SITE
收藏arXiv2025-05-09 更新2025-05-13 收录
下载链接:
https://wenqi-wang20.github.io/SITE-Bench.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
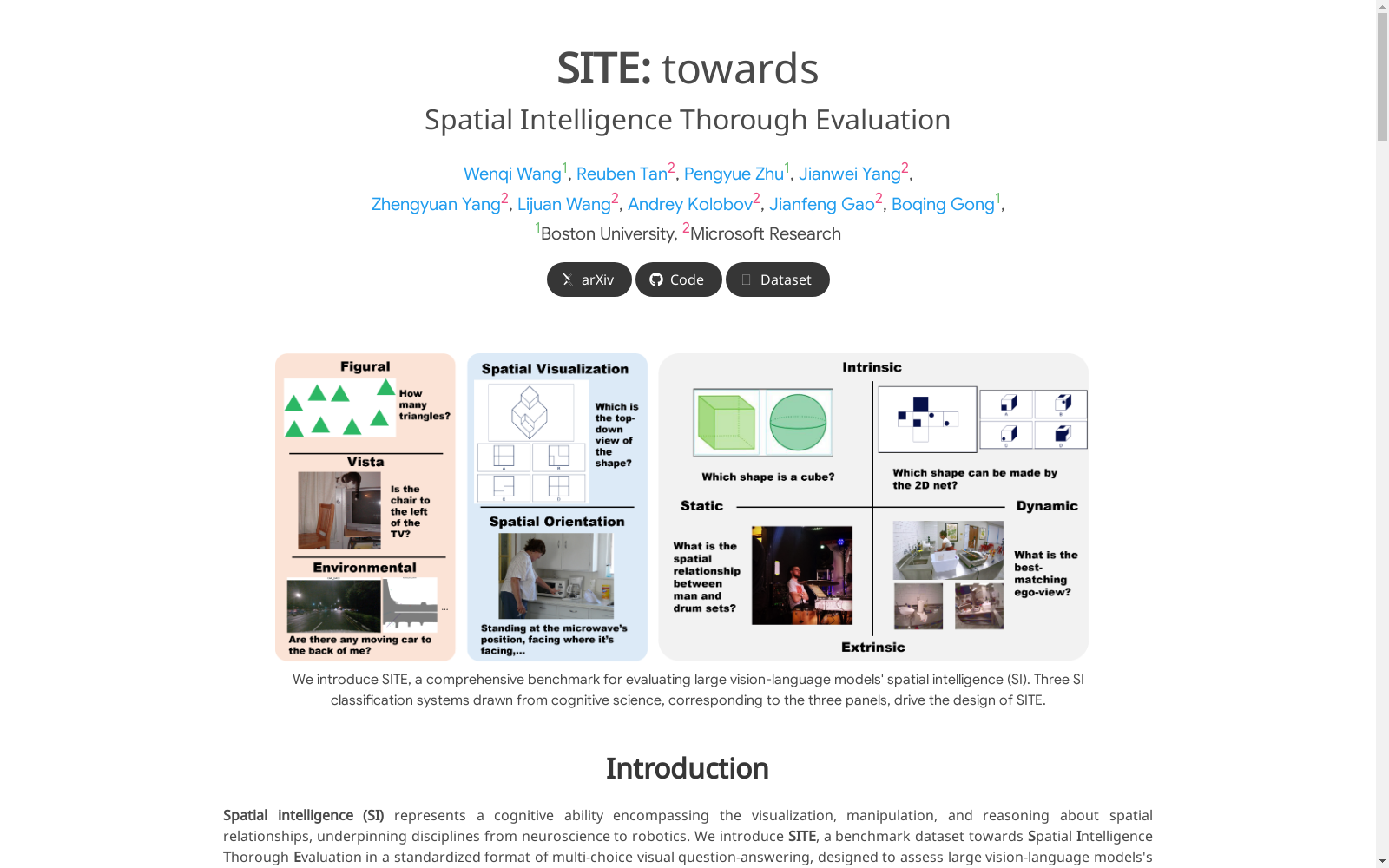
SITE数据集是一个全面的基准数据集,用于评估大型视觉语言模型的空间智能。该数据集由波士顿大学和微软研究院创建,包含来自31个计算机视觉数据集的8068个视觉语言任务。数据集内容涵盖了多种视觉模态,包括单图像、多图像和视频,以及空间智能因素,如形状到环境尺度、空间可视化和方向、内在和外在、静态和动态。数据集的创建过程采用了自下而上的调查和自上而下的策略,结合了认知科学中的三个分类系统。SITE数据集旨在解决现有基准测试的不足,提供一个更全面、更系统的空间智能评估平台。
The SITE dataset is a comprehensive benchmark dataset for evaluating the spatial intelligence of large vision-language models. Developed by Boston University and Microsoft Research, it comprises 8068 vision-language tasks sourced from 31 computer vision datasets. The dataset covers diverse visual modalities including single images, multi-image inputs, and videos, alongside key spatial intelligence factors such as shape-to-environment scale, spatial visualization and orientation, intrinsic and extrinsic attributes, as well as static and dynamic scenarios. Its construction adopts a combined bottom-up survey and top-down strategy, integrating three classification systems from cognitive science. The SITE dataset is designed to mitigate the limitations of existing benchmarks, offering a more comprehensive and systematic platform for spatial intelligence evaluation.
提供机构:
波士顿大学, 微软研究院
创建时间:
2025-05-09
搜集汇总
数据集介绍
构建方式
SITE数据集的构建采用了双向策略:自下而上的数据筛选与自上而下的认知科学分类体系相结合。研究团队系统分析了31个现有计算机视觉数据集,通过大语言模型辅助过滤得到8,068个空间推理任务,涵盖图像和视频两种模态。针对现有数据在视角转换和动态场景推理方面的不足,基于Ego-Exo4D数据集创新设计了视角关联和帧序重组两类新型任务,最终形成包含4,260个图像问答对和3,808个视频问答对的标准化多选题评测基准。
特点
该数据集具有三大核心特征:多尺度空间智能覆盖(从物体级到环境级)、多模态视觉输入(单图像/多图像/视频)、多维度认知分类(基于认知科学的三个分类体系)。特别强调对空间定向能力和动态场景推理的评估,填补了现有基准在跨视角空间推理和时空关系理解方面的空白。通过标准化多选题形式,实现了对视觉语言模型空间智能的系统化、可量化的全面评估。
使用方法
使用SITE进行评测时需采用机会调整准确率(CAA)指标,以消除选项数量差异带来的偏差。评估流程支持端到端自动化:输入多模态数据后,模型需从标准化选项中选择最佳答案,通过LLM评估模块自动评分。为保障评测全面性,建议按照六大空间类别(计数定位、三维理解等)分层抽样,重点关注模型在视角转换任务中的表现。该数据集还可用于探究空间推理能力与具身智能任务的相关性分析。
背景与挑战
背景概述
SITE(Spatial Intelligence Thorough Evaluation)是由波士顿大学和微软研究院的研究团队于2025年推出的一个综合性基准数据集,旨在评估大规模视觉语言模型(VLMs)的空间智能能力。空间智能(SI)作为认知科学中的核心概念,涵盖了对空间关系的可视化、操作和推理能力,对从神经科学到机器人学等多个领域具有深远影响。SITE通过多选视觉问答(VQA)的标准化形式,整合了多种视觉模态(单图像、多图像和视频)和空间智能因素(从图形到环境尺度、空间可视化与定向、静态与动态等),填补了现有基准在系统性评估空间智能方面的空白。该数据集的构建结合了自下而上的31个现有数据集调查和自上而下的认知科学分类系统,不仅重新组织了现有任务,还引入了视角转换和动态场景两类新型任务,推动了视觉语言模型在空间推理能力上的研究进展。
当前挑战
SITE面临的挑战主要体现在两个方面:领域问题的复杂性和数据构建的技术难度。在领域问题方面,空间智能本身的多维度特性(如跨尺度推理、视角转换和动态场景理解)对模型的几何理解、时空推理和跨模态对齐能力提出了极高要求,现有模型在空间定向任务上的表现显著落后于人类专家。在数据构建方面,挑战包括:1)从异构数据源(22个图像数据集和8个视频数据集)中提取和标准化8068个空间推理任务的工程复杂度;2)通过认知科学理论(如Hegarty的三尺度分类和Uttal的2x2框架)指导任务设计时,需平衡学科严谨性与计算机视觉可行性;3)新型任务(如基于Ego-Exo4D的视角关联和帧排序任务)的标注需要同步处理多视角视频流并确保时空一致性,这对标注流程和质量控制提出了特殊要求。
常用场景
经典使用场景
SITE数据集作为评估大规模视觉语言模型(VLMs)空间智能(Spatial Intelligence, SI)的综合基准,其经典使用场景主要体现在多模态视觉问答(VQA)任务中。通过结合自然图像、合成图像、多视角图像和视频数据,SITE能够系统地测试模型在不同空间尺度(figural、vista、environmental)和动态场景下的空间推理能力。例如,模型需完成视角转换任务(如将自我中心视角与外部视角关联)或动态场景中的时序推理(如视频帧重排序),从而全面评估其空间可视化、空间定向及动态关系理解能力。
实际应用
在机器人导航、增强现实(AR)和自动驾驶等实际场景中,SITE的评估范式可直接迁移。例如,机器人需通过多视角空间推理规划路径(如LIBERO-Spatial实验中VLMs空间能力与机械臂操作成功率呈0.902相关性);AR系统依赖动态场景理解实现虚实交互;自动驾驶系统则需处理环境尺度下的空间关系判断。SITE的任务设计(如Ego-Exo帧排序)模拟了这些场景的核心挑战,为工业界优化模型提供了针对性测试标准。
衍生相关工作
SITE的发布催生了多项围绕空间智能提升的研究:1)3DSRBench等工作扩展了三维空间推理评估维度;2)Qwen2.5-VL等模型通过引入视频 grounding 数据改进时序推理;3)SAT等数据集借鉴其认知科学分类体系设计新任务。此外,Blink、VSIBench等基准与SITE形成互补,共同构建了从静态到动态、室内到开放环境的完整SI评估生态。
以上内容由遇见数据集搜集并总结生成


