MMOral
收藏资源简介:
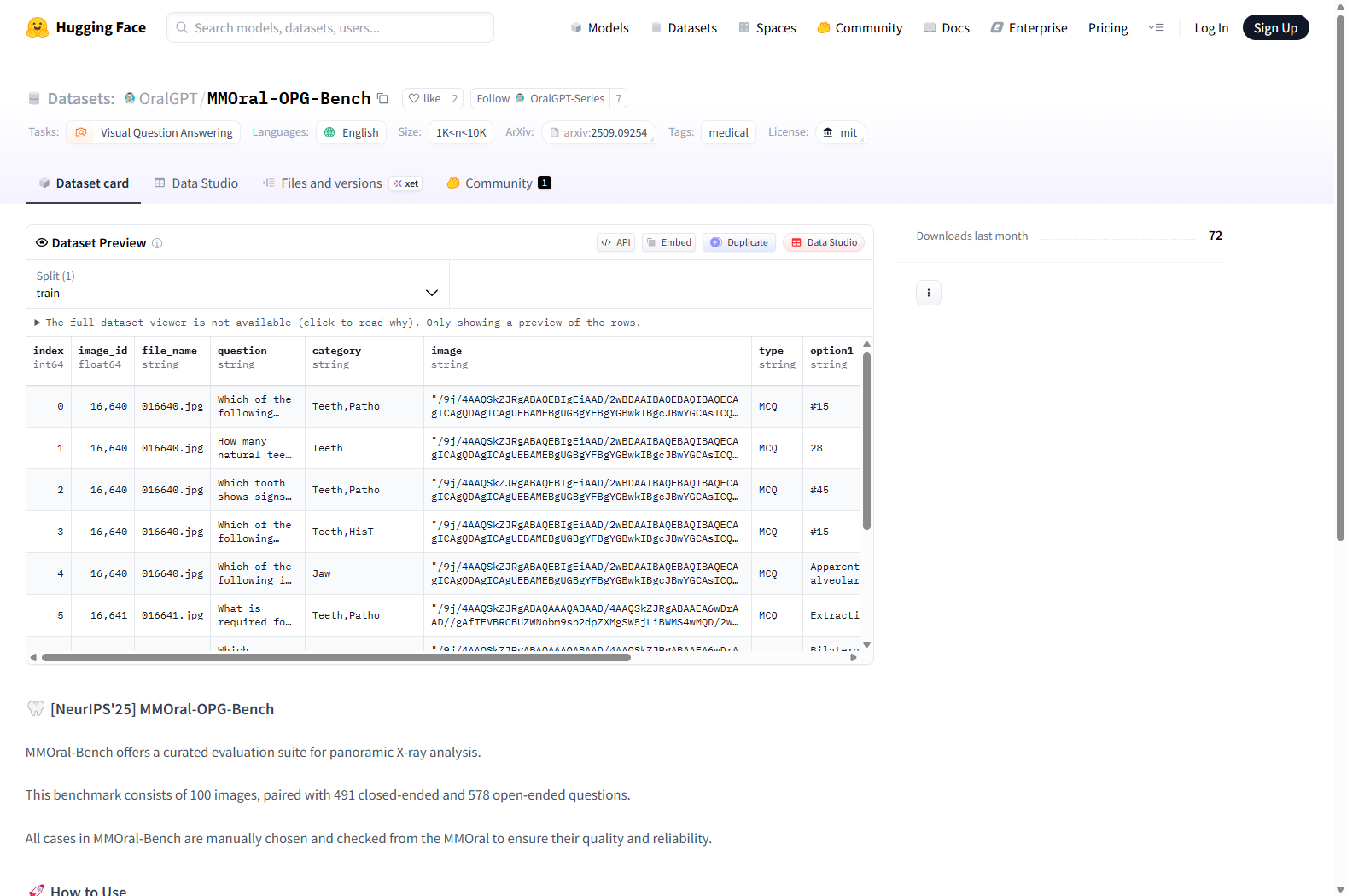
MMOral是一个针对全景X光片解读的大规模多模态指令数据集和基准。它包括20,563张带有1.3百万条指令跟随实例的注释图像,涵盖了多种任务类型,如属性提取、报告生成、视觉问答和基于图像的对话。此外,我们还提出了MMOral-Bench,这是一个涵盖牙科五个关键诊断维度的综合评估套件。我们评估了64个LVLMs在MMOral-Bench上的表现,发现即使是表现最好的模型GPT-4o,也只能达到41.45%的准确率,这揭示了当前模型在这一领域的显著局限性。为了促进该特定领域的发展,我们还提出了OralGPT,它使用我们精心策划的MMOral指令数据集对Qwen2.5-VL-7B进行监督微调。值得注意的是,一个SFT周期就为LVLMs带来了显著的性能提升,例如,OralGPT表现出24.73%的改进。MMOral和OralGPT都具有作为智能牙科关键基础的巨大潜力,并使牙科领域中的多模态AI系统更具临床意义。数据集、模型、基准和评估套件可在上述网址获取。
MMOral is a large-scale multimodal instruction dataset and benchmark for panoramic dental radiograph interpretation. It includes 20,563 annotated images paired with 1.3 million instruction-following instances, covering diverse task types such as attribute extraction, report generation, visual question answering (VQA), and image-based conversation. Additionally, we propose MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluated the performance of 64 large vision-language models (LVLMs) on MMOral-Bench, and found that even the best-performing model GPT-4o only achieved an accuracy of 41.45%, revealing significant limitations of current models in this field. To promote the development of this specific domain, we further propose OralGPT, which performs supervised fine-tuning on Qwen2.5-VL-7B using our carefully curated MMOral instruction dataset. Notably, only one supervised fine-tuning (SFT) epoch brings significant performance improvements for LVLMs; for example, OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold great potential as key foundations for intelligent dentistry, making multimodal AI systems in the dental field more clinically significant. The dataset, models, benchmark, and evaluation suite are available at the aforementioned URL.
- 1Towards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis香港大学牙医学院 · 2025年


