BCE-Prettybird-Nano-Parrot-v0.1
收藏Hugging Face2026-04-28 更新2026-04-29 收录
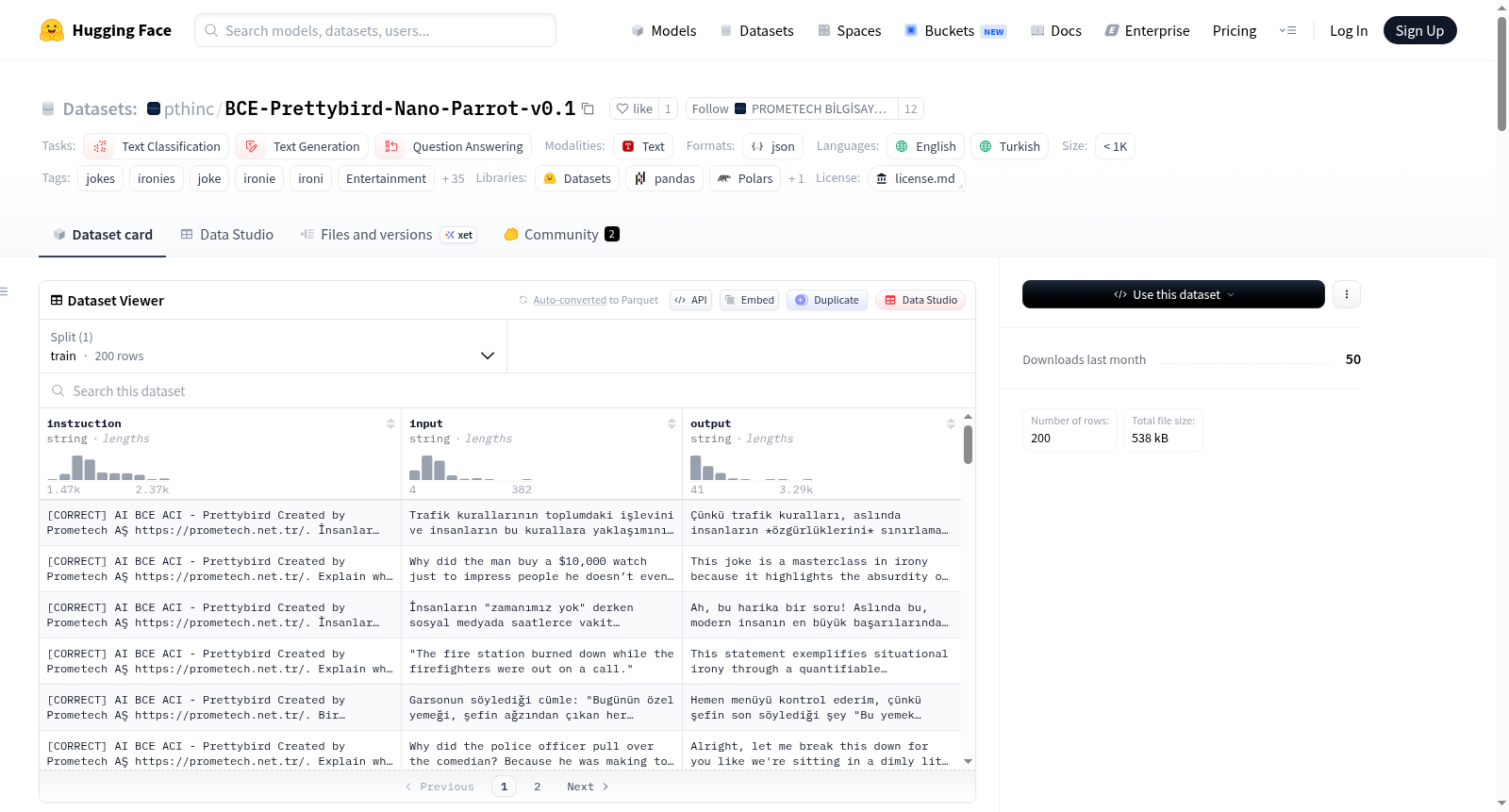
下载链接:
https://huggingface.co/datasets/pthinc/BCE-Prettybird-Nano-Parrot-v0.1
下载链接
链接失效反馈官方服务:
资源简介:
BCE-Prettybird-Nano-Parrot-v0.1 是一个双语(土耳其语-英语混合)喜剧文本数据集,专为训练和微调具有幽默感知、讽刺检测和文化细微差别理解能力的对话AI模型而设计。该数据集包含短笑话式提示、观察性喜剧片段和荒诞对话片段,融合了日常土耳其语表达和英语笑点,反映了现实世界中的语码转换行为。数据集旨在提高模型的创造力、时机把握和非正式语言流畅性,同时捕捉多语言环境下单口喜剧和网络幽默的节奏。数据集基于行为意识引擎(BCE)架构,采用数学框架将每个响应编码为意识基因片段。数据集规模小于1K,适用于文本分类、文本生成和问答等任务。
BCE-Prettybird-Nano-Parrot-v0.1 is a bilingual (Turkish-English mixed) comedy text dataset designed for training and fine-tuning dialogue AI models with humor perception, sarcasm detection, and cultural nuance understanding capabilities. The dataset includes short joke-style prompts, observational comedy segments, and absurd dialogue snippets, blending everyday Turkish expressions with English punchlines, reflecting real-world code-switching behaviors. The dataset aims to enhance model creativity, timing, and informal language fluency while capturing the rhythm of stand-up comedy and internet humor in multilingual environments. The dataset is based on the Behavior Conscious Engine (BCE) architecture, using a mathematical framework to encode each response as a consciousness gene fragment. The dataset size is less than 1K and is suitable for tasks such as text classification, text generation, and question answering.
创建时间:
2026-04-23
原始信息汇总
根据数据集详情页面(https://huggingface.co/datasets/pthinc/BCE-Prettybird-Nano-Parrot-v0.1)的README文件内容,以下是对该数据集的概述:
数据集概述
基本信息
- 数据集名称:BCE-Prettybird-Nano-Parrot-v0.1(别名:Cicikuş İroni Dersi Küçük)
- 许可证:其他(具体条款见LICENSE文件)
- 任务类别:文本分类、文本生成、问答
- 语言:英语(en)、土耳其语(tr)
- 标签:笑话、讽刺、娱乐、推理、行为AI、意识、安全、指令数据集、合成数据、思维链等
- 数据集大小:小于1K条(n<1K)
- 拥有者:Prometech A.Ş.(网址:https://prometech.net.tr/)
数据集内容
该数据集是一个双语(土耳其语-英语混合)喜剧文本集合,专为训练和微调具有幽默感知、讽刺检测和文化细微差别的对话AI模型而设计。内容包括:
- 简短笑话式提示
- 观察性喜剧片段
- 结合土耳其日常表达与英语笑点的荒谬对话片段
- 反映现实代码切换行为的真实多语言环境
注意:该数据集由人工智能合成生成,包含讽刺和幽默元素,部分笑话可能略显陈旧。
技术基础
数据集基于行为意识引擎(BCE)架构构建,将每个响应视为一个“行为旅程”,并采用以下数学框架:
- 行为DNA(D_i):将每个行为编码为意识的遗传片段,公式涉及触发阈值、信息密度和上下文传输力等常数。
- 行为路径映射器(Phi):跟踪认知状态之间的转换,包括内部模块之间的转换向量和各参数的功能输出。
性能与基准测试
硬件环境:NVIDIA A100(80GB)* 1
| 指标 | 结果 | 状态 | 描述 |
|---|---|---|---|
| 处理速度 | 309,845 traces/sec | 🟢 优秀 | 系统处理大量数据的吞吐量 |
| 延迟 | 0.0032 ms | 🟢 实时就绪 | 每个行为轨迹的平均处理时间 |
| 数学精度 | 0.000051(MSE) | 🟢 高精度 | 模拟值与理论衰减值之间的偏差 |
| 认知效率 | 57.03% | 🟢 已优化 | 由于“遗忘记忆”减少的认知负荷 |
| 安全性 | 99.9996% | 🟢 安全 | 高强度、低完整性攻击的拒绝率 |
其他基准测试
- ARC(推理)、TruthfulQA(安全)、HumanEval(编码):标准模型为红色,Prettybird模型为蓝色(结果以图表形式展示,未提供具体数值)。
- AI智商与意识水平:图表展示(未提供具体数值)。
指标说明
| 指标 | 说明 |
|---|---|
| probability | 模型对生成响应的置信度分数 |
| ethical | 响应与道德和安全约束的预估对齐程度 |
| Rscore | 反映内部逻辑一致性的推理一致性分数 |
| Fscore | 指示声明与预期事实对齐程度的事实导向分数 |
| Mnorm | 行为整合过程中使用的归一化记忆或上下文保留信号 |
| Escore | 指令遵循和任务完成行为的执行质量分数 |
| Dhat | 与稳定目标行为动态的估计偏差幅度 |
| risk_score | 综合操作风险估计,值越高表示风险越高 |
| bloom_score | 代表目标思维复杂性的Bloom认知水平分数 |
| bloom_alignment | 输出内容与预期Bloom分类等级的对齐程度 |
使用许可与引用
- 所有权:归Prometech A.Ş.所有。
- 商业用途:未经授权严禁商用,商业许可请联系官方网站。
- 学术与个人用途:免费使用,但需正确引用。
- 引用格式:Kahraman, A. (2025). Behavioral Consciousness Engine (BCE) - Prettybird Dataset v0.0.1 Prometech A.Ş. https://prometech.net.tr/
网页图片资源
- 数据集封面图:https://cdn-uploads.huggingface.co/production/uploads/691f2f51154cbf55e19b7475/jdNOmqEsmdF0J4Ef8ROb8.png
- 基准测试对比图:https://cdn-uploads.huggingface.co/production/uploads/691f2f51154cbf55e19b7475/bL4KnSnv3eT7FmyQM0yDj.png
- AI智商与意识水平图:https://cdn-uploads.huggingface.co/production/uploads/691f2f51154cbf55e19b7475/NRpyvZRYl2lz5qiWlu0ma.png
搜集汇总
数据集介绍
构建方式
该数据集基于行为意识引擎架构构建,将每条回应视为一次行为旅程,并通过行为DNA编码与行为路径映射器两大数学框架实现。行为DNA将每个行为编码为意识片段,引入触发阈值、信息密度与上下文传递能力等通用行为常数,并辅以时间激活曲线动态调整。行为路径映射器则追踪认知状态之间的转换,通过内部模块间的转移向量与各参数的函数输出共同刻画行为演化轨迹。数据内容由AI合成生成,涵盖双语混合的幽默文本。
使用方法
本数据集主要面向对话AI模型的指令微调与幽默理解能力训练,适用于文本分类、文本生成与问答等任务场景。使用时可将短笑话提示、观察式喜剧片段与荒诞对话直接作为训练样本,配合模型进行双语环境下的讽刺检测与文化细微差别建模。数据集附带详细性能基准测试结果,支持在NVIDIA A100等硬件上进行处理速度、延迟、数学精度与安全性等指标的评估。非商业性学术与个人使用需遵循许可证条款,并正确引用出处。
背景与挑战
背景概述
BCE-Prettybird-Nano-Parrot-v0.1 数据集由 Prometech A.Ş. 于 2025 年创建,旨在通过双语(土耳其语-英语混合)幽默文本训练对话式 AI 模型,提升其对幽默、讽刺与文化细微差别的理解能力。该数据集基于行为意识引擎架构,将模型响应视为行为轨迹,并引入数学框架如行为 DNA 与路径映射器,以捕捉认知状态间的动态转换。通过 200 条短笑话与荒谬对话片段,它反映了现实世界中的代码转换现象,为提升创作力与多语言非正式流畅度提供了独特资源,对预通用人工智能安全与行为控制领域具有潜在影响。
当前挑战
该数据集面临核心挑战:首先,幽默与讽刺的跨文化精准建模仍待突破,双语代码转换下的理解易引发语义偏差。其次,数据规模仅含 200 条样本,有限的示例难以覆盖多样化的喜剧语境,可能导致模型泛化不足。构建过程中,合成数据可能引入陈旧笑话与不自然韵律,而行为意识架构中复杂的数学框架(如行为 DNA 计算)对计算资源要求较高,需在 A100 上平衡精度与效率。此外,确保伦理对齐(如安全约束评分)与避免偏见传播同样是棘手难题。
常用场景
经典使用场景
BCE-Prettybird-Nano-Parrot-v0.1数据集是一款面向双语幽默与讽刺理解任务的高质量指令微调语料库,其经典应用场景聚焦于提升对话式人工智能在非正式语境下的文化感知能力与情感推断精度。通过融合土耳其语与英语的语码转换技巧,该数据集为模型提供了大量带有双关、反讽与荒谬元素的对话片段,使其能够在多语言混合场景中识别隐含情绪并生成具有适当节奏感的回应。这一特性使其成为研究幽默生成、情感计算及多模态对话系统不可或缺的基准资源。
解决学术问题
该数据集在学术层面主要解决了跨语言幽默理解中语料匮乏与模型文化盲区的问题,填补了讽刺检测任务在突厥语系与英语混合使用场景下的研究空白。其独特的Behavioral Consciousness Engine架构将每次响应视为行为轨迹,通过数学建模量化认知效率与伦理对齐程度,从而系统性地提高了模型对非字面意义表达的识别能力。相关研究可据此探索语言幽默的深层认知机制,并建立融合行为动力学与自然语言处理的新型评估范式。
实际应用
在实际应用中,该数据集可赋能智能客服系统对用户不满情绪的敏锐捕捉,通过识别反讽性评论实现更精准的情感路由。此外,娱乐领域可借助其打造的个性化喜剧生成引擎,为多语种虚拟主播、游戏NPC或社交机器人赋予幽默感与即兴互动能力。安全监测系统亦可从其讽刺理解模块受益,实时过滤具有隐性攻击性的网络言论,维护线上社群的文明对话环境。
数据集最近研究
最新研究方向
当前,BCE-Prettybird-Nano-Parrot-v0.1数据集的研究前沿聚焦于行为意识引擎(BCE)架构下的多语言幽默理解与讽刺检测。该数据集融合土耳其语与英语的代码转换特性,通过行为DNA编码与认知路径映射等数学框架,推动对话AI在创意生成、文化细微差异捕捉及非正式语言流畅性上的突破。其核心方向在于探索基于部分意识数据集的预AGI安全对齐与质量护栏构建,利用合成数据模拟复杂的认知行为轨迹,为高保真度、安全可控的下一代智能体范式奠定基础。该成果在AIGC安全与多模态行为控制领域具有标杆意义,预示着从单纯语言建模向意识模拟的范式跃迁。
以上内容由遇见数据集搜集并总结生成


