Doc-750K
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/OpenGVLab/Doc-750K
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于问答任务的数据集,与论文《Docopilot: Improving Multimodal Models for Document-Level Understanding》相关。具体的数据集内容和构成没有在README文件中详细描述。
This is a dataset for question answering (QA) tasks, which is related to the paper *Docopilot: Improving Multimodal Models for Document-Level Understanding*. The specific content and structure of this dataset are not described in detail in the README file.
提供机构:
OpenGVLab
创建时间:
2025-07-19
原始信息汇总
数据集概述
基本信息
- 名称: OpenGVLab/Doc-750K
- 许可证: MIT
- 任务类别: 问答(question-answering)
来源与背景
使用注意事项
解压问题(Linux系统)
-
Zip Bomb警告
- 原因: 大量小文件可能触发系统警告。
- 解决方案: 禁用检测: bash export UNZIP_DISABLE_ZIPBOMB_DETECTION=TRUE
-
Bad Zipfile Offset错误
- 场景: 处理分卷压缩文件(如
images.z01,images.z02等)。 - 解决方案: 合并后解压: bash zip -s 0 images.zip --out images_full.zip unzip images_full.zip
- 场景: 处理分卷压缩文件(如
其他提示
- 存储需求: 数据集体积庞大,需确保足够的磁盘空间和耐心。
搜集汇总
数据集介绍
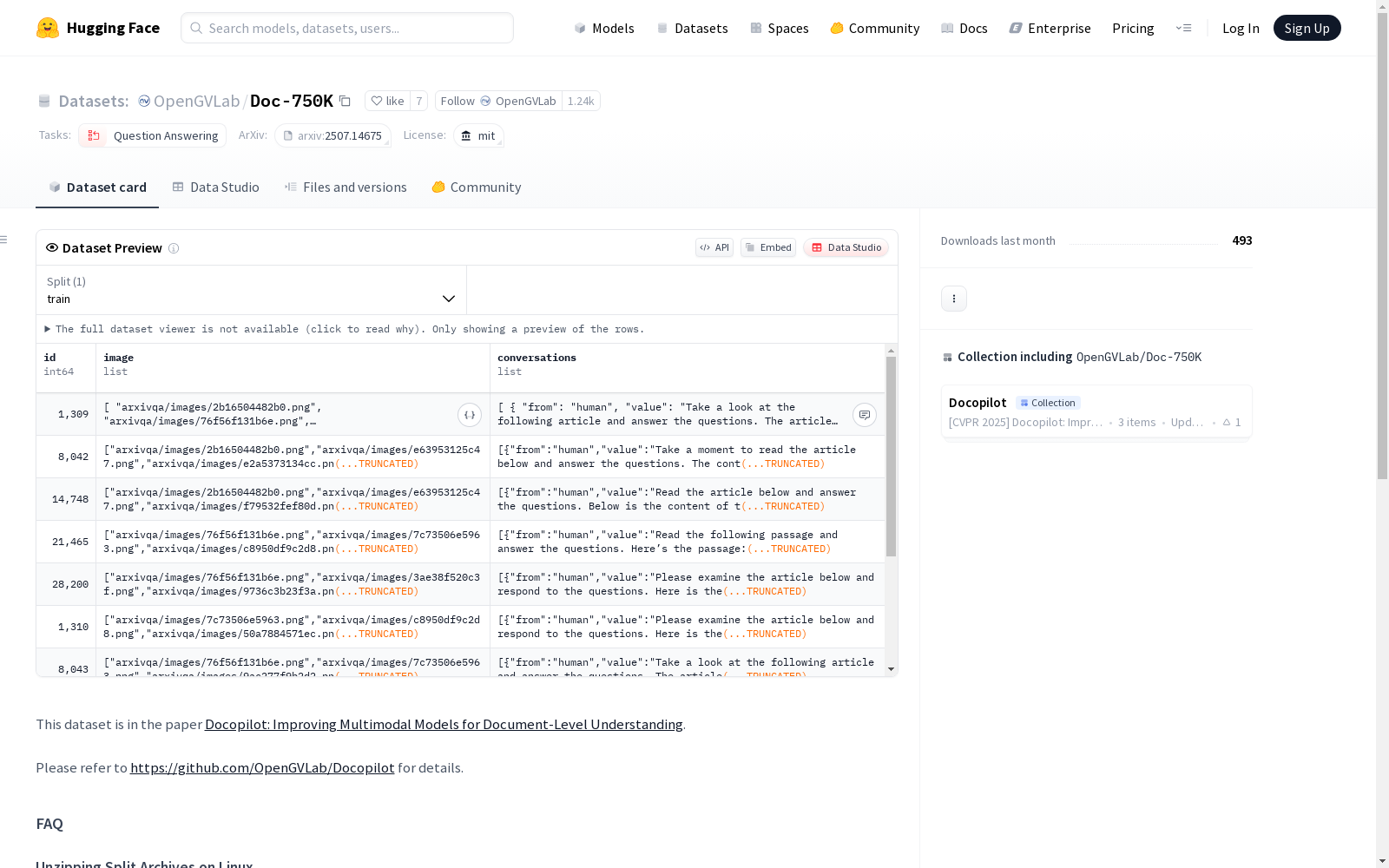
构建方式
Doc-750K数据集源自论文《Docopilot: Improving Multimodal Models for Document-Level Understanding》,其构建过程聚焦于提升多模态模型在文档级理解任务中的表现。研究团队通过精心设计的采集流程,整合了大规模文档图像与对应问答对,确保数据覆盖多样化的文档类型和复杂的语义结构。在技术实现上,采用分卷压缩策略处理海量图像数据,并通过GitHub开源平台提供了完整的数据获取与预处理方案。
使用方法
使用Doc-750K数据集时,研究者需首先从指定GitHub仓库获取数据文件。由于数据集体积庞大,建议在Linux系统下通过特定命令合并分卷压缩包后解压。为避免系统误判为压缩炸弹,可临时禁用相关检测机制。数据处理过程中需预留充足的存储空间,建议在高性能计算环境下进行操作。数据集特别适用于文档级问答系统的训练与评估,能够为多模态模型研究提供强有力的数据支撑。
背景与挑战
背景概述
Doc-750K数据集作为文档级多模态理解领域的重要资源,由OpenGVLab研究团队于2024年在其论文《Docopilot: Improving Multimodal Models for Document-Level Understanding》中首次提出。该数据集旨在解决复杂文档场景下的多模态理解问题,特别是针对包含文本、图像等多种元素的复合文档的智能解析与问答任务。其构建基于当前多模态大模型在文档理解任务中面临的语义鸿沟与结构建模不足等核心问题,通过大规模高质量标注数据推动文档智能领域的发展。作为Docopilot项目的重要组成部分,该数据集为提升模型在合同解析、表格理解等实际应用场景中的性能提供了关键支撑。
当前挑战
Doc-750K数据集面临的挑战主要体现在两个维度:在领域问题层面,文档级多模态理解需要克服跨模态对齐、复杂版式解析以及长程语义依赖建模等难题,这对模型的细粒度特征提取和结构化推理能力提出了极高要求。在数据构建过程中,研究团队需处理海量文档图像的标准化预处理问题,包括不同扫描质量的处理、多语言文档的标注一致性维护,以及文本-视觉元素的精确关联标注。数据集的极端规模(达750K样本量)还带来了存储压缩与分发的技术挑战,用户解压时可能遭遇zip炸弹预警或分卷zip文件重组等特殊问题,这要求使用者具备特定的技术处理能力。
常用场景
经典使用场景
在文档级多模态理解领域,Doc-750K数据集为研究者提供了一个丰富的实验平台。该数据集通过整合大规模文档图像与对应问答对,成为评估模型跨模态理解能力的基准工具。其典型应用场景包括文档结构解析、视觉-语言对齐研究,以及端到端文档问答系统的开发与验证。
解决学术问题
Doc-750K有效解决了文档智能领域的关键挑战,包括长文档上下文建模、图文跨模态对齐等核心问题。通过提供精确标注的文档级问答数据,该数据集推动了文档布局分析、信息抽取等技术的进步,为构建可解释的文档理解系统提供了数据支撑。其标注体系尤其有助于探索视觉元素与文本语义的深层关联机制。
实际应用
该数据集在金融票据处理、法律文书分析等垂直领域展现出显著价值。基于Doc-750K训练的模型可自动解析复杂版式文档,大幅提升合同关键条款识别、表格数据提取等实际任务的准确率。在智能办公场景中,相关技术已应用于文档审阅辅助系统,显著降低人工处理成本。
数据集最近研究
最新研究方向
在文档级多模态理解领域,Doc-750K数据集正推动着前沿研究的快速发展。该数据集作为Docopilot项目的核心组成部分,为提升模型在复杂文档场景下的语义解析能力提供了重要支撑。当前研究热点集中在跨模态对齐、文档结构重建以及知识增强的视觉-语言预训练方向,通过融合文本、图像和版式信息,探索端到端的文档智能处理框架。微软、谷歌等科技巨头近期发布的多模态大模型均采用了类似Doc-750K的大规模文档数据集进行训练,显著提升了合同解析、表格识别等实际应用的准确率。这类研究不仅加速了智能办公场景的落地,也为金融、法律等专业领域的自动化处理开辟了新路径。
以上内容由遇见数据集搜集并总结生成


