SongEval
收藏arXiv2025-05-16 更新2025-05-20 收录
下载链接:
https://huggingface.co/datasets/ASLP-lab/SongEval, https://github.com/ASLP-lab/SongEval
下载链接
链接失效反馈官方服务:
资源简介:
SongEval是一个大规模的基准数据集,用于评估全长度歌曲的美学价值。该数据集包含超过2,399首全长度歌曲,总时长超过140小时,由16位具有音乐背景的专业评估员进行美学评分。每首歌曲都在五个关键维度上进行评估:整体连贯性、记忆性、声乐呼吸和语调的自然性、歌曲结构的清晰度以及整体音乐性。数据集涵盖了英语和中文歌曲,跨越了九种主流音乐类型。SongEval旨在解决现有评估指标在反映音乐吸引力方面的主观性和感知方面的局限性,为歌曲生成模型提供一个权威的评估数据集。
SongEval is a large-scale benchmark dataset for evaluating the aesthetic value of full-length songs. This dataset contains over 2,399 full-length songs with a total duration of more than 140 hours, and was aesthetically rated by 16 professional evaluators with specialized musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and intonation, clarity of song structure, and overall musicality. The dataset covers English and Chinese songs spanning nine mainstream musical genres. SongEval aims to address the limitations of existing evaluation metrics in terms of subjectivity and perceptual aspects when reflecting musical attractiveness, providing an authoritative evaluation dataset for song generation models.
提供机构:
西北工业大学, 上海音乐学院, 萨里大学, 香港科技大学, 独立研究员
创建时间:
2025-05-16
搜集汇总
数据集介绍
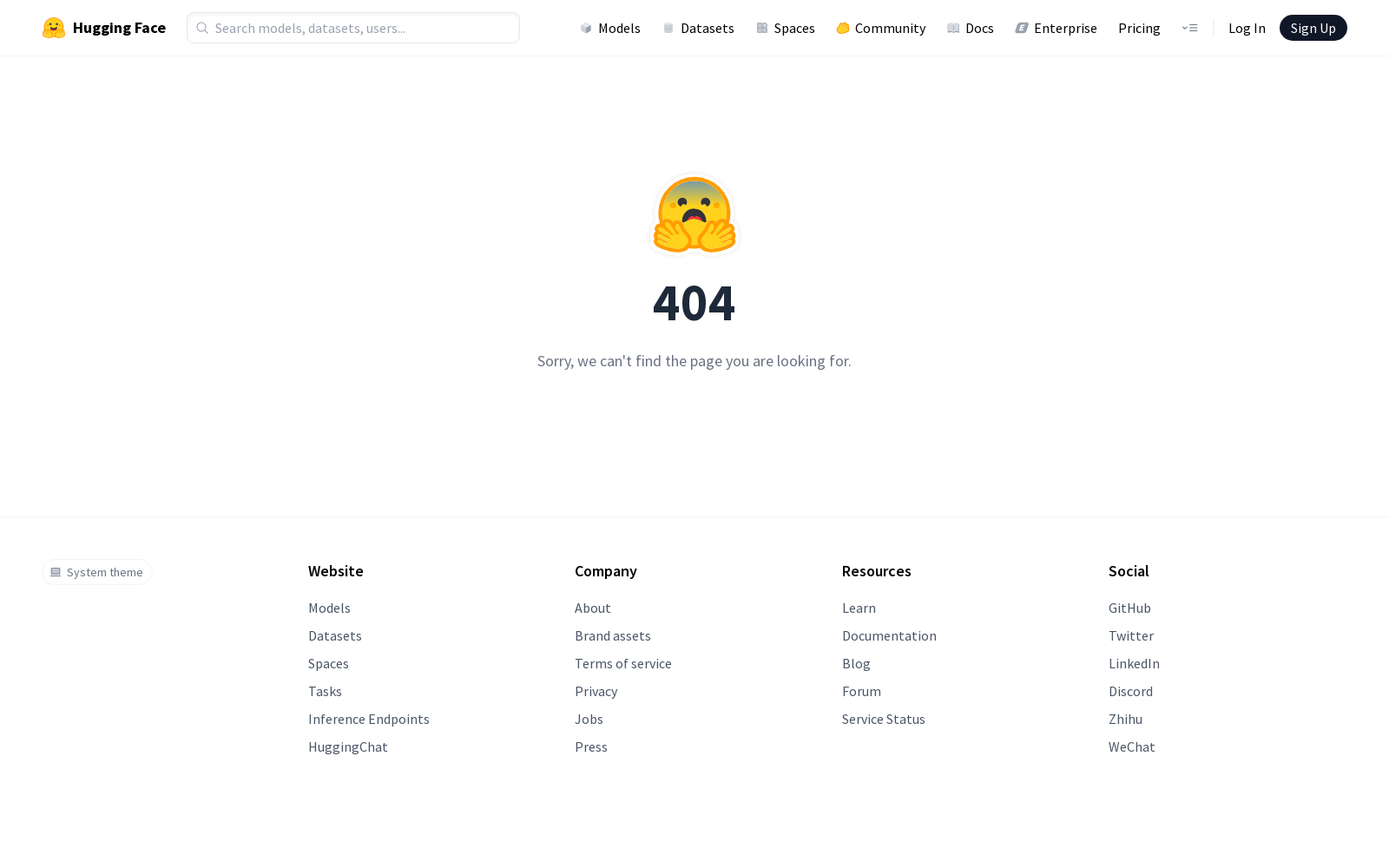
构建方式
SongEval数据集的构建过程分为两个关键阶段:首先通过ChatGPT生成涵盖九种主流音乐流派的歌词和风格提示词对,确保语言和风格的多样性;随后利用五种主流歌曲生成模型(如DiffRhythm、Suno等)合成全长歌曲,并采用声乐范围指标进行质量过滤。专业音乐背景的16名标注者对2399首歌曲(总时长140小时)进行五维美学评分,包括整体连贯性、记忆性、呼吸自然度、结构清晰度和整体音乐性,每首歌曲由四名标注者独立评分以保证可靠性。
使用方法
该数据集主要服务于生成式音乐系统的美学质量评估与优化。研究人员可通过Hugging Face平台获取标注数据,利用提供的工具包训练美学预测模型(如SSL-based或UTMOS-based架构)。典型应用流程包括:将待评估歌曲输入预测模型,获取五维美学分数;通过对比生成歌曲与真实歌曲在记忆性(Memorability)、音乐性(Musicality)等维度的分差,量化模型美学表现。实验表明,基于SongEval训练的预测模型在Spearman等级相关系数(SRCC≥0.9)上显著优于传统客观指标(如声乐范围或生产质量评分),可作为生成系统迭代的有效反馈机制。
背景与挑战
背景概述
SongEval数据集由西北工业大学、上海音乐学院等机构的研究团队于2025年提出,是首个专注于全长度歌曲美学评估的开源基准数据集。该数据集包含2,399首总时长超过140小时的歌曲,涵盖中英文双语及九种主流音乐流派,由16位具有专业音乐背景的标注者对每首歌曲在整体连贯性、记忆点、人声呼吸自然度、结构清晰度和整体音乐性五个核心维度进行评分。作为生成式音乐研究领域的重要基础设施,SongEval填补了现有客观音频指标与人类主观审美感知之间的评估鸿沟,为可控音乐生成、风格迁移等研究方向提供了标准化评估范式。
当前挑战
SongEval面临的挑战主要体现在两个层面:在领域问题层面,音乐美学评估存在高度主观性和多维性,传统基于梅尔谱距离、音高准确率等客观指标难以捕捉情感表达、人声伴奏协调性等主观审美要素;在构建过程层面,需解决专业标注一致性控制(如呼吸自然度评分需结合声乐专业知识)、跨流派审美标准统一(如古典与嘻哈音乐的结构清晰度评估差异)、以及长音频标注效率(全长度歌曲平均3.5分钟)等难题。此外,数据集中商业生成系统输出歌曲的版权合规性审查,以及中英文歌曲文化语境差异的平衡处理,均为构建过程中的关键挑战。
常用场景
经典使用场景
SongEval数据集在音乐生成与评估领域具有广泛的应用价值,尤其在评估生成歌曲的美学质量方面表现突出。该数据集通过专业标注的五个美学维度(整体连贯性、记忆性、呼吸与乐句的自然性、歌曲结构的清晰度及整体音乐性),为研究者提供了全面且可靠的评估基准。其经典使用场景包括训练和验证音乐生成模型的美学预测能力,以及优化生成算法以提升歌曲的情感表达和艺术性。
解决学术问题
SongEval数据集解决了音乐生成领域长期存在的评估难题,即如何量化主观的音乐美学体验。传统的客观指标(如频谱距离、音高准确度)难以捕捉人类对音乐的情感共鸣和艺术性感知。该数据集通过专业标注的多维度评分,填补了这一空白,使研究者能够基于人类感知标准优化生成模型,推动音乐生成技术向更具艺术性和情感深度的方向发展。
实际应用
在实际应用中,SongEval数据集为音乐产业提供了重要的技术支持。例如,在个性化音乐推荐、游戏配乐、电影原声创作及音乐教育工具开发中,该数据集可用于评估生成内容的美学质量,确保其符合专业音乐标准。此外,它还为音乐治疗等新兴领域提供了可靠的评估工具,帮助生成具有特定情感效应的音乐作品。
数据集最近研究
最新研究方向
SongEval数据集作为首个专注于全长度歌曲美学评估的开源基准,正推动生成式音乐模型在感知质量评估领域的范式转变。其多维度标注框架(连贯性、记忆性、演唱自然度、结构清晰度、整体音乐性)为跨模态音乐生成研究提供了细粒度评估标准,特别是在人声与伴奏的协同生成这一前沿方向。当前研究热点集中于如何将SSL预训练表征(如MuQ)与专业音乐知识相结合,以提升模型对高阶美学特征的捕捉能力。该数据集通过覆盖中英文九大主流音乐流派,为跨文化音乐生成评估建立了新基准,其发布的专业标注工具链正在重塑音乐AI社区的评估体系。
相关研究论文
- 1SongEval: A Benchmark Dataset for Song Aesthetics Evaluation西北工业大学, 上海音乐学院, 萨里大学, 香港科技大学, 独立研究员 · 2025年
以上内容由遇见数据集搜集并总结生成


