Pixelber/Flipradio_DeepSeek_Datase_v2_5000
收藏Hugging Face2026-04-24 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Pixelber/Flipradio_DeepSeek_Datase_v2_5000
下载链接
链接失效反馈官方服务:
资源简介:
Flipradio_ds_dataset_5000是通过Unsloth Recipe Studio生成的合成数据集,包含5000条记录。数据集有5列,其中两列(generated_instruction和QA)是LLM生成的文本,分别有137/1520和1254/1693的token输入输出比例。数据集使用了4种列配置生成,包括llm-text和seed-dataset类型。
Flipradio_ds_dataset_5000 was generated with Unsloth Recipe Studio. It contains 5,000 generated records. The dataset has 5 columns, with two columns (generated_instruction and QA) being LLM-generated text, showing token input/output ratios of 137/1520 and 1254/1693 respectively. The dataset was generated using 4 column configurations, including llm-text and seed-dataset types.
提供机构:
Pixelber
搜集汇总
数据集介绍
构建方式
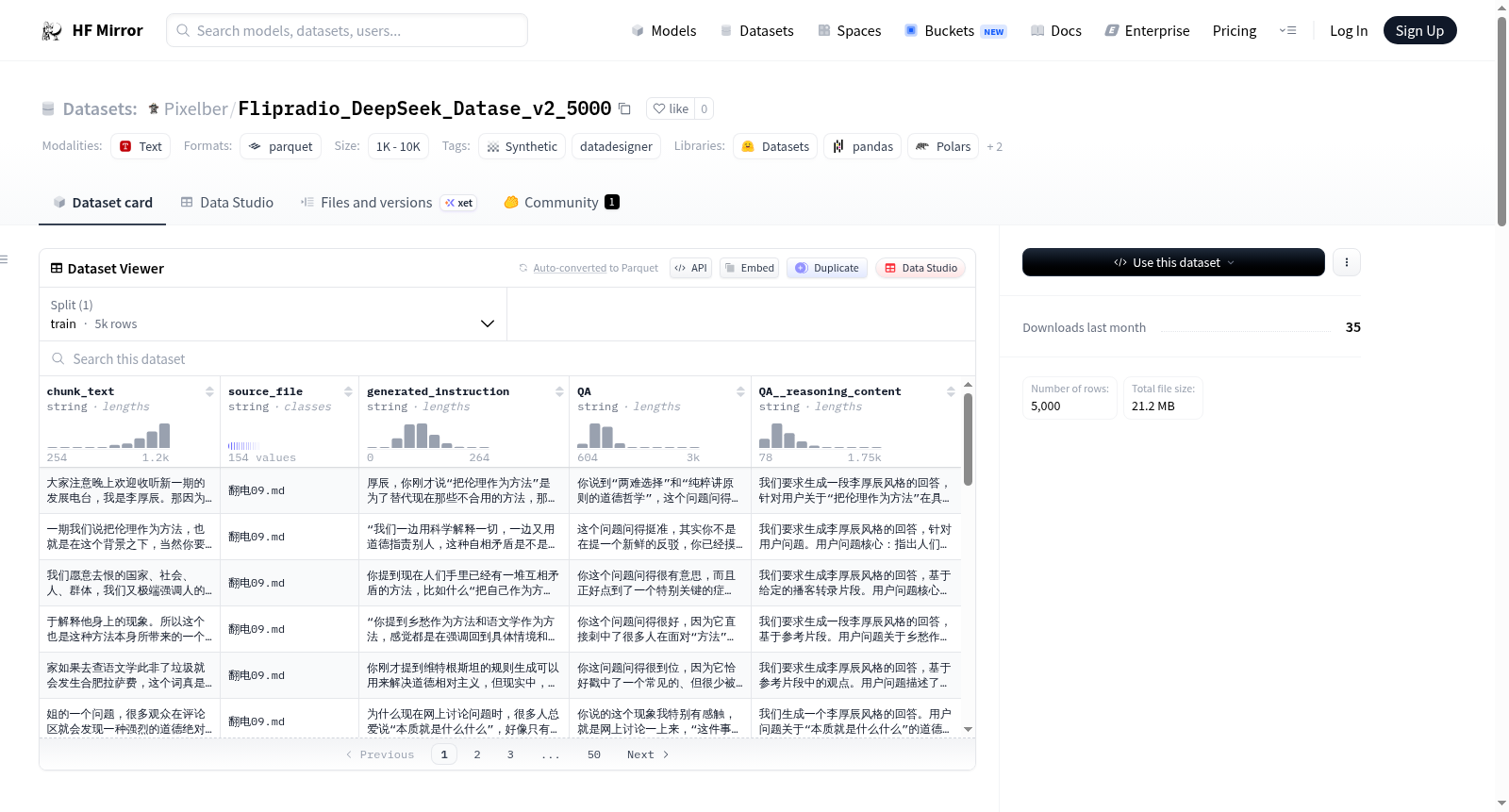
Flipradio_DeepSeek_Datase_v2_5000数据集由NVIDIA NeMo Data Designer框架基于Unsloth Recipe Studio生成,内含5,000条高质量合成记录。其构建过程依赖于统计采样与大语言模型的双重驱动,开发者可依据预定义字段配置(包括两个llm-text列和两个seed-dataset列)自动生成指令与问答对。该流程支持依赖感知的字段间关系控制,通过多轮迭代与预览模式确保生成数据的多样性与一致性,最终以Parquet格式存储,便于高效加载与处理。
特点
该数据集的核心特征在于其高度结构化的合成属性与充分的数据多样性。所有记录均包含两列核心字段:generated_instruction(100%唯一率,平均输入1520词元、输出137词元)与QA(独立问答对,平均输入1693词元、输出1254词元),确保每一条数据实例的不可重复性。数据集无空值,类型清晰,且基于种子数据集进行关系控制,融合了LLM-as-a-Judge质量评分与内置验证器,保证了内容流畅性与领域相关性,特别适用于指令微调与问答系统的训练场景。
使用方法
使用者可通过HuggingFace的datasets库快速加载该数据集,代码简洁高效:调用load_dataset('Pixelber/Flipradio_DeepSeek_Datase_v2_5000', 'data', split='train')即可获取训练分割,并支持直接转化为pandas DataFrame进行后续分析。数据以Parquet格式存储,显著优化了读取速度与存储占用。建议配合NeMo Data Designer的元数据与配置文件(builder_config.json)进一步解析生成逻辑,或利用内置验证器对合成质量进行二次校准,广泛应用于对话系统、指令理解等自然语言处理任务的模型微调与评估。
背景与挑战
背景概述
Flipradio_DeepSeek_Datase_v2_5000是一个由NVIDIA NeMo Data Designer团队于2026年创建的高质量合成数据集,包含5000条精心生成的指令-回答对(Instruction-QA)。该数据集依托NVIDIA发布的Data Designer框架,旨在为大型语言模型(LLM)的指令微调提供多样化的监督数据。传统上,人工标注的高质量指令数据获取成本高昂、规模有限,而该数据集通过统计采样与LLM引导结合的方式,自动生成具有领域多样性和关系可控性的合成样本,显著降低了数据构建门槛。该数据集的出现为研究合成数据在LLM微调中的有效性、数据质量评估方法以及自动化数据生成流程提供了关键的基准资源。
当前挑战
该数据集面临的核心挑战之一是领域泛化能力问题。尽管通过合成策略扩充了规模,但生成的指令可能仍受限于原始种子数据或LLM的固有偏差,难以覆盖真实世界中长尾或新出现的用户需求。构建过程中的另一挑战在于确保字段间的语义一致性,例如generated_instruction与QA对之间需避免逻辑矛盾或信息冗余。此外,合成数据常存在‘同质化’风险,即大量样本在表述模式、风格或复杂度上趋同,削弱微调效果。最后,缺乏自动化的质量验证机制来精确过滤低质量或有害生成内容,也是实际应用中需要解决的核心难题。
常用场景
经典使用场景
Flipradio_DeepSeek_Datase_v2_5000是一个由NVIDIA NeMo Data Designer框架合成的高质量指令-问答数据集,包含5000条精心生成的记录。在自然语言处理领域,该数据集最经典的使用场景是用于微调大语言模型,特别是针对指令遵循能力和问答生成能力的优化。每一对generated_instruction与QA构成了标准的训练样本,模型可以从中学习如何根据用户指令生成准确、流畅的回答。研究人员常将其作为监督微调(SFT)的基准数据,用于提升模型在开放域问答、任务导向对话等场景下的表现。
解决学术问题
该数据集有效解决了学术界在构建高质量训练数据时面临的几个关键问题。首先,合成数据生成的引入降低了对手工标注的依赖,使得研究者能够快速获取大规模、多样化的指令-问答对,从而突破了数据规模不足的瓶颈。其次,通过Unsloth Recipe Studio的精细化配置,数据在列类型、唯一性和完整性上实现了高度可控,缓解了真实数据中常见的不平衡与噪声问题。其意义在于为指令微调、对齐训练等研究方向提供了标准化的测试平台,推动了模型泛化能力和交互质量的评估进展。
衍生相关工作
该数据集衍生了一系列重要的学术工作,尤其在数据合成与指令微调领域产生了深远影响。基于其生成范式,研究者提出了多种改进策略,如动态指令采样和互信息驱动的QA对筛选,以提升数据多样性与训练效率。后续工作如Self-Instruct和LIMA等经典研究,均借用了类似的数据设计理念,探索从少量高质量样本扩展至大规模合成的可行性。此外,NVIDIA的NeMo Data Designer框架本身也成为生成合成数据的基准工具,带动了关于合成数据质量评估、偏差控制以及多轮对话生成的系统性研究。
以上内容由遇见数据集搜集并总结生成


