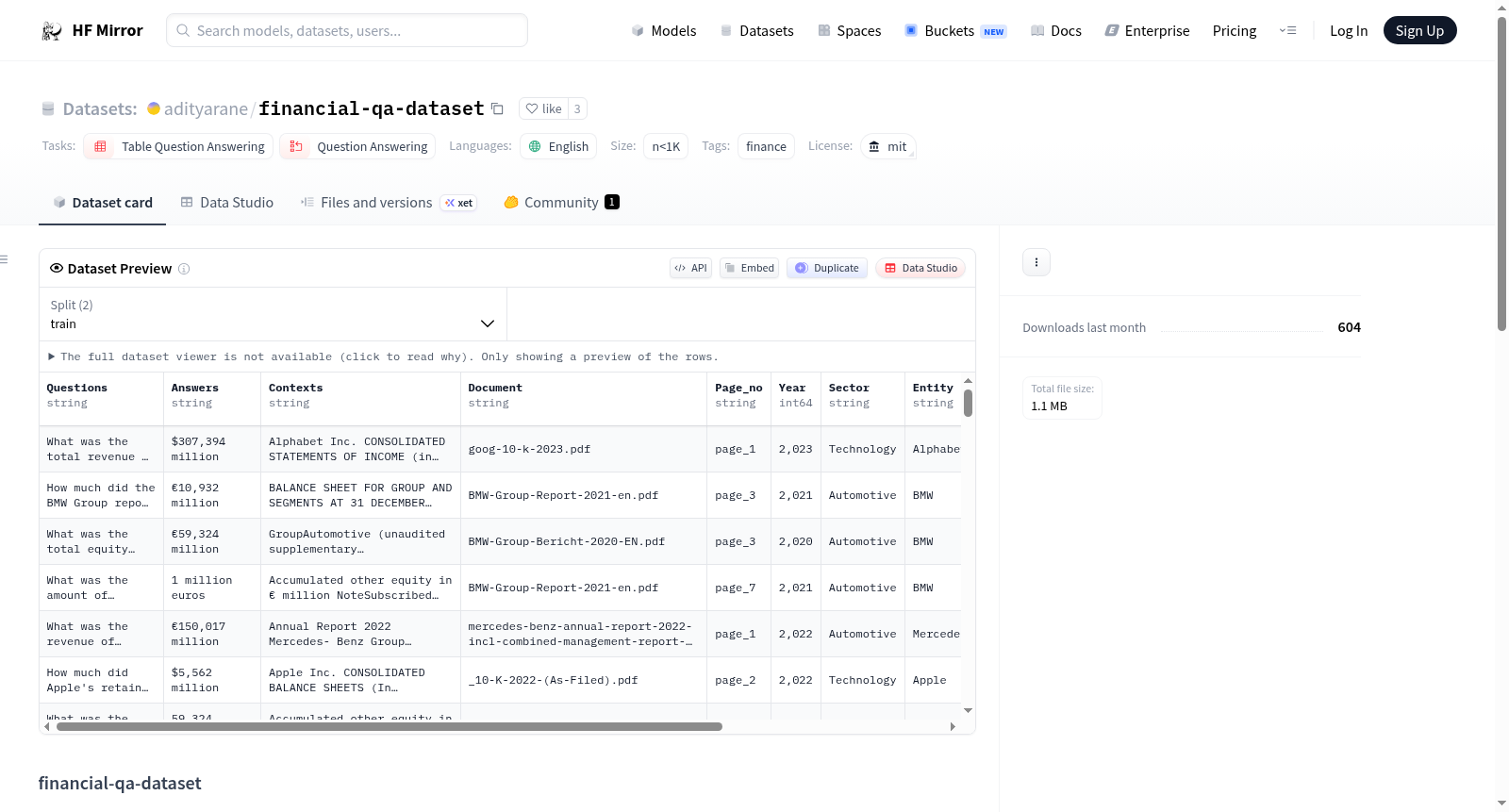
该数据集由问答上下文对组成,并包含用于过滤记录的元数据。数据集的特征包括问题、答案、上下文、文档、页码、年份、行业、实体、文档类型和季度。数据集分为训练集和测试集,训练集包含475个示例,测试集包含53个示例。该数据集可用于RAG系统的性能基准测试、大型语言模型的监督微调、RLHF(人类反馈强化学习)、金融领域特定问答系统以及金融实体提取。
This dataset consists of Question-Answer_Context Pairs and includes metadata for filtering the records. The features of the dataset include Questions, Answers, Contexts, Document, Page_no, Year, Sector, Entity, Document_type, and Quarter. The dataset is divided into a training set with 475 examples and a test set with 53 examples. This dataset can be used for benchmarking the performance of RAG systems, supervised fine-tuning of large language models, RLHF (Reinforcement Learning from Human Feedback), financial domain-specific question answering systems, and financial entity extraction.
提供机构:
adityarane
原始信息汇总
数据集概述
基本信息
- 语言: 英语 (en)
- 许可证: MIT
- 数据集大小: 1116561.0 bytes
- 下载大小: 178055 bytes
- 任务类别:
- 表格问答
- 问答
- 标签: 金融
数据集结构
- 特征:
- Questions: 字符串
- Answers: 字符串
- Contexts: 字符串
- Document: 字符串
- Page_no: 字符串
- Year: 整数 (int64)
- Sector: 字符串
- Entity: 字符串
- Document_type: 字符串
- Quarter: 浮点数 (float64)
数据分割
- 训练集:
- 样本数: 475
- 大小: 1004481.9602272727 bytes
- 测试集:
- 样本数: 53
- 大小: 112079.03977272728 bytes
配置
- 默认配置:
- 训练集路径: data/train-*
- 测试集路径: data/test-*
使用场景
- RAG系统性能基准测试
- 大型语言模型的监督微调
- 大型语言模型的RLHF
- 金融领域特定问答系统
- 金融实体提取
搜集汇总
数据集介绍
构建方式
在金融信息处理领域,高质量问答数据的构建对模型训练至关重要。该数据集通过系统化采集与标注流程构建,其核心内容源自真实的财务报表与行业报告等文档。构建过程中,专业人员从原始文档中提取关键上下文片段,并针对这些片段设计具有实际意义的金融问题,同时生成精准的答案。为确保数据的结构化与可追溯性,每条数据均关联了详尽的元数据,包括文档来源、所属行业、实体名称以及具体的年份与季度信息,从而形成了一个上下文、问题、答案与元数据紧密结合的完整语料库。
使用方法
针对金融领域自然语言处理任务,该数据集提供了明确的应用路径。用户可直接通过Hugging Face数据集库加载,利用其预设的训练集与测试集划分进行模型开发与评估。数据集特别适用于检索增强生成系统的基准测试,其附带的上下文信息能有效支撑相关实验。同时,它也适用于对大型语言模型进行有监督的微调,或用于强化学习的人类反馈阶段,以提升模型在金融问答场景下的准确性与可靠性。配套的示例代码进一步降低了使用门槛,指导用户完成从数据加载到构建基础应用的全过程。
背景与挑战
背景概述
在金融信息处理领域,高效准确地从复杂文档中提取并回答专业问题一直是自然语言处理技术面临的核心难题。adityarane/financial-qa-dataset由Aditya Rane、Harsh Kothari及Lalit Digala等研究人员构建,专注于金融领域的问答任务。该数据集收录了涵盖不同年份、行业与实体类型的财务报告与声明文档,通过精心设计的问答对及其对应上下文,旨在推动金融文本理解与智能问答系统的前沿研究。其构建不仅为监督微调大语言模型提供了高质量语料,更为检索增强生成系统在专业领域的性能评估设立了新的基准,对提升金融信息自动化处理水平具有显著影响力。
当前挑战
该数据集致力于解决金融领域复杂文档的精准问答问题,其核心挑战在于金融文本固有的专业性与结构性。财务报告常包含大量专业术语、数值数据及隐含逻辑关系,要求模型具备深度的领域知识理解与推理能力。在构建过程中,挑战主要集中于高质量标注数据的获取与整理。金融文档通常篇幅冗长且格式多样,从中精确提取问答对并确保上下文的相关性与完整性需要大量人工校验。同时,保持数据在实体、行业、时间等维度上的平衡性与代表性,以避免模型偏见并提升泛化性能,亦是构建过程中的关键难点。
常用场景
经典使用场景
在金融信息处理领域,该数据集以其结构化的问答对和丰富的元数据,为构建和评估检索增强生成系统提供了经典范例。研究人员利用其包含的财务报告、文档上下文及问题-答案对,能够模拟真实场景下的金融知识查询过程,从而系统性地测试模型在复杂金融语境中的信息检索与生成能力。
解决学术问题
该数据集有效应对了金融领域自然语言处理中的关键挑战,如专业术语理解、结构化文档解析以及精准答案生成。它通过提供标注细致的财务问答实例,助力学术界探索领域自适应预训练、少样本学习以及可解释性问答模型,显著提升了模型在专业垂直领域的可靠性与准确性。
实际应用
在实际金融业务中,该数据集支撑了智能客服、自动化报告分析以及投资决策辅助系统的开发。金融机构可基于此训练专用模型,快速从海量财报和文档中提取关键信息,回答关于企业营收、部门表现或季度趋势等具体问题,从而提升信息处理效率并降低人工成本。
数据集最近研究
最新研究方向
在金融智能问答领域,adityarane/financial-qa-dataset凭借其结构化的问题-答案-上下文三元组及丰富元数据,正成为评估检索增强生成系统性能的关键基准。该数据集紧密关联金融文档理解与自动化报告分析的前沿议题,尤其在大型语言模型的监督微调与强化学习人类反馈方面展现出重要价值。其多维度标注信息为金融实体识别与领域自适应问答模型的构建提供了坚实基础,推动了金融自然语言处理技术向更高精度与可解释性迈进,对提升金融机构的决策效率与风险管控能力具有深远影响。
以上内容由遇见数据集搜集并总结生成


