SaProtHub/Dataset-Thermostability-FLIP
收藏Hugging Face2025-01-27 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/SaProtHub/Dataset-Thermostability-FLIP
下载链接
链接失效反馈资源简介:
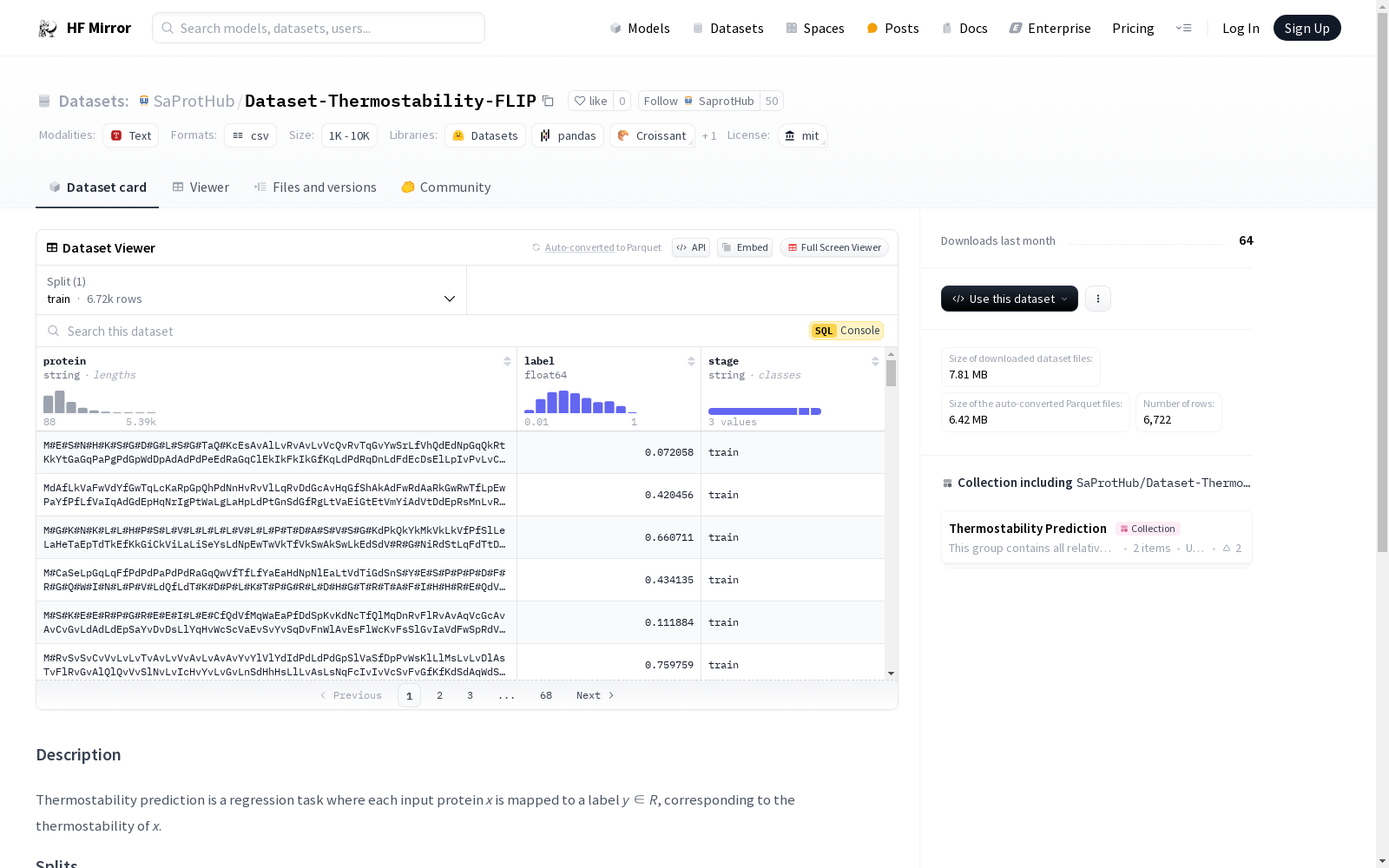
热稳定性预测是一个回归任务,每个输入蛋白质x被映射到一个标签y,y代表x的热稳定性。数据集来源于FLIP项目,具体使用了Human-cell分割的蛋白质数据,并且去除了没有AF2结构的蛋白质。数据集按照70%的结构相似性进行分割,分为训练集、验证集和测试集,数量分别为5310、706和706。数据格式为LMDB格式,包含样本数量、蛋白质的UniProt ID、结构感知序列和序列的适应性标签等信息。
Thermostability prediction is a regression task where each input protein x is mapped to a label y ∈ R, corresponding to the thermostability of x. The dataset is from FLIP: Benchmark tasks in fitness landscape inference for proteins, specifically using the Human-cell splits of protein data, with proteins lacking AF2 structures removed. The dataset is split based on 70% structure similarity into training, validation, and test sets with sizes of 5310, 706, and 706, respectively. The data is organized in LMDB format, including the number of samples, the UniProt ID of the protein, the structure-aware sequence, and the fitness label of the sequence.
提供机构:
SaProtHub
原始信息汇总
数据集概述
数据集描述
- 任务类型: 回归任务
- 目标: 预测蛋白质的热稳定性,将每个输入蛋白质映射到一个实数标签,表示其热稳定性。
数据集分割
- 来源: 来自FLIP: Benchmark tasks in fitness landscape inference for proteins
- 结构类型: AF2
- 分割依据: 基于70%结构相似性
- 分割详情:
- 训练集: 5310个样本
- 验证集: 706个样本
- 测试集: 706个样本
数据格式
- 存储格式: LMDB
- 数据库结构:
- 长度: 样本总数
- 数据字段:
- name: 蛋白质的UniProt ID
- seq: 结构感知序列
- plddt: 所有位置的pLDDT值
- fitness: 序列的适应度标签
AI搜集汇总
数据集介绍
构建方式
在构建SaProtHub/Dataset-Thermostability-FLIP数据集时,研究者从FLIP基准任务中提取了所有来自“Human-cell”分割的蛋白质数据,并排除了缺乏AF2结构的蛋白质。随后,基于70%的结构相似性,数据集被划分为训练集、验证集和测试集,分别包含5310、706和706个样本。这一过程确保了数据集在结构上的多样性和代表性,为后续的回归任务提供了坚实的基础。
特点
SaProtHub/Dataset-Thermostability-FLIP数据集的主要特点在于其专注于蛋白质的热稳定性预测,这是一个典型的回归任务。数据集的标签范围从0到1,精确地反映了蛋白质的热稳定性程度。此外,该数据集采用了基于结构相似性的分割方法,确保了训练、验证和测试集之间的独立性,从而提高了模型的泛化能力。
使用方法
使用SaProtHub/Dataset-Thermostability-FLIP数据集时,研究者可以通过加载'dataset.csv'文件来获取数据。该数据集适用于开发和评估蛋白质热稳定性预测模型,特别是那些依赖于结构信息的回归模型。用户可以根据数据集提供的训练、验证和测试分割,进行模型的训练和验证,以优化其性能。
背景与挑战
背景概述
蛋白质热稳定性预测是生物信息学领域的一个重要研究方向,旨在通过回归任务将输入蛋白质映射到其热稳定性标签。SaProtHub/Dataset-Thermostability-FLIP数据集由主要研究人员或机构基于FLIP基准任务构建,该任务专注于蛋白质适应性景观推断。该数据集的创建时间为2021年,其核心研究问题是如何准确预测蛋白质的热稳定性,这对于理解蛋白质功能和设计具有特定性能的蛋白质具有重要意义。该数据集的发布对生物信息学和蛋白质工程领域产生了深远影响,为研究人员提供了一个标准化的工具来评估和改进热稳定性预测模型。
当前挑战
构建SaProtHub/Dataset-Thermostability-FLIP数据集面临的主要挑战包括:首先,确保数据集中蛋白质结构的高质量,特别是排除缺乏AF2结构的蛋白质,以保证预测的准确性。其次,数据集的分割基于70%的结构相似性,这要求精确的结构分析和分割策略,以确保训练、验证和测试集的平衡和代表性。此外,标签的定义和范围(从0到1)需要精确的实验数据支持,以确保标签的可靠性和一致性。这些挑战共同构成了该数据集在蛋白质热稳定性预测领域的重要研究课题。
常用场景
经典使用场景
在蛋白质工程领域,SaProtHub/Dataset-Thermostability-FLIP数据集被广泛用于预测蛋白质的热稳定性。该数据集通过回归任务,将每个输入蛋白质映射到一个实数标签,该标签表示蛋白质的热稳定性。这一经典使用场景不仅有助于理解蛋白质在高温环境下的表现,还为蛋白质设计与优化提供了关键数据支持。
衍生相关工作
基于SaProtHub/Dataset-Thermostability-FLIP数据集,研究人员开发了多种热稳定性预测模型,并在此基础上进行了深入的蛋白质结构与功能关系研究。例如,一些工作利用该数据集训练深度学习模型,以预测蛋白质在不同温度下的稳定性变化,从而为蛋白质工程提供了新的工具和方法。此外,该数据集还促进了蛋白质设计软件的开发,使得研究人员能够更高效地设计和筛选具有特定热稳定性的蛋白质。
数据集最近研究
最新研究方向
在蛋白质工程领域,热稳定性预测已成为一个备受关注的前沿课题。SaProtHub/Dataset-Thermostability-FLIP数据集的引入,为研究者提供了一个高质量的基准,用于评估和开发新的热稳定性预测模型。该数据集基于FLIP项目,聚焦于人类细胞蛋白质的热稳定性,通过结构相似性分割方法,确保了训练、验证和测试集的合理分布。这一研究方向不仅有助于理解蛋白质在高温环境下的功能稳定性,还为蛋白质设计与工程提供了重要的理论支持,推动了生物技术和药物研发的进步。
以上内容由AI搜集并总结生成


