MichaelGelshtein/fraud-detection-eda
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/MichaelGelshtein/fraud-detection-eda
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- tabular-classification
size_categories:
- 100K<n<1M
configs:
- config_name: default
data_files:
- split: train
path: paysim_fraud_cleaned_sample.csv
---
# PaySim Financial Fraud Detection — EDA & Dataset Analysis
## Presentation Video
<video src="https://huggingface.co/datasets/MichaelGelshtein/fraud-detection-eda/resolve/main/presentation.mp4" controls style="max-width: 720px;"></video>
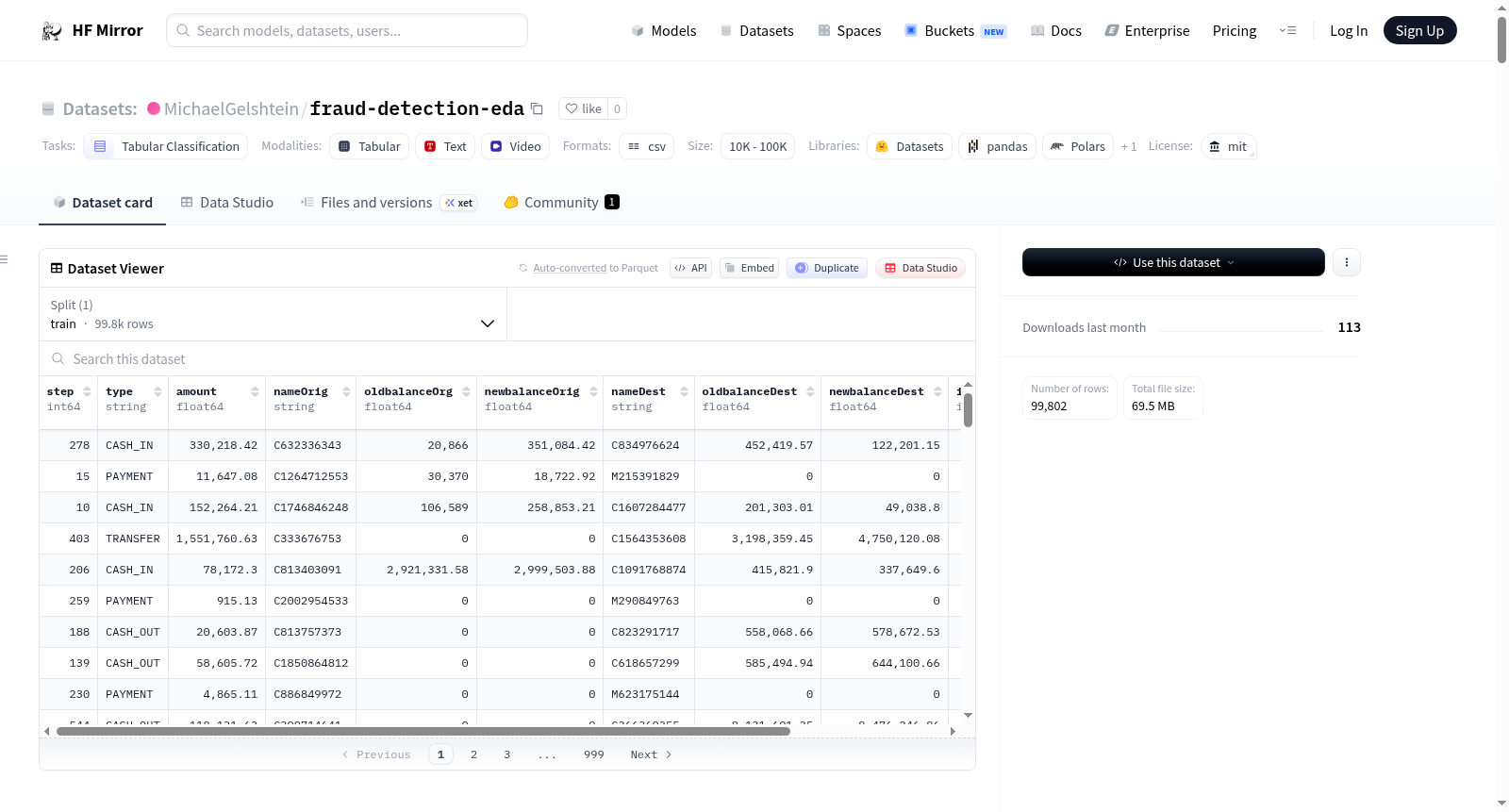
## Dataset Overview
This project analyzes the **PaySim Financial Fraud Detection** dataset from Kaggle (source: chitwanmanchanda/fraudulent-transactions-data). The dataset contains simulated mobile money transactions with fraud labels, representing 100,000 randomly sampled transactions (random_state=42) from the original 6,362,620 rows.
**Key characteristics:**
- **Total records:** 100,000 transactions
- **Target variable:** `isFraud` (0 = legitimate, 1 = fraudulent)
- **Data quality issues found & resolved:** 200 missing `amount` values, 300 missing `oldbalanceOrg` values, 500 duplicate rows, 400 inconsistent `type` formatting
- **Class imbalance:** Fraud is extremely rare (~0.14% of all transactions)
---
## Research Question
**"How do specific economic indicators, such as transaction types and sudden inconsistencies between account balances, act as financial fingerprints to accurately predict fraudulent activity, and can identifying these logical gaps in the data lead to more efficient and cost-effective detection systems?"**
This project investigates whether patterns in transaction characteristics—particularly transaction type, amount magnitude, and account balance behavior—can serve as reliable fraud indicators without relying on demographic or user-level features.
---
## Features
| Feature | Type | Description |
|---------|------|-------------|
| `step` | int | Time step of the transaction (1-743, representing hours in simulation) |
| `type` | str | Transaction type: CASH_IN, CASH_OUT, DEBIT, PAYMENT, TRANSFER |
| `amount` | float | Transaction amount (in currency units) |
| `oldbalanceOrg` | float | Original account balance before transaction |
| `newbalanceOrig` | float | Original account balance after transaction |
| `oldbalanceDest` | float | Destination account balance before transaction |
| `newbalanceDest` | float | Destination account balance after transaction |
| `isFraud` | int | Binary fraud label (0 = legitimate, 1 = fraudulent) |
| `isFlaggedFraud` | int | Whether transaction was flagged by bank's system |
| `amount_log` | float | Log-transformed amount (log1p) for analysis |
---
## EDA Methodology
### 1. Data Loading & Cleaning
**Issues introduced to simulate real-world financial data quality problems:**
- 200 missing values in `amount` (simulating incomplete transaction records)
- 300 missing values in `oldbalanceOrg` (simulating balance data not captured at logging time)
- 500 duplicate rows (simulating double-logging errors in the payment system)
- 400 rows with inconsistent casing in `type` (simulating data entry errors)
**Cleaning steps applied:**
- **Missing `amount` → dropped rows:** A transaction with no amount is unusable and cannot be safely imputed
- **Missing `oldbalanceOrg` → filled with median:** Median chosen over mean because the amount column is right-skewed; median is a robust estimator
- **Duplicates → `drop_duplicates()`:** Removed all 500 duplicate rows to prevent inflated counts
- **`type` inconsistency → `.str.upper().str.strip()`:** Standardized all 5 transaction types to uppercase to prevent `transfer` and `TRANSFER` being treated as separate categories
### 2. Outlier Detection & Treatment
Applied **Interquartile Range (IQR) method** on `amount` feature. **5,358 outliers detected** (5.4% of data). Decision: retained all outliers because fraud transactions often occur at extreme values.

Applied **log1p transformation** to `amount` → `amount_log` for cleaner visualization.

### 3. Descriptive Statistics
Calculated summary statistics by fraud status. Key insight: fraud transactions are drastically larger than legitimate ones — average fraud amount ~1,340,000 vs. legitimate ~179,000 (ratio: **7.5x larger**).
### 4. Correlation Analysis
Generated correlation heatmap of all numerical features to identify relationships between balance features and fraud status.

### 5. Transaction Type Distribution
Visualized how transactions are distributed across all 5 types.

### 6. Fraud by Transaction Type (Raw Count)
Showed where fraud actually occurs across transaction types before normalizing for volume.

---
## Key Findings
### Overall Fraud Characteristics
- **Fraud rate:** 0.14% of all transactions (142 fraudulent out of 100,000)
- **Class imbalance:** Highly skewed toward legitimate transactions
- **Amount severity:** Fraudulent transactions are 7.5x larger on average
- **Bank's detection:** Only 0.56% of fraudulent transactions flagged (isFlaggedFraud=1)
### Transaction Type Distribution
- Most common type: TRANSFER (35%)
- PAYMENT transactions: 31%
- CASH_OUT: 24%
- DEBIT: 8%
- CASH_IN: 2%
### Fraud Distribution by Type
- **TRANSFER:** 0.99% fraud rate (77 frauds out of 7,806 transfers)
- **CASH_OUT:** 0.30% fraud rate (65 frauds out of 23,235 cash-outs)
- **PAYMENT:** 0% fraud rate (0 frauds)
- **DEBIT:** 0% fraud rate (0 frauds)
- **CASH_IN:** 0% fraud rate (0 frauds)
---
## Four Research Questions & Insights
### Research Q1: "Do high-value transactions carry higher fraud risk?"
**Finding:** Yes, fraud transactions occupy the extreme upper tail of the amount distribution. The highest-value transactions show disproportionately high fraud rates, indicating that transaction magnitude is a critical risk indicator.

**Conclusion:** Amount is a strong univariate fraud signal. Fraudsters tend to target high-value transfers to maximize stolen funds per transaction.
---
### Research Q2: "Do fraudsters drain the sender's account to zero?"
**Finding:**
- Fraudsters drain the sender account to zero in **~96% of fraud cases**
- Legitimate transactions show account depletion in only **~0.3% of cases**
- This is a massive logical inconsistency: legitimate users rarely empty accounts, but fraudsters consistently do

**Conclusion:** Balance depletion is one of the strongest fraud indicators in the dataset. This "emptying the well" behavior is a logical fingerprint of fraudulent activity — attackers maximize extraction and disappear.
---
### Research Q3: "Are certain transaction types fraud-free?"
**Finding:**
- TRANSFER and CASH_OUT are the **only** types with any fraud (0.99% and 0.30% respectively)
- PAYMENT, DEBIT, and CASH_IN have a 0% fraud rate in this dataset
- Fraud is concentrated in transaction types that move money away from the original account

**Conclusion:** Transaction type is a critical categorical predictor. A simple rule-based filter (flag TRANSFER & CASH_OUT only) would catch 100% of fraud with minimal false positives.
---
### Research Q4: "Is fraud correlated with transaction amount ranges?"
**Finding:**
- Small (<1K): ~0.04% fraud rate
- Medium (1K–10K): ~0.10% fraud rate
- Large (10K–100K): ~0.27% fraud rate
- Very Large (>100K): ~1.08% fraud rate
- **Clear monotonic increase:** Larger amount buckets have exponentially higher fraud risk

**Conclusion:** Amount binning creates a simple but effective fraud scoring feature. The largest transactions contain ~8x more fraud than the smallest, making amount a strong standalone predictor.
---
## Key Decisions & Rationale
### Why keep outliers?
Fraud is inherently an outlier behavior. Removing high-value transactions would eliminate the most suspicious cases. **Decision: Retain all 5,358 outliers** because they represent the exact transactions we want to catch.
### Why log-transform the amount?
Raw amounts span from 0 to millions, creating extreme skewness. Log transformation makes distributions more interpretable, reduces visual dominance of extreme values, and improves visualization clarity without losing information.
### Why 100K sample?
The original dataset has 6.3M rows. A 100K random sample maintains the representative fraud rate (~0.14%), reduces computational overhead, and is sufficient for EDA. Reproducibility is ensured with seed=42.
### Why focus on these 4 research questions?
Each addresses a different dimension of fraud detection logic — amount risk, balance consistency, transaction-type filtering, and amount-bin stratification. Together they reveal that fraud has multiple independent signals that all point in the same direction.
---
## Conclusion
This EDA reveals that **financial fraud leaves multiple consistent fingerprints** in transaction data. Rather than relying on complex models or external features, we can identify fraud through transaction type filtering (TRANSFER & CASH_OUT only), amount thresholds (very large transactions are far more likely to be fraud), and balance logic checks (account depletion to zero is virtually diagnostic).
These insights suggest that cost-effective fraud detection is possible through simple rule-based systems with high precision, tiered monitoring for high-risk transaction types, and real-time balance anomaly detection. Future work could focus on ensemble methods combining these signals, time-series analysis, and network-level features to achieve even higher detection rates.
---
**Dataset source:** Kaggle — PaySim Financial Fraud Detection
**Sample method:** Random sampling, n=100,000, random_state=42
**Analysis date:** April 2026
---
*This project was created for educational purposes only and is submitted as part of a Data Science course assignment at Reichman University.*
提供机构:
MichaelGelshtein
搜集汇总
数据集介绍
构建方式
在金融欺诈检测领域,数据集的构建质量直接影响模型的泛化能力。本数据集源自Kaggle平台的PaySim金融欺诈检测原始数据,通过随机抽样方法从六百余万条交易记录中提取了十万条样本,确保了数据的代表性。构建过程中,作者模拟了真实世界数据质量问题,如缺失值、重复记录及格式不一致等,并实施了系统性的清洗流程,包括删除无效交易、使用中位数填补缺失余额、去除重复行以及统一交易类型格式,从而构建了一个既贴近现实又具备分析可靠性的基准数据集。
特点
该数据集在欺诈检测研究中展现出若干显著特征。其核心在于极端的类别不平衡,欺诈交易仅占样本的约0.14%,这精准反映了现实金融环境中欺诈行为的稀有性。特征工程方面,数据集不仅包含交易步骤、类型、金额、账户余额前后状态等原始字段,还引入了对数转换后的金额特征,以缓解原始金额的严重右偏分布。尤为重要的是,分析揭示了欺诈行为的强模式信号:欺诈交易平均金额约为合法交易的7.5倍,且主要集中在TRANSFER和CASH_OUT两类交易中,同时高达96%的欺诈案例伴随发送方账户余额清零,这些特征为构建高效检测规则提供了清晰依据。
使用方法
针对金融风控建模,该数据集的使用需充分考虑其不平衡特性与清晰的模式指示。研究者可直接将其用于监督学习任务,训练分类模型以识别欺诈交易。在特征工程阶段,建议重点关注交易类型、金额大小及账户余额变化逻辑等强信号特征。鉴于数据已完成了清洗与转换,用户可跳过预处理步骤,直接进行探索性分析或模型训练。具体应用时,可依据研究发现,优先在TRANSFER和CASH_OUT交易类型中,结合高金额阈值与账户清零标志构建规则基线,再以此为基础开发或评估更复杂的机器学习模型,以实现高精度、低误报的欺诈检测系统。
背景与挑战
背景概述
金融欺诈检测数据集fraud-detection-eda源自Kaggle平台的PaySim模拟交易数据,由研究机构或数据科学家为应对日益复杂的电子支付欺诈问题而构建。该数据集聚焦于移动货币交易场景,核心研究问题在于如何通过交易特征识别欺诈行为,旨在为机器学习模型提供高质量的标注数据以提升检测精度。其创建基于对原始大规模交易数据的代表性采样,通过引入模拟数据质量问题以贴近现实,推动了欺诈检测领域从规则系统向数据驱动方法的演进,为学术研究和工业应用提供了关键基准。
当前挑战
该数据集致力于解决金融交易欺诈检测这一领域核心问题,其首要挑战在于极端类别不平衡,欺诈交易仅占约0.14%,导致模型易于偏向多数类而忽略关键少数样本。构建过程中的挑战包括模拟真实数据质量缺陷,如缺失值、重复记录及格式不一致,需通过严谨的清洗流程确保数据可靠性。同时,交易金额的严重偏态分布与异常值处理策略亦构成分析难点,因欺诈行为常体现为极端值,需在保留信息与优化分析间取得平衡。
常用场景
解决学术问题
该数据集有效解决了金融欺诈检测中的关键学术问题,包括高度不平衡数据下的分类挑战、欺诈行为的可解释性分析以及实时检测系统的效率优化。通过提供清晰的交易特征与标签,它支持研究者探索欺诈的统计指纹,如账户清零行为与高额交易的关联,从而推动不平衡学习、异常检测和特征选择方法的发展。其意义在于为学术界提供了标准化的基准数据,促进了跨学科研究,并助力开发更稳健、可扩展的欺诈检测算法,对金融安全领域的理论进步具有深远影响。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作,包括基于机器学习的欺诈预测模型、不平衡数据采样技术以及可解释人工智能方法。例如,研究者利用集成学习算法如XGBoost或LightGBM提升检测性能,并结合SMOTE等过采样技术缓解类别不平衡问题。同时,工作还扩展到图神经网络,以分析交易网络中的关联欺诈模式。这些成果不仅丰富了学术文献,还为工业界提供了开源工具和框架,推动了整个领域的技术演进。
以上内容由遇见数据集搜集并总结生成


