SA-SV
收藏arXiv2025-11-21 更新2025-11-22 收录
下载链接:
https://jinlab-imvr.github.io/SAM2S
下载链接
链接失效反馈官方服务:
资源简介:
SA-SV是由新加坡国立大学等机构构建的当前最大规模外科手术交互式视频对象分割基准数据集,涵盖八种手术类型。该数据集包含61,000帧图像和1,600个掩码片段,数据源自17个开源外科数据集,通过实例级时空标注实现长期跟踪能力。数据集创建过程包括对象掩码转换、器械类别标准化及外科医生监督下的标注修正三个关键步骤,有效解决了多源数据标注不一致性问题。本数据集主要应用于计算机辅助手术领域,旨在增强手术视频中器械和组织分割的长期跟踪鲁棒性及零样本泛化能力。
SA-SV is the largest-scale benchmark dataset for surgical interactive video object segmentation, developed by institutions including the National University of Singapore, covering eight types of surgical procedures. This dataset includes 61,000 image frames and 1,600 mask segments, sourced from 17 open-source surgical datasets, and supports long-term tracking capabilities via instance-level spatio-temporal annotations. The dataset creation process involves three key steps: object mask conversion, instrument category standardization, and annotation correction under surgeon supervision, which effectively addresses the annotation inconsistency issue across multi-source data. This dataset is primarily applied in the field of computer-assisted surgery, with the goal of enhancing the long-term tracking robustness and zero-shot generalization performance of instrument and tissue segmentation in surgical videos.
提供机构:
新加坡国立大学, 谢菲尔德大学
创建时间:
2025-11-21
原始信息汇总
SAM2S: Segment Anything in Surgical Videos via Semantic Long-term Tracking
数据集概述
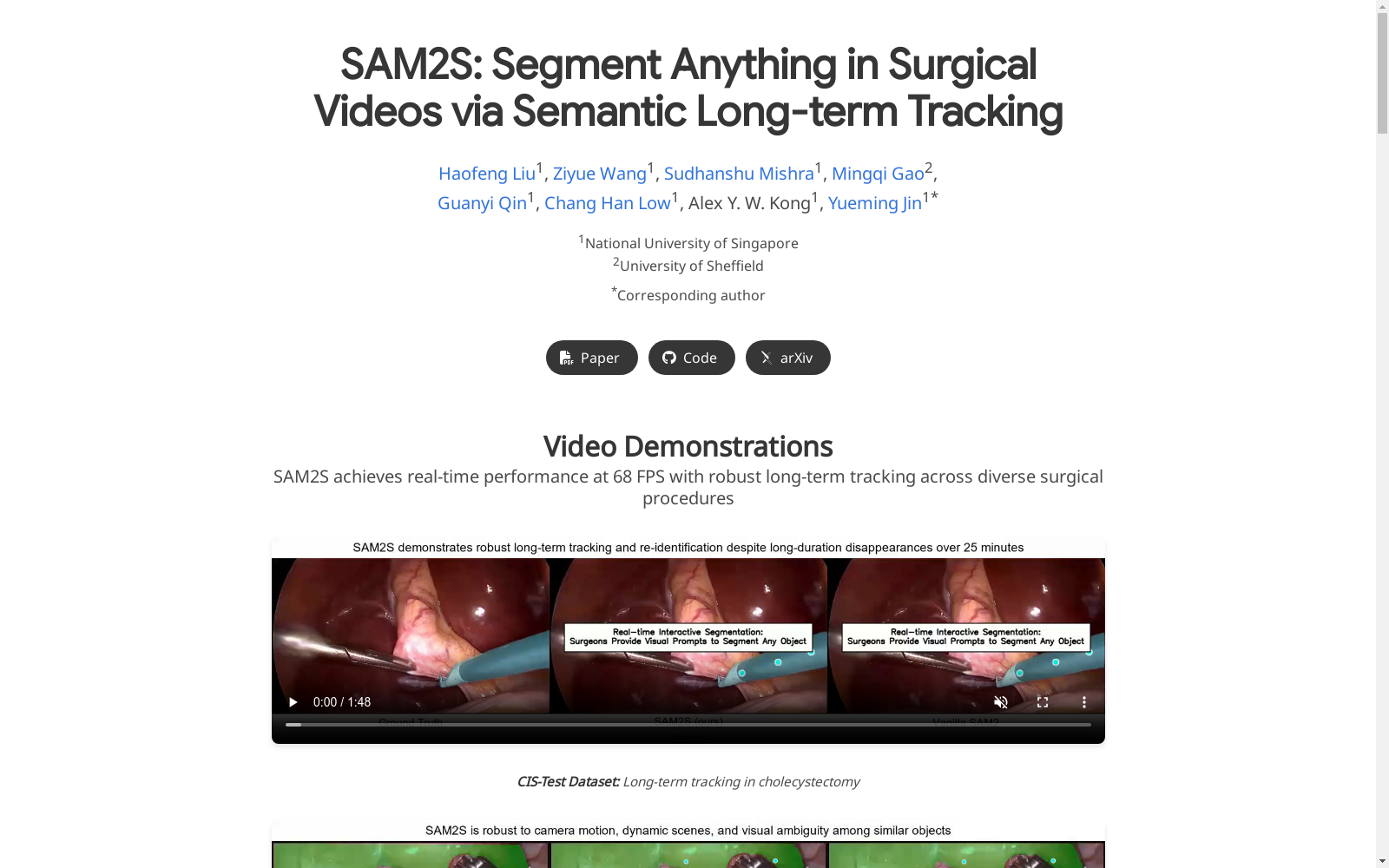
SAM2S是一个用于手术视频分割的基础模型,通过语义长期跟踪增强SAM2模型,专门针对手术场景中的交互式视频对象分割(iVOS)任务。
核心特性
- 实时性能:在A6000 GPU上达到68 FPS的实时推理速度
- 长期跟踪:在多种手术过程中实现稳健的长期跟踪
- 零样本泛化:在未见过的外科手术过程中展现强大的泛化能力
技术架构
关键创新
- DiveMem:可训练的多样化记忆机制,通过混合时间采样和基于多样性的帧选择,解决长期手术跟踪中的视角过拟合问题
- Temporal Semantic Learning (TSL):通过CLIP的视觉语言对比学习,利用手术器械的语义类别实现语义感知跟踪
- Ambiguity-Resilient Learning (ARL):通过高斯核卷积的均匀标签软化处理多源数据集中的标注不一致性
性能表现
零样本泛化
- 平均J&F(3-click):80.42
- 相比原始SAM2提升:+17.10
- 相比微调SAM2提升:+4.11
长期跟踪性能
- CIS-Test(≈30分钟):89.65 J&F(+9.56)
- RARP50(325秒):79.47 J&F(+2.96)
- Hyst-YT(329秒):87.46 J&F(+3.57)
跨过程泛化
- EndoVis17(未见过程):86.72 J&F
- EndoVis18-I(未见过程):82.37 J&F
- 在无训练数据的肾切除术上表现强劲
SA-SV基准数据集
最大的手术iVOS基准,包含实例级时空标注(masklets)
数据集规模
- 视频数量:572
- 帧数:61K
- Masklets:1.6K
- 手术过程类型:8
涵盖的手术过程
- 胆囊切除术:Endoscapes, CholecSeg8k, CholecInstanceSeg (CIS)
- 结肠镜检查:PolypGen, Kvasir-SEG, BKAI-IGH, CVC-ClinicDB
- 妇科手术:SurgAI3.8k
- 子宫切除术:AutoLaparo, ART-Net, Hyst-YT
- 肌切开术:DSAD
- 肾切除术:EndoVis17, EndoVis18
- 前列腺切除术:GraSP, RARP50
- 多过程:RoboTool
引用信息
bibtex @article{liu2025sam2s, title={SAM2S: Segment Anything in Surgical Videos via Semantic Long-term Tracking}, author={Liu, Haofeng and Wang, Ziyue and Mishra, Sudhanshu and Gao, Mingqi and Qin, Guanyi and Low, Chang Han and Kong, Alex Y. W. and Jin, Yueming}, journal={arXiv preprint arXiv:2511.16618}, year={2025} }
搜集汇总
数据集介绍
构建方式
在计算机辅助手术领域,精确的视频分割对于器械与组织定位至关重要。SA-SV数据集通过系统重构17个开源手术视频数据集构建而成,涵盖胆囊切除术、结肠镜检查等八种手术类型。构建过程采用三步精炼策略:为每个对象分配跨帧一致的实例ID以实现时序追踪,依据临床指南统一器械类别标签,并在专业外科医生监督下手动修正边界错误的掩码标注。该数据集最终整合了6.1万帧图像与1600个掩码片段,建立了当前规模最大的手术交互式视频对象分割基准。
特点
该数据集在手术视频分析领域展现出显著特性。其标注体系包含器械与组织两类对象的实例级时空注释,支持长时序追踪与零样本泛化评估。数据覆盖八种差异显著的手术流程类型,包括完全未在训练集中出现的肾切除术,为模型跨流程泛化能力验证提供了理想平台。特别设计的长时间测试子集平均时长超过300秒,最长达1807秒,远超通用视频分割基准的时序跨度,能有效评估模型在真实手术场景中的持续追踪稳定性。
使用方法
在模型开发与应用层面,SA-SV支持混合图像-视频训练策略以最大化数据效用。训练阶段采用DiveMem采样机制,通过跨视频帧的随机采样模拟大时序间隔,增强长时序依赖学习能力。评估阶段遵循“单次提示、全程追踪”协议,仅在第一帧提供点击提示,要求模型自主完成后续帧的对象追踪。该基准提供器械与组织分割的独立评估子集,并包含完全未见的手术类型,为零样本泛化能力提供严谨测试环境,推动手术视频分割技术向临床实用化迈进。
背景与挑战
背景概述
SA-SV数据集由新加坡国立大学和谢菲尔德大学的研究团队于2025年创建,旨在推动计算机辅助手术中的交互式视频对象分割技术发展。该数据集聚焦于解决手术视频中动态场景下的精确分割与长期跟踪问题,涵盖八种手术类型,包含61,000帧图像和1,600个掩码片段,是目前规模最大的手术交互式分割基准。其核心研究在于弥合自然场景与手术领域之间的语义鸿沟,通过整合多源手术数据,显著提升了模型在复杂手术环境中的泛化能力与实时性能。
当前挑战
SA-SV数据集面临两大挑战:在领域问题层面,手术视频存在显著的空间与时间特性差异,包括光照变化、血液烟雾遮挡、以及长达数小时的手术时长,导致传统分割模型难以维持长期跟踪稳定性;在构建过程中,多源数据集标注标准不一致性尤为突出,尤其组织边界模糊区域存在标注冲突,需通过人工校正与统一标准化处理,确保掩码片段的时间一致性与语义准确性。
常用场景
经典使用场景
在计算机辅助手术领域,SA-SV数据集为交互式视频对象分割研究提供了关键支撑。该数据集通过整合17个开源手术视频数据集,构建了涵盖八种手术类型的61,000帧图像与1,600个掩膜片段,其最大特色在于提供实例级别的时空标注。这些精细标注使得研究人员能够开展长期跟踪算法的系统性评估,特别是在处理持续数小时的手术视频时,能够有效验证模型在器械消失后重新识别目标的能力。
解决学术问题
SA-SV数据集有效解决了手术视频分析中的三个核心学术难题:针对自然视频与手术场景间的领域差异问题,该数据集通过多源手术数据整合提供了领域适配的训练基础;针对现有数据集缺乏时序一致性问题,其掩膜片段标注支持长期依赖建模;针对模型泛化能力不足的挑战,该数据集通过跨术式测试子集为零样本泛化研究创造了条件。这些特性使得基于该数据集开发的SAM2S模型在平均J&F指标上相较原始SAM2提升17.10个点。
衍生相关工作
基于SA-SV数据集的研究催生了系列创新工作,其中最具代表性的是SAM2S基础模型。该模型通过三个核心模块拓展了原始SAM2架构:DiveMem机制采用多样化记忆策略解决长期跟踪中的视角过拟合问题;时序语义学习模块利用视觉-语言对比学习增强器械语义理解;抗模糊学习模块通过均匀标签软化处理多源数据标注不一致性。这些创新使得SAM2S在保持68FPS实时推理速度的同时,在八个测试子集上达到80.42的平均J&F性能。
以上内容由遇见数据集搜集并总结生成


