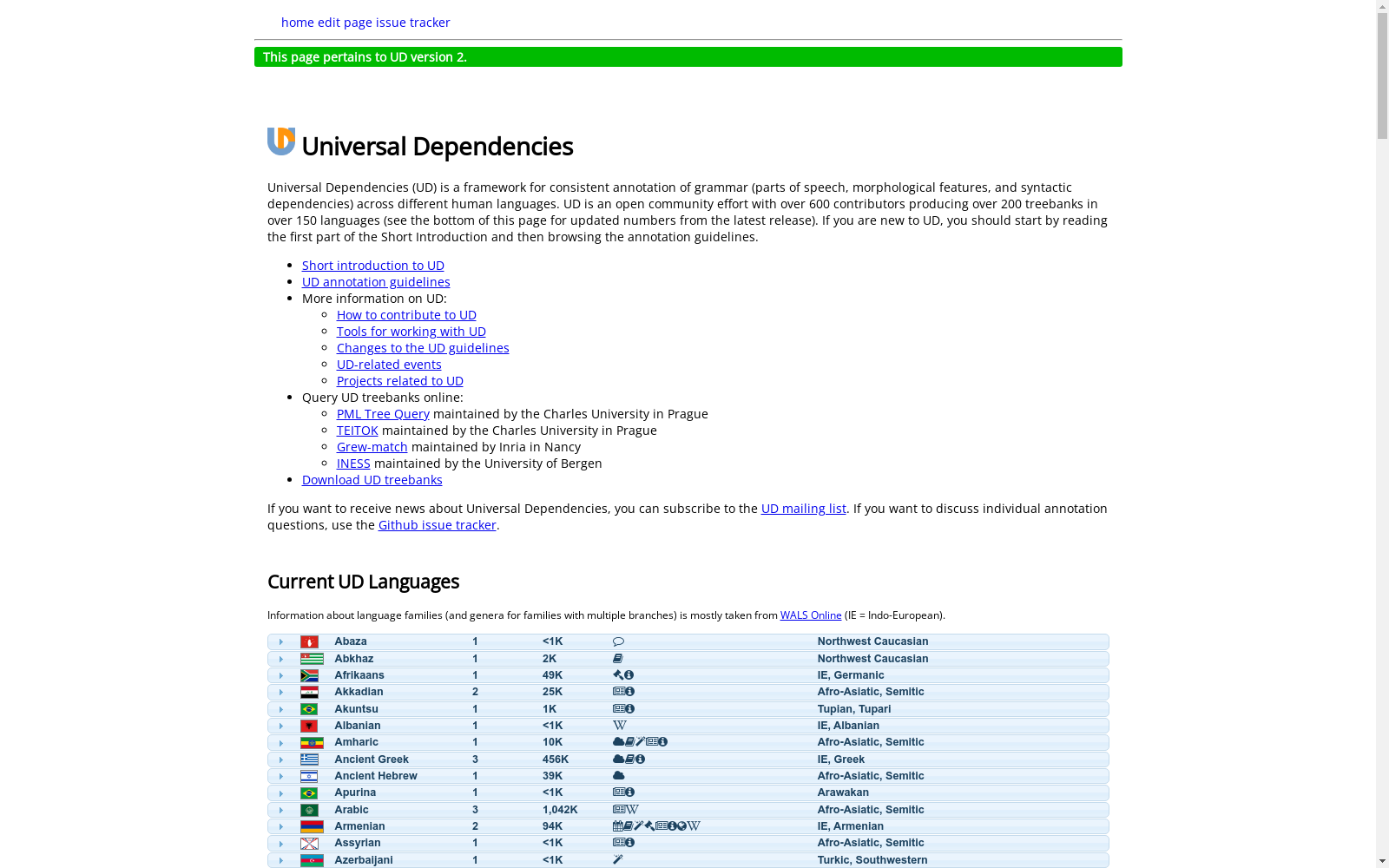
Universal Dependencies (UD)
收藏universaldependencies.org2024-11-02 收录
下载链接:
https://universaldependencies.org/
下载链接
链接失效反馈官方服务:
资源简介:
Universal Dependencies (UD) 是一个跨语言的语法标注框架,旨在提供一致的语法标注体系,适用于多种语言。该数据集包含了多种语言的树库,每个树库都按照UD的标注标准进行标注,涵盖了词性标注、句法依存关系等信息。
Universal Dependencies (UD) is a cross-linguistic grammatical annotation framework that aims to provide a consistent grammatical annotation system applicable to multiple languages. This dataset includes treebanks of various languages, where each treebank is annotated in accordance with UD annotation standards and covers information such as part-of-speech tagging and syntactic dependency relations.
提供机构:
universaldependencies.org
搜集汇总
数据集介绍
构建方式
Universal Dependencies (UD) 数据集的构建基于跨语言的语法和语义标注标准,旨在为多种语言提供一致的依存句法分析框架。该数据集通过众包和专家标注相结合的方式,确保了标注质量的高标准。构建过程中,首先对原始文本进行预处理,然后由语言学家和计算语言学专家进行细致的依存关系标注,最终形成一个多语言、多领域的语料库。
特点
Universal Dependencies (UD) 数据集的显著特点在于其跨语言的一致性和广泛的应用领域。该数据集涵盖了超过100种语言,每种语言都有详细的依存句法标注,确保了语言间的可比性和可迁移性。此外,UD数据集还支持多种自然语言处理任务,如机器翻译、信息抽取和文本生成,使其成为研究者和开发者的重要资源。
使用方法
使用Universal Dependencies (UD) 数据集时,研究者可以利用其丰富的标注信息进行依存句法分析模型的训练和评估。开发者可以通过API或直接下载数据集文件,将其集成到自然语言处理系统中。此外,UD数据集还提供了详细的文档和工具,帮助用户理解和处理标注数据,从而提高模型的准确性和鲁棒性。
背景与挑战
背景概述
Universal Dependencies (UD) 数据集是一个跨语言的语法标注数据集,旨在为自然语言处理领域提供一个统一的标注框架。该数据集由众多研究人员和机构共同创建,首次发布于2014年,其核心研究问题是如何在不同语言间实现一致且高效的语法标注。UD数据集的推出极大地推动了跨语言自然语言处理技术的发展,为机器翻译、语义分析等应用提供了坚实的基础。
当前挑战
尽管UD数据集在跨语言语法标注方面取得了显著进展,但其构建过程中仍面临诸多挑战。首先,不同语言的语法结构差异巨大,如何在统一框架下实现高质量的标注是一个复杂问题。其次,数据集的维护和更新需要持续投入,以应对语言变化和新语言的加入。此外,跨语言一致性的保持和验证也是一个持续的挑战,确保标注结果在不同语言间具有可比性和可靠性。
发展历史
创建时间与更新
Universal Dependencies (UD) 数据集的创建始于2014年,由一组国际研究者共同发起。自那时起,该数据集经历了多次重大更新,最近一次主要更新发生在2021年,以确保其与最新的语言学理论和技术进步保持同步。
重要里程碑
UD数据集的一个重要里程碑是其在2016年发布的1.2版本,这一版本标志着数据集从最初的实验阶段进入了更为成熟的应用阶段。随后,2018年的2.0版本引入了更多语言的支持,并改进了标注的一致性和准确性。2021年的2.8版本则进一步扩展了语言覆盖范围,并引入了新的标注规范,使其在自然语言处理领域的影响力显著提升。
当前发展情况
当前,Universal Dependencies (UD) 数据集已成为自然语言处理领域中不可或缺的资源。它不仅支持多种语言的语法和句法分析,还为机器翻译、信息抽取和文本理解等任务提供了坚实的基础。随着深度学习技术的快速发展,UD数据集也在不断更新和优化,以适应新的研究需求和技术挑战。其持续的发展和改进,为推动语言学研究和自然语言处理技术的进步做出了重要贡献。
发展历程
- Universal Dependencies (UD) 项目正式启动,旨在创建一个跨语言的依存语法标注体系。
- 发布了首个版本的 Universal Dependencies 数据集,包含多种语言的语料库。
- UD 数据集进行了首次大规模更新,增加了更多语言的支持,并改进了标注规范。
- 发布了 UD v2.0,引入了新的标注层级和更详细的语法信息,提升了数据集的实用性。
- UD v2.3 发布,进一步扩展了语言覆盖范围,并优化了标注一致性。
- UD v2.5 发布,引入了更多语言的语料库,并改进了跨语言的标注一致性。
- UD v2.7 发布,继续扩展语言覆盖,并引入了新的标注工具和资源。
- UD v2.8 发布,进一步优化了标注规范,并增加了对低资源语言的支持。
- UD v2.10 发布,继续扩展语言覆盖,并改进了数据集的质量和一致性。
常用场景
经典使用场景
在自然语言处理领域,Universal Dependencies (UD) 数据集以其丰富的语法和句法标注而著称。该数据集广泛应用于句法分析和依存关系解析任务中,为研究人员提供了一个标准化的多语言资源。通过UD数据集,研究者能够训练和评估各种句法分析模型,从而提升自然语言处理系统的性能。
解决学术问题
UD数据集解决了多语言句法标注不一致的问题,为跨语言研究提供了统一的基准。其标注体系涵盖了多种语言的语法结构,使得不同语言的句法分析结果具有可比性。这一数据集的出现,极大地推动了跨语言句法分析技术的发展,为多语言自然语言处理研究提供了坚实的基础。
衍生相关工作
基于UD数据集,研究者们开发了多种句法分析工具和模型,如Stanford CoreNLP和SpaCy等。这些工具不仅提升了句法分析的效率,还促进了相关领域的研究进展。此外,UD数据集还激发了大量关于多语言句法标注和跨语言句法迁移的研究,推动了自然语言处理技术的不断创新。
以上内容由遇见数据集搜集并总结生成


