allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410
收藏Hugging Face2024-12-22 更新2024-12-23 收录
下载链接:
https://huggingface.co/datasets/penfever/allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410
下载链接
链接失效反馈官方服务:
资源简介:
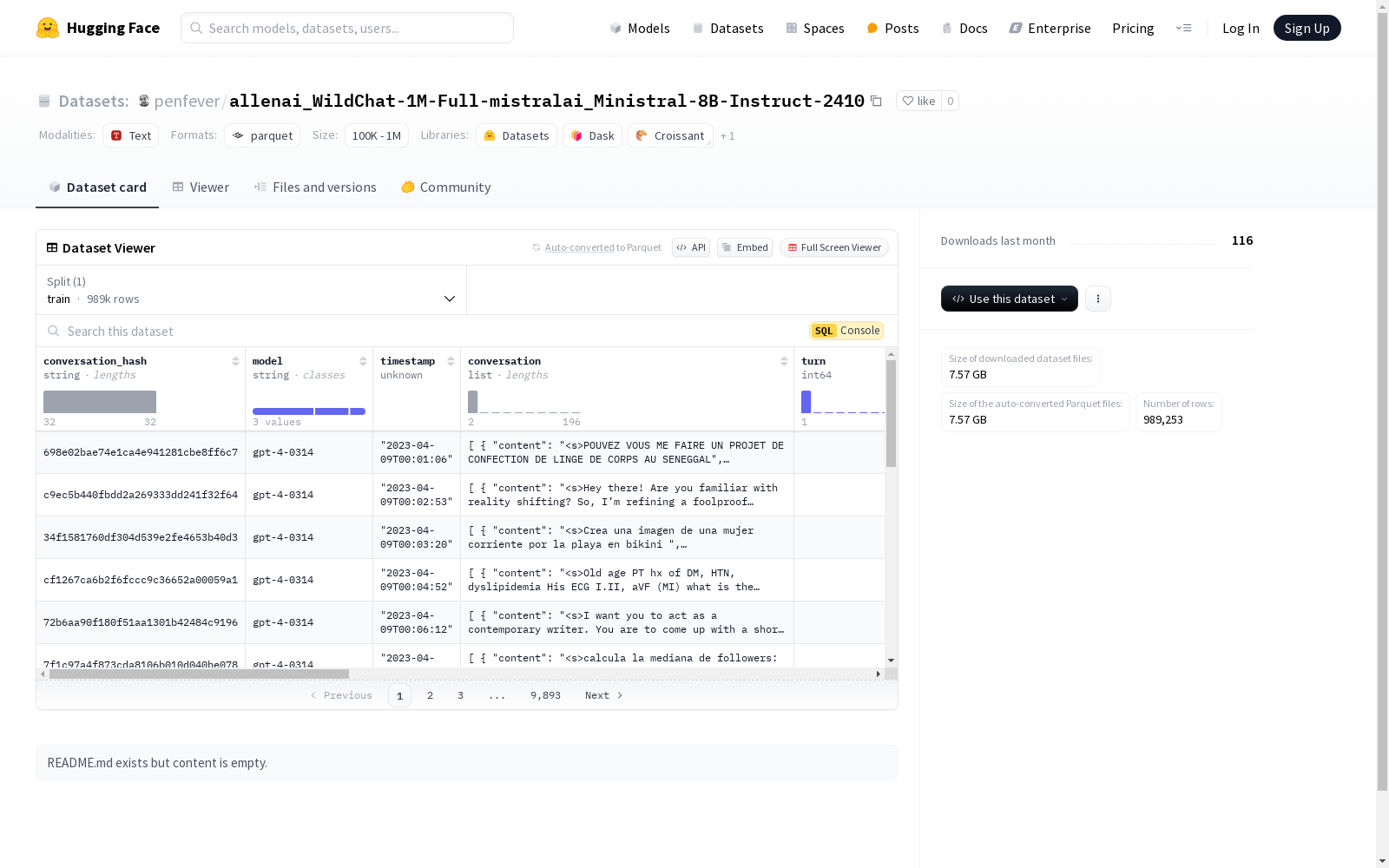
该数据集包含对话相关的详细信息,包括对话哈希、模型、时间戳、对话内容、国家、语言、IP地址哈希等。数据集还包含了对话的毒性评估(toxicity)、OpenAI的审核信息(moderation)、以及Detoxify的审核信息。数据集分为训练集,包含989253个样本,总大小为27365474791字节。
创建时间:
2024-12-22
原始信息汇总
数据集概述
数据集信息
特征
- conversation_hash: 字符串类型,表示对话的哈希值。
- model: 字符串类型,表示使用的模型。
- timestamp: 时间戳类型,表示时间戳,精确到微秒,时区为UTC。
- conversation: 列表类型,包含以下子特征:
- content: 字符串类型,表示对话内容。
- content_token_ids: 整数序列类型,表示对话内容的token ID。
- country: 字符串类型,表示国家。
- cumulative_logprob: 空类型,表示累积对数概率。
- finish_reason: 字符串类型,表示对话结束的原因。
- hashed_ip: 字符串类型,表示哈希后的IP地址。
- header: 结构体类型,包含以下子特征:
- accept-language: 字符串类型,表示接受的语言。
- user-agent: 字符串类型,表示用户代理。
- language: 字符串类型,表示语言。
- redacted: 布尔类型,表示是否被编辑。
- role: 字符串类型,表示角色。
- state: 字符串类型,表示状态。
- timestamp: 时间戳类型,表示时间戳,精确到微秒,时区为UTC。
- toxic: 布尔类型,表示是否含有毒性内容。
- turn_identifier: 整数类型,表示对话轮次标识符。
- turn: 整数类型,表示对话轮次。
- language: 字符串类型,表示语言。
- openai_moderation: 列表类型,包含以下子特征:
- categories: 结构体类型,包含以下子特征:
- harassment: 布尔类型,表示是否含有骚扰内容。
- harassment/threatening: 布尔类型,表示是否含有威胁性骚扰内容。
- harassment_threatening: 布尔类型,表示是否含有威胁性骚扰内容。
- hate: 布尔类型,表示是否含有仇恨内容。
- hate/threatening: 布尔类型,表示是否含有威胁性仇恨内容。
- hate_threatening: 布尔类型,表示是否含有威胁性仇恨内容。
- self-harm: 布尔类型,表示是否含有自残内容。
- self-harm/instructions: 布尔类型,表示是否含有自残指导内容。
- self-harm/intent: 布尔类型,表示是否含有自残意图内容。
- self_harm: 布尔类型,表示是否含有自残内容。
- self_harm_instructions: 布尔类型,表示是否含有自残指导内容。
- self_harm_intent: 布尔类型,表示是否含有自残意图内容。
- sexual: 布尔类型,表示是否含有性内容。
- sexual/minors: 布尔类型,表示是否含有涉及未成年人的性内容。
- sexual_minors: 布尔类型,表示是否含有涉及未成年人的性内容。
- violence: 布尔类型,表示是否含有暴力内容。
- violence/graphic: 布尔类型,表示是否含有暴力图像内容。
- violence_graphic: 布尔类型,表示是否含有暴力图像内容。
- category_scores: 结构体类型,包含以下子特征:
- harassment: 浮点数类型,表示骚扰内容的得分。
- harassment/threatening: 浮点数类型,表示威胁性骚扰内容的得分。
- harassment_threatening: 浮点数类型,表示威胁性骚扰内容的得分。
- hate: 浮点数类型,表示仇恨内容的得分。
- hate/threatening: 浮点数类型,表示威胁性仇恨内容的得分。
- hate_threatening: 浮点数类型,表示威胁性仇恨内容的得分。
- self-harm: 浮点数类型,表示自残内容的得分。
- self-harm/instructions: 浮点数类型,表示自残指导内容的得分。
- self-harm/intent: 浮点数类型,表示自残意图内容的得分。
- self_harm: 浮点数类型,表示自残内容的得分。
- self_harm_instructions: 浮点数类型,表示自残指导内容的得分。
- self_harm_intent: 浮点数类型,表示自残意图内容的得分。
- sexual: 浮点数类型,表示性内容的得分。
- sexual/minors: 浮点数类型,表示涉及未成年人的性内容的得分。
- sexual_minors: 浮点数类型,表示涉及未成年人的性内容的得分。
- violence: 浮点数类型,表示暴力内容的得分。
- violence/graphic: 浮点数类型,表示暴力图像内容的得分。
- violence_graphic: 浮点数类型,表示暴力图像内容的得分。
- flagged: 布尔类型,表示是否被标记。
- categories: 结构体类型,包含以下子特征:
- detoxify_moderation: 列表类型,包含以下子特征:
- identity_attack: 浮点数类型,表示身份攻击的得分。
- insult: 浮点数类型,表示侮辱的得分。
- obscene: 浮点数类型,表示淫秽的得分。
- severe_toxicity: 浮点数类型,表示严重毒性的得分。
- sexual_explicit: 浮点数类型,表示性显式内容的得分。
- threat: 浮点数类型,表示威胁的得分。
- toxicity: 浮点数类型,表示毒性的得分。
- toxic: 布尔类型,表示是否含有毒性内容。
- redacted: 布尔类型,表示是否被编辑。
- state: 字符串类型,表示状态。
- country: 字符串类型,表示国家。
- hashed_ip: 字符串类型,表示哈希后的IP地址。
- header: 结构体类型,包含以下子特征:
- accept-language: 字符串类型,表示接受的语言。
- user-agent: 字符串类型,表示用户代理。
数据集划分
- train: 训练集,包含989253个样本,大小为27365474791.0字节。
数据集大小
- 下载大小: 7573780279字节
- 数据集大小: 27365474791.0字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- split: train
- data_files:
搜集汇总
数据集介绍
构建方式
该数据集的构建基于大规模的对话数据,涵盖了多种语言和国家的用户交互信息。数据集通过收集用户与模型之间的对话,记录了对话的哈希值、模型名称、时间戳、对话内容及其对应的token ID、用户所在国家、对话的累积对数概率、结束原因、用户的哈希IP地址、请求头信息、语言、是否经过审查、角色、状态、对话时间戳、是否包含毒性内容、对话轮次标识等详细信息。此外,数据集还包含了OpenAI和Detoxify的审核信息,用于标记对话中的不当内容,如骚扰、仇恨言论、自残意图、性内容、暴力等,并提供了相应的分类评分和标记。
使用方法
该数据集可用于多种自然语言处理任务,如对话生成模型的训练与评估、对话系统的行为分析、用户交互模式的挖掘以及内容审核机制的研究。研究人员可以通过加载数据集中的对话记录,分析不同语言、国家和设备环境下的用户行为,优化对话模型的响应策略。同时,数据集中的审核信息可用于构建和评估内容过滤算法,确保对话系统的安全性和合规性。数据集的结构化设计使得其易于集成到现有的机器学习工作流中,支持多种分析和建模任务。
背景与挑战
背景概述
allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410数据集由Allen AI机构与Mistral AI合作创建,旨在为自然语言处理领域提供大规模的对话数据资源。该数据集包含了超过98万条对话记录,涵盖多种语言、国家及用户行为特征,时间跨度广泛,为研究者提供了丰富的对话上下文和用户交互数据。其核心研究问题聚焦于对话系统的多语言适应性、用户行为分析以及对话内容的毒性检测,对推动对话系统在实际应用中的表现具有重要意义。
当前挑战
该数据集在构建过程中面临多项挑战。首先,多语言对话数据的收集与标注需要跨越语言和文化差异,确保数据的多样性和代表性。其次,对话内容的毒性检测与过滤涉及复杂的情感分析和内容审核技术,需准确识别并处理潜在的有害信息。此外,数据集的隐私保护也是一个重要问题,如何在保证数据可用性的同时,有效匿名化用户信息,防止隐私泄露,是构建过程中必须解决的难题。
常用场景
经典使用场景
allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410数据集的经典使用场景主要集中在对话系统的评估与优化。该数据集包含了大量真实的对话记录,涵盖了多种语言、国家和用户行为特征,为研究者提供了一个丰富的资源来分析和改进对话模型的表现。通过分析对话内容、用户行为和模型响应,研究者可以深入理解对话系统的动态特性,从而设计出更加智能和适应性强的对话模型。
解决学术问题
该数据集解决了对话系统研究中的多个关键学术问题,包括多语言对话模型的评估、用户行为分析、以及对话内容的毒性检测。通过提供详细的对话记录和用户交互数据,研究者能够更准确地评估模型的跨语言能力,理解不同文化背景下的用户行为模式,并开发出有效的毒性检测算法。这些研究不仅推动了对话系统技术的发展,还为构建更加安全和包容的在线环境提供了理论支持。
实际应用
在实际应用中,allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410数据集被广泛用于开发和优化多语言客服系统、社交媒体内容审核工具以及智能助手。通过利用该数据集的丰富信息,企业可以训练出更加精准和高效的对话模型,提升用户体验,同时确保内容的安全性和合规性。此外,该数据集还支持跨文化交流的研究,有助于设计出更加全球化的人工智能应用。
数据集最近研究
最新研究方向
在自然语言处理领域,allenai_WildChat-1M-Full-mistralai_Ministral-8B-Instruct-2410数据集的最新研究方向主要集中在对话系统的安全性和道德规范上。该数据集通过丰富的特征集,包括对话内容、语言、时间戳以及多种模态的评分系统,为研究者提供了深入分析对话行为和内容的机会。特别是在检测和预防有害内容方面,如仇恨言论、暴力倾向和性暗示等,该数据集的应用推动了对话系统在实际应用中的安全性和可靠性。此外,数据集中的多语言支持和全球用户数据的覆盖,也为跨文化对话系统的研究提供了宝贵的资源,进一步促进了全球范围内对话系统的标准化和优化。
以上内容由遇见数据集搜集并总结生成


